flink-kafka-connector设置开始和结束消费位置
自定义flink-kafka-connector,目前flink,DataStream API支持设定消费结束偏移位置,但Table API并不支持该功能,因此只能自定义kafka连接器,可在批任务的情况下,设定开始位置和结束位置。
自定义flink-kafka-connector
背景:消费特定开始和结束位置的kafka数据,需求是执行flink任务消费完特定位置数据后,任务自行停止。但批任务并不支持消费kafka数据,而流任务不会自行停止,因此需要自定义kafka连接器。flink1.14版本中,DataStream Connectors 有一个属性setBounded,可以设定消费的结束位置,但Table API目前并不支持设定结束消费位置,正好可以模仿着DataStream修改源代码。
本文主要参考这篇文章,这篇文章给我很大的帮助,在此基础对一些细节地方进行了修改,其中修改了两处比较关键的地方,最终满足了需求。首先是修改流批任务判断条件,保证在批任务情况下,消费到kafka中的数据,其次保证任务消费到指定位置后任务停止,最后是进行打包测试,打包过程中注意格式,网络也会有一定的影响,后续也会将jar包放到后面,可直接使用。
flink-connector-kafka_2.11-1.14.4.jar
主要的修改地方
1,批模式处理流数据
在KafkaSourceBuilder中设置有限数据标识Boundedness.BOUNDED,保证能做批任务情况下处理kfka流数据,这个标识也可在其他位置设置,根据自己需要进行设置。
2,设置结束偏移位置,仿照开始偏移位置设置结束偏移位置
在KafkaSourceBuilder新建setEndOffsets方法并给stoppingOffsetsInitializer属性赋值
3,设置结束偏移位置的方式
在KafkaConnectorOptionsUtil里面,仿照开始getStartupOptions方法新建getEndupOptions方法,针对特定偏移位置进行针对性修改,同样还是仿照开始位置进行设置,具体修改请参照一下内容。
注意事项;
代码格式需要注意,换行,空格都不能多,不然打包的时候无法通过,还有就是import的时候也要注意,避免IDEA自动导入的问题,不然打包也会失败。
操作步骤如下
1, File->settings->Editor->Code Style->java->imports
2, Class count to use import with '’ 值为100
3, Names count to use static import with ‘*’ 值为100
之后就可以顺利的将自定义jar包打包成功,之后直接替换本地项目中的flink-kafka-connector.jar,注意名字要完成匹配,这样后续代码运行,使用的就是修改后的jar包。
具体修改如下:
下载flink源代码(最好通过中文github网站进行下载,比较快),有7个需要修改的地方:
1,KafkaSourceBuilder
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/KafkaSourceBuilder.java
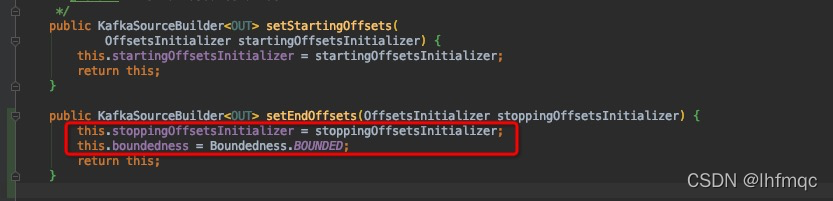
public KafkaSourceBuilder<OUT> setEndOffsets(OffsetsInitializer stoppingOffsetsInitializer) { //这个地方设置结束偏移位置,是整个修改的核心
this.stoppingOffsetsInitializer = stoppingOffsetsInitializer;
this.boundedness = Boundedness.BOUNDED;//设置边界,保证批任务处理kafka(流)数据
return this;
}
仿照开始偏移位置,设置结束偏移位置,这里之所以设置 this.boundedness = Boundedness.BOUNDED,是因为批任务并不支持消费kafka(流)类型数据,不设置会报如下错误:
Querying an unbounded table '%s' in batch mode is not allowed. "
+ "The table source is unbounded.
