kafka接收消费消息
三 kafka接收消费消息本节教程在window下演示,如果是在linux上学习的同学,可以将命令的前缀进行替换即可,比如 window 下的 命令前缀 bin\windows\kafka-topics.bat ,则linux下的命令前缀为 bin\kafka-topics.sh;3.1 创建topickafka生产消息使用producer生产者,其核心组件服务器为broker, 消费消息使用co
三 kafka接收消费消息
本节教程在window下演示,如果是在linux上学习的同学,可以将命令的前缀进行替换即可,比如 window 下的 命令前缀 bin\windows\kafka-topics.bat ,则linux下的命令前缀为 bin\kafka-topics.sh;
3.1 创建topic
kafka生产消息使用producer生产者,其核心组件服务器为broker, 消费消息使用comsumer消费者, 消息接收需要使用到 topic; topic中又有分区和副本;
创建一个名为test的topic,并且指定分区为1,副本为1;
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --topic test --partitions 1 --replication-factor 1
使用如下查看topic描述
bin\windows\kafka-topics.bat --describe --zookeeper localhost:2181 --topic test
其结果如下,分区为1,副本为1,名称为test
Topic: test TopicId: hkPExRf8T72y2FFNEOiFnQ PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
3.2 发生消息
创建一个生产者,向topic test 发送消息
bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
回车键后发送如下消息
welcome to my site that is zszxz.com

3.3 消费消息
创建一个消费者,向topic test获取消息
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
获取内容如下

四 producer
4.1 producer工作流
kafaka 的 producer 负责的职能就是向 kafka 写入数据;kafka的每个producer 都是独立工作,producer 实例之间没有任何关系;kafka 在向topic 发送消息的时候, 如果消息指定了 key , kafka会计算key的hash值将消息存入不同的分区提高吞吐量,如果消息没有指定Key, kafka会将消息进行轮询存储到分区!确认分区后,kafka 的 producer 会去寻找分区对应 的 leader 也只有leader 能够响应client发送过来的请求,而另一个副本follower和leader 保持同步;
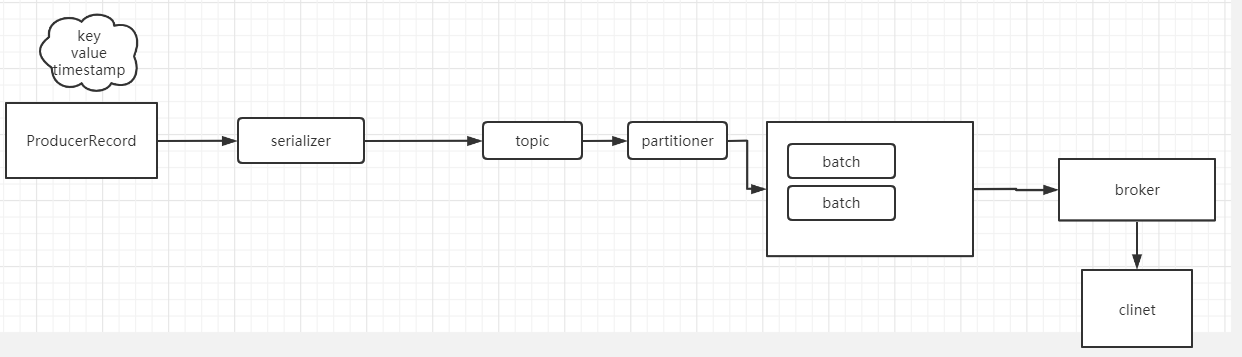
4.2 producer发送消息示例
引入 client 依赖, producer 和 cosumer 相对 kafka 都是 客户端,所以都是引入客户端依赖;
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
发送示例消息示例
public static void main(String[] args) {
Properties properties = new Properties();
// 指定server地址 bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
// 指定client ID
properties.put(ProducerConfig.CLIENT_ID_CONFIG,"test-producer");
// key序列化配置类型为String key.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// value序列化配置类型为String value.serializer
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 创建生产者
KafkaProducer<String,String> producer=new KafkaProducer(properties);
// 消息
String msg = "welcome to zszxz.com";
// 主题
String topic = "test";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, msg);
producer.send(record);
producer.close();
}
- 首先需要构建一个 java.util.Properties对象 指定
bootstrap.servers,key.serializer,value.serializer, 这三个属性必须指定; - 其次构造 KafkaProducer 实例;
- 然后 使用 ProducerRecord构建消息对象 用于将消息发送到分区;
- 最后调用 KafkaProducer 的 send 方法发送 ProducerRecord,并且关闭KafkaProducer ;
- bootstrap.servers 指定了一组host:port , 用于kafka 连接服务器;其可以指定多组IP和端口,如 domain1:port1,domain2:port2;
- key.serializer 表示发送消息的格式都是字节数组,这些字节数组必须使用序列化才能发送到broker;
StringSerializer.class.getName()表示的序列化器为org.apache.kafka.common.serialization.StringDeserializer; - value.serializer 是将消息内容序列化至broker;
在创建 KafkaProducer 也可以指定 key 和value的序列化器;
public KafkaProducer(Properties properties, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
this(Utils.propsToMap(properties), keySerializer, valueSerializer);
}
异步发送
KafkaProducer 的 send 方法 实现了 Callback回调, 并且提供了Future对象用于获取消息发送的结果;
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return this.send(record, (Callback)null);
}
同步发送
同步发送会使用 Future.get() 方法 实现无限等待结果;如果发送消息失败可以进行异常捕获进行处理