也可在其他方式设置该属性,这个根据自己的需求可自行调整。
2,EndupMode
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/config/EndupMode.java
新增一个EndupMode配置文件,也是仿照开始的配置文件编写
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.streaming.connectors.kafka.config;
import org.apache.flink.annotation.Internal;
import org.apache.flink.streaming.connectors.kafka.internals.KafkaTopicPartitionStateSentinel;
/** End modes for the Kafka Consumer. */
@Internal
public enum EndupMode {
/** End from committed offsets in ZK / Kafka brokers of a specific consumer group (default). */
GROUP_OFFSETS(KafkaTopicPartitionStateSentinel.GROUP_OFFSET),
/** End from the latest offset. */
LATEST(KafkaTopicPartitionStateSentinel.LATEST_OFFSET),
/**
* Start from user-supplied timestamp for each partition. Since this mode will have specific
* offsets to start with, we do not need a sentinel value; using Long.MIN_VALUE as a
* placeholder.
*/
TIMESTAMP(Long.MIN_VALUE),
/**
* Start from user-supplied specific offsets for each partition. Since this mode will have
* specific offsets to start with, we do not need a sentinel value; using Long.MIN_VALUE as a
* placeholder.
*/
SPECIFIC_OFFSETS(Long.MIN_VALUE);
/** The sentinel offset value corresponding to this startup mode. */
private long stateSentinel;
EndupMode(long stateSentinel) {
this.stateSentinel = stateSentinel;
}
}
3, KafkaConnectorOptions
设置结束消费kafka的相关参数
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/table/KafkaConnectorOptions.java
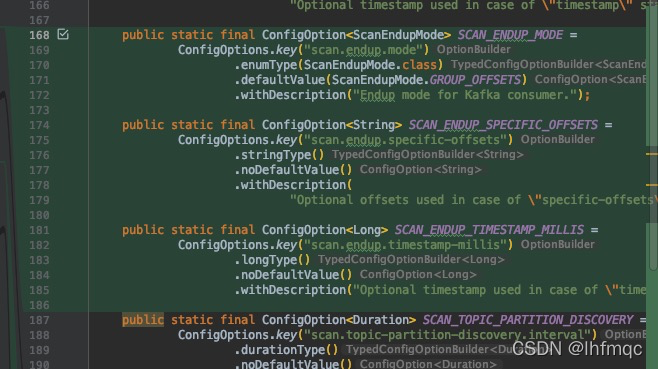
仿照开始配置编写结束配置,这里也很重要,后续调用的方式可根据此处编写。
| 参数名 | 参数值 |
|---|---|
| scan.startup.mode | 可选值:‘earliest-offset’, ‘latest-offset’, ‘group-offsets’, ‘timestamp’ and ‘specific-offsets’ |