producer.send(record).get();
消息异常捕获
try {
producer.send(record).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
也可以进行回调异常处理,实现重试机制等
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e==null){
System.out.println("发送消息成功");
}else {
// 重试或者其它处理
}
}
}).get();
4.3 producer 主要参数说明
除了 bootstrap.servers, key.serializer, value.serializer 三个必须指定的参数之外,还有一些重要的参数;
- acks 参数用于控制kafka消息的持久化,只要消息被写入 kafka ,消息就会被视为不会丢失!ack 有三个取值; 0 表示 producer 不会确认消息发送给broker 是否成功; 1 表示 leader 接收消息确认,将消息写入本地日志; -1 即 all, 需要leader 和 follower 共同确认;三种情况下 0的吞吐量最高,消息持久化最差,1 其次,消息持久化适中; all 吞吐量最差, 消息持久化最好;
通常我们需要将 acks 设置为 1
// 设置acks 应答
properties.put(ProducerConfig.ACKS_CONFIG,"1");
- buffer.memory: 缓存消息的缓冲区大小,默认单位为32MB(即数字33554432);
// 设置缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,"33554432");
- compression.type: 对消息进行压缩,默认情况下为none; 在网络通信中对消息进行压缩通常都是能提高吞吐量,因此kafka在发送消息时很有必要进行消息压缩;kafka 支持 3种 压缩算法,不排除还有其它算法,通常是GZIP,LZ4 和Snappy; 在kafka 种使用LZ4算法进行压缩更佳!
// 设置压缩
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");
- retries : 重试次数,即消息发送失败后进行重发,虽然callback 也有这个机制,但还不如交给kafka自己重发!按道理其默认值为0 , 但我控制台显示的默认值确是
retries = 2147483647, 保险起见,我们需要自己设置一般情况下为 3~5次为佳;
// 重试次数
properties.put(ProducerConfig.RETRIES_CONFIG,"3");
- batch.size : 表示批次,producer 在发送消息的时候并非直接发送给topic, kafka会将消息存到 batch, 当batch 满了以后,或者达到最大空闲时间才会将消息发送给topic; 其默认值为 16384 即 16KB ,实际生产环境中应该设置合理值;
// 设置 batch
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"16384");
- linger.ms:表示是否延迟发送,默认值为0立即发送;所以我们在使用默认参数的时候及时batch没有满也会发送,就是这个影响!
// 设置延迟发送
properties.put(ProducerConfig.LINGER_MS_CONFIG,"200");
- max.request.size : 发送请求的大小,即能发送多大的消息;这个值默认是 1048576 ,复杂业务情况下,这值实在太小;
// 设置消息大小
properties.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG,"1048576");
- request.timeout.ms: 响应超时时间,即发送给broker 后 broker 响应的时间,默认值为 30000 即30秒,如果超过30秒,则会认为请求超时;如果应用负荷很大,则需要调整大小为适当值;
// 设置超时响应时间
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,"50000");
4.4自定义分区
kafka 接收到消息后,默认会通过Key值进行计算出hash 值,然后将消息发送到分区,如果未指定分区,则会进行轮询发送以保证消息在分区上分布比较均衡;如果想自定义分区策略则需要实现 Partitioner 接口;
/**
* @author lsc
* <p> </p>
*/
public class ZszxzPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
主要的参数
- topic 主题
- key 消息的key
- keyBytes: 消息key的字节数组,或者为null;
- value:消息的值
- valueBytes: 消息值的字节数组,或者为nul;
- cluster:集群
自定义分区示例
/**
* @author lsc
* <p> </p>
*/
public class ZszxzPartitioner implements Partitioner {
private Random random;
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取集群中的分区
List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic(topic);
// 分区数量
int size = partitionInfos.size();
int partitionNum = 0;
if (key==null){
// key 没有设置, 随机分区
partitionNum = random.nextInt(size);
}else {
// 使用hash值计算分区
partitionNum = Math.abs((key.hashCode())) % size;
}
System.out.println("分区:"+partitionNum);
return partitionNum;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
random = new Random();
}
}
在发送消息的时候配置上分区属性即可
// 自定义分区
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.zszxz.kafka.partition.ZszxzPartitioner");
4.5 kafka序列化
kafka 序列化和反序列化,根据不同的数据类型进行配置即可
- byte[]:org.apache.kafka.common.serialization.ByteArraySerializer
- ByteBuffer: org.apache.kafka.common.serialization.ByteBufferSerializer