| scan.startup.specific-offsets | 指定每个分区的偏移量,比如:‘partition:0,offset:42;partition:1,offset:300’ |
| scan.startup.timestamp-millis | 直接指定开始时间戳,long类型 |
| scan.endup.mode | 可选值:‘latest-offset’, ‘group-offsets’, ‘timestamp’ and ‘specific-offsets’ |
| scan.endup.specific-offsets | 指定每个分区的偏移量,比如:‘partition:0,offset:42;partition:1,offset:300’ |
| scan.sendup.timestamp-millis | 直接指定结束时间戳,long类型 |
public static final ConfigOption<ScanEndupMode> SCAN_ENDUP_MODE =
ConfigOptions.key("scan.endup.mode")
.enumType(ScanEndupMode.class)
.defaultValue(ScanEndupMode.GROUP_OFFSETS)
.withDescription("Endup mode for Kafka consumer.");
public static final ConfigOption<String> SCAN_ENDUP_SPECIFIC_OFFSETS =
ConfigOptions.key("scan.endup.specific-offsets")
.stringType()
.noDefaultValue()
.withDescription(
"Optional offsets used in case of \"specific-offsets\" endup mode");
public static final ConfigOption<Long> SCAN_ENDUP_TIMESTAMP_MILLIS =
ConfigOptions.key("scan.endup.timestamp-millis")
.longType()
.noDefaultValue()
.withDescription("Optional timestamp used in case of \"timestamp\" endup mode");
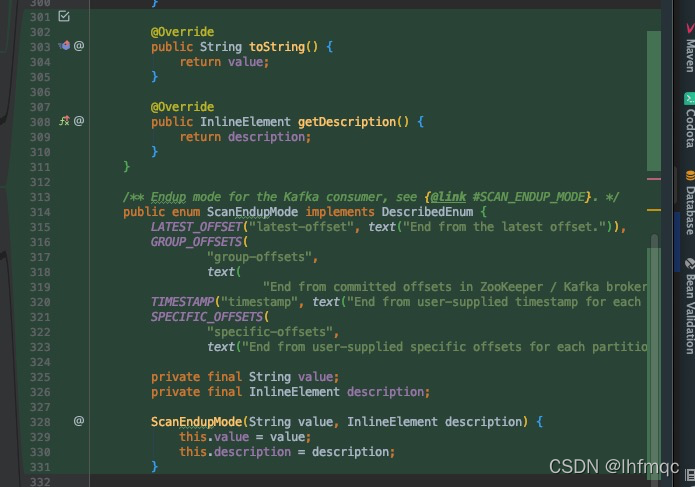
/** Endup mode for the Kafka consumer, see {@link #SCAN_ENDUP_MODE}. */
public enum ScanEndupMode implements DescribedEnum {
LATEST_OFFSET("latest-offset", text("End from the latest offset.")),
GROUP_OFFSETS(
"group-offsets",
text(
"End from committed offsets in ZooKeeper / Kafka brokers of a specific consumer group.")),
TIMESTAMP("timestamp", text("End from user-supplied timestamp for each partition.")),
SPECIFIC_OFFSETS(
"specific-offsets",
text("End from user-supplied specific offsets for each partition."));