- Interger: org.apache.kafka.common.serialization.IntegerSerializer
- Short:org.apache.kafka.common.serialization.ShortSerializer
- Long:org.apache.kafka.common.serialization.LongSerializer
- Double:org.apache.kafka.common.serialization.DoubleSerializer
- String: org.apache.kafka.common.serialization.StringSerializer
之前的示例代码使用了简化方式,回顾下,否则要替换为全类名
// key序列化配置类型为String
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// value序列化配置类型为String
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
4.6 producer多线程
producer 中 KafkaProducer 是线程共享的一个变量,可以作为成员变量使用,并且线程安全;每个线程中都维护着 一个ProducerRecord 用于存储消息;
示例代码如下
/**
* @author lsc
* <p> </p>
*/
public class ProducerThread extends Thread{
private final KafkaProducer<String,String> producer;
private final String topic;
public ProducerThread(String topic) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG,"test-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
producer=new KafkaProducer<String, String>(properties);
this.topic = topic;
}
@Override
public void run() {
int num=0;
while(num<30) {
String msg="hello this message from producer:"+num;
try {
producer.send(new ProducerRecord<String, String>(topic,msg)).get();
TimeUnit.SECONDS.sleep(2);
num++;
System.out.println(num);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new ProducerThread("test").start();
}
}
五 consumer
5.1 消费者
消费者就是从topic获取消息;但是kafka的consumer 还有一些特性; consumer 被归类到 consumer group 底下;每个group 底下可能有多个consumer,;
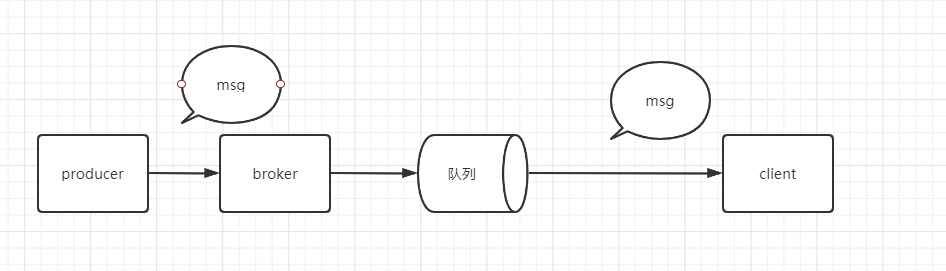
由此引申出2 个模型
队列模型
发布订阅模型
如图所示2 个client 就组成一个group;每个gruop 都有一个group.id当作唯一标识;
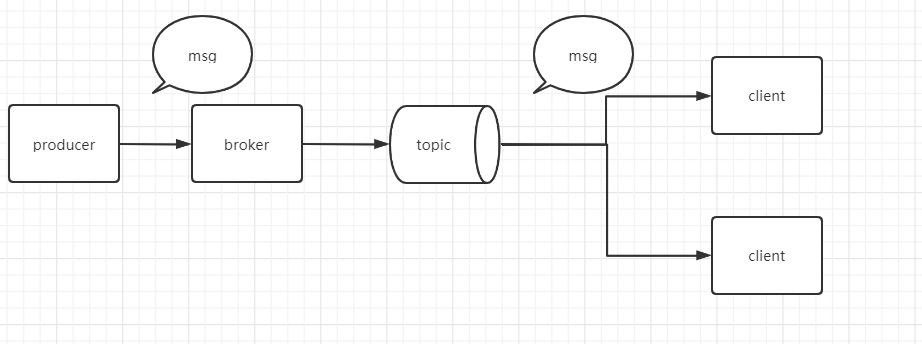
消费者如果宕机会从宕机的位置开始发送消息,其识别位置就是使用offset实现;consumer会定期向kafka发送offset实现位移提交。Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为 __consumer_offsets
5.2 消费者接收消息示例
/**
* @author lsc
* <p> </p>
*/
public class ConsumerTest {
public static void main(String[] args) {
Properties properties=new Properties();
// 设置地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
// 设置group id
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test-consumer");
// 设置 offset自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交间隔时间
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 设置value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 设置 key
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 对于当前groupid来说,消息的offset从最早的消息开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 消费者实例
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
// 主题
String topic = "test";
// 订阅
kafkaConsumer.subscribe(Arrays.asList(topic));
try{
while (true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(30));
records.forEach(record -> {
System.out.println("key:"+record.key()+" value:"+record.value()+" "+record.offset());
});
}
}finally {
kafkaConsumer.close();
}
}
}
必须指定参数 bootstrap.servers, value.deserializer, key.deserializer, group.id;其中bootstrap.servers 也可以指定多个值 ip1:port1,ip2:port2; group.id 为消费组id,通常与业务名称挂钩; value.deserializer和 key.deserializer 分别对 producer 发送的消息进行反序列化;
- 首先创建Properties对象,然后组装参数;
- 其次KafkaConsumer 消费者实例订阅主题test
- 最后 通过kafkaConsumer获取ConsumerRecords遍历数据;
KafkaConsumer 对象构造器如下所示
public KafkaConsumer(Properties properties) {