private final String value;
private final InlineElement description;
ScanEndupMode(String value, InlineElement description) {
this.value = value;
this.description = description;
}
@Override
public String toString() {
return value;
}
@Override
public InlineElement getDescription() {
return description;
}
}
4,KafkaConnectorOptionsUtil
kafka结束消费位置,根据参数创建相关偏移量对象
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/table/KafkaConnectorOptionsUtil.java
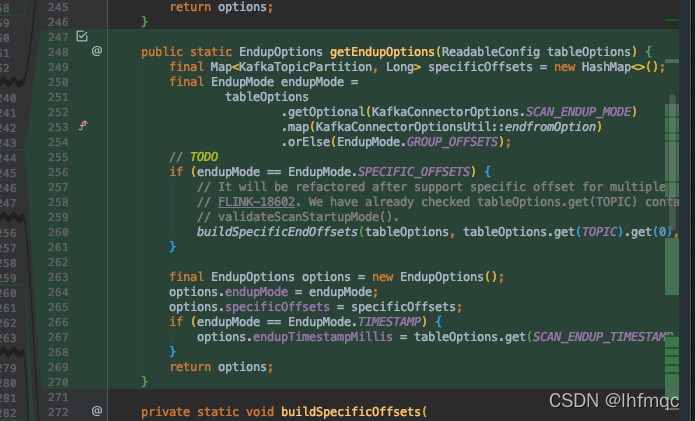
public static EndupOptions getEndupOptions(ReadableConfig tableOptions) {
final Map<KafkaTopicPartition, Long> specificOffsets = new HashMap<>();
final EndupMode endupMode =
tableOptions
.getOptional(KafkaConnectorOptions.SCAN_ENDUP_MODE)
.map(KafkaConnectorOptionsUtil::endfromOption)
.orElse(EndupMode.GROUP_OFFSETS);
//这个地方需要注意一下,需要创建一个获取结束偏移位置的方法
if (endupMode == EndupMode.SPECIFIC_OFFSETS) {
buildSpecificEndOffsets(tableOptions, tableOptions.get(TOPIC).get(0), specificOffsets);
}
//
final EndupOptions options = new EndupOptions();
options.endupMode = endupMode;
options.specificOffsets = specificOffsets;
if (endupMode == EndupMode.TIMESTAMP) {
options.endupTimestampMillis = tableOptions.get(SCAN_ENDUP_TIMESTAMP_MILLIS);
}
return options;
}
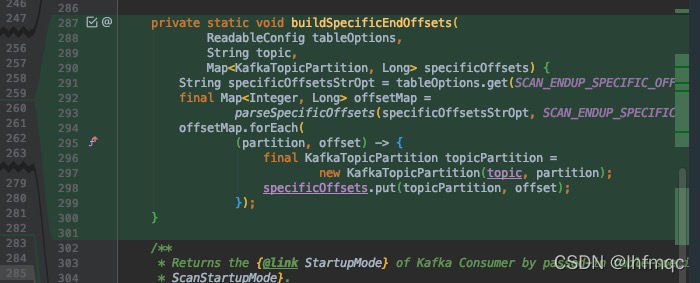
private static void buildSpecificEndOffsets(
ReadableConfig tableOptions,
String topic,
Map<KafkaTopicPartition, Long> specificOffsets) {
String specificOffsetsStrOpt = tableOptions.get(SCAN_ENDUP_SPECIFIC_OFFSETS);
final Map<Integer, Long> offsetMap =
parseSpecificOffsets(specificOffsetsStrOpt, SCAN_ENDUP_SPECIFIC_OFFSETS.key());
offsetMap.forEach(
(partition, offset) -> {