this((Properties)properties, (Deserializer)null, (Deserializer)null);
}
还可以指定key,value 的反序列化
public KafkaConsumer(Properties properties, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
this(Utils.propsToMap(properties), keyDeserializer, valueDeserializer);
}
属性参数不一定是写Properties,也可以写 map;
public KafkaConsumer(Map<String, Object> configs, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
this(new ConsumerConfig(ConsumerConfig.appendDeserializerToConfig(configs, keyDeserializer, valueDeserializer)), keyDeserializer, valueDeserializer);
}
kafkaConsumer.subscribe(Arrays.asList(topic)); 为订阅主题,也可以订阅多个主题
kafkaConsumer.subscribe(Arrays.asList("topic1","topic2"));
kafkaConsumer.poll(Duration.ofSeconds(1)); 是从 topic 中获取消息;1表示超时设置,如果未拿到数据,在1秒内会进行阻塞,直到拿到数据;
5.3 consumer主要参数
- session.timeout.ms: consumer 奔溃响应时间;即如果发生宕机,kafka会在规定的时间内检测到consumer 奔溃;其默认值为1000即10秒;
- max.poll.interval.ms: consumer 处理逻辑的最大时间,默认值为 300000;
- auto.offset.reset: 指定位移信息,kafka会从位移位置开始读取;其有三个取值,earliest,从最早开始消费;latest从最新开始消费;none新的消费者加入以后,由于之前不存在offset,则会直接抛出异常;
- enable.auto.commit: 自动提交位移;也可以通过consumer.commitSync()的方式实现手动提交;
- fetch.max.bytes: 抓取的最大字节数,默认值为52428800;
5.4 kafka反序列化
- org.apache.kafka.common.serialization.ByteArrayDeserializer
- org.apache.kafka.common.serialization.ByteBufferDeserializer
- org.apache.kafka.common.serialization.IntegerDeserializer
- org.apache.kafka.common.serialization.ShortDeserializer
- org.apache.kafka.common.serialization.LongDeserializer
- org.apache.kafka.common.serialization.DoubleDeserializer
- org.apache.kafka.common.serialization.StringDeserializer
回顾下,我们使用了类名的获取方式实现全类名字符串
// 设置value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 设置 key
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
5.5 rebalance
consumer group 是一组 rebalance 协议; 其规定了comsuer group 如何订阅topic 分区 达到平衡的目的;Kafka 有三种分配策略: RoundRobin, Range,Sticky;
- range分配策略会将每个topic的分区按照字母顺序排列,将分区划分成区段依次分配给consumer;
- RoundRobin 分配策略 会将所有的topic 按照顺序展开,然后通过轮询的方式分配给consumer;
- Sticky分区策略是从0.11版本才开始引入的,它主要有两个目的;分区的分配要尽可能的均匀,分配给消费者者的主题分区数最多相差一个;分区的分配要尽可能与上次分配的保持相同
5.6 consumer多线程示例
简单的继承 Thread类
/**
* @author lsc
* <p> </p>
*/
public class ConsumerThread extends Thread{
private final KafkaConsumer<String,String> consumer;
public ConsumerThread(String topic){
Properties properties=new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test-consumer");
// 设置 offset自动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交间隔时间
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 设置
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
// key序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// value序列化
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// 对于当前groupid来说,消息的offset从最早的消息开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
consumer= new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(topic));
}
@Override
public void run() {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
System.out.println("key:"+record.key() + " value:" + record.value() + "offset:" + record.offset());
});
}
}
public static void main(String[] args) {
new ConsumerThread("test").start();
}
}
kafka教程

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)