final KafkaTopicPartition topicPartition =
new KafkaTopicPartition(topic, partition);
specificOffsets.put(topicPartition, offset);
});
}
这个地方是仿照开始偏移位置进行编写,这个其实很容易看出来,但是由于最开始不理解浪费了好长时间。仿照buildSpecificOffsets 进行编写,根据开始SCAN_STARTUP_SPECIFIC_OFFSETS,设置SCAN_ENDUP_SPECIFIC_OFFSETS,这个属性对应的值是从前端建表的时候传入的。
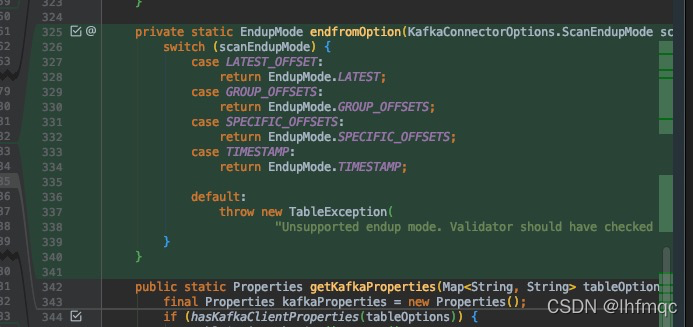
private static EndupMode endfromOption(KafkaConnectorOptions.ScanEndupMode scanEndupMode) {
switch (scanEndupMode) {
case LATEST_OFFSET:
return EndupMode.LATEST;
case GROUP_OFFSETS:
return EndupMode.GROUP_OFFSETS;
case SPECIFIC_OFFSETS:
return EndupMode.SPECIFIC_OFFSETS;
case TIMESTAMP:
return EndupMode.TIMESTAMP;
default:
throw new TableException(
"Unsupported endup mode. Validator should have checked that.");
}
}
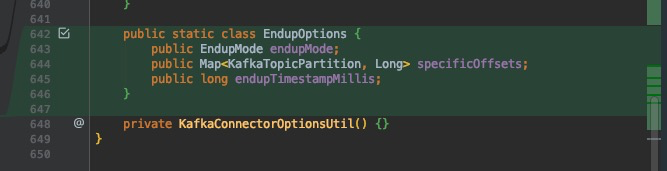
/** Kafka endup options. * */
public static class EndupOptions {
public EndupMode endupMode;
public Map<KafkaTopicPartition, Long> specificOffsets;
public long endupTimestampMillis;
}
5,KafkaDynamicSource
对应前面的修改,后续创建数据源方法也要修改,将新增的参数加入即可
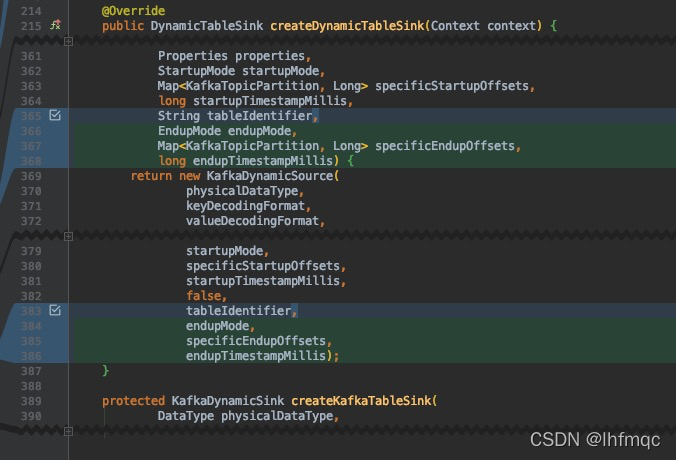
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/table/KafkaDynamicSource.java

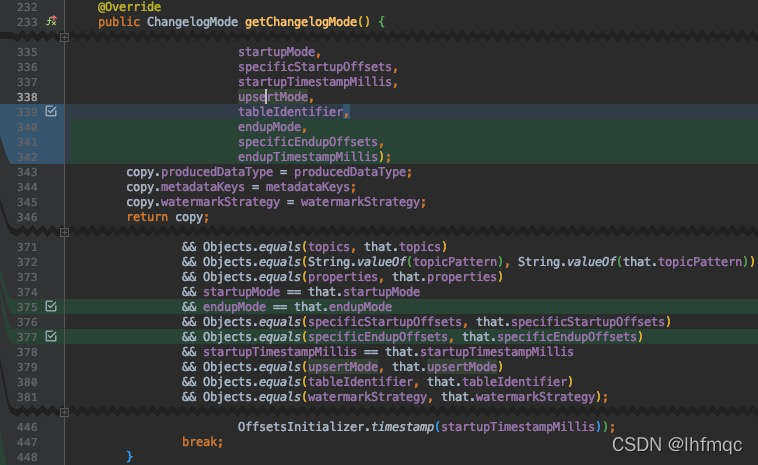
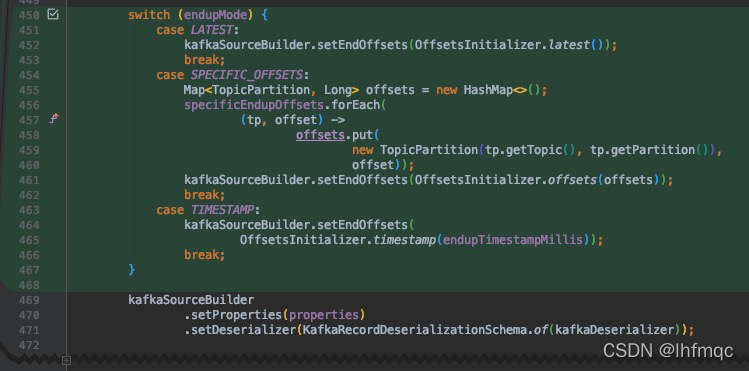
6,KafkaDynamicTableFactory
同理跟随前面新增的参数,后续创建对象也需加上
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/table/KafkaDynamicTableFactory.java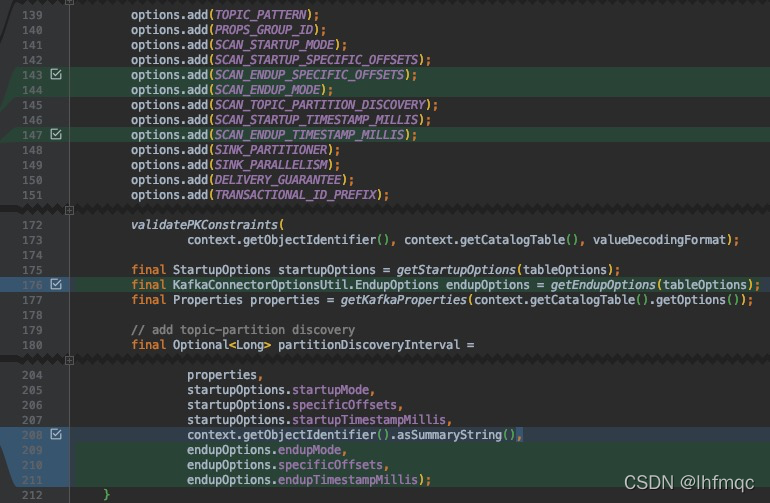
7,UpsertKafkaDynamicTableFactory
同理跟随前面新增的参数,后续创建对象也需加上
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/table/UpsertKafkaDynamicTableFactory.java
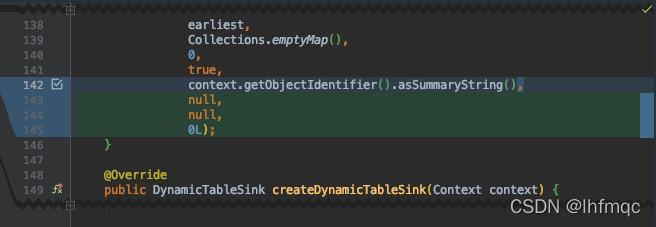
以上是全部需要修改的地方,下面测试文件会在打包时会报错,也需要修改一下了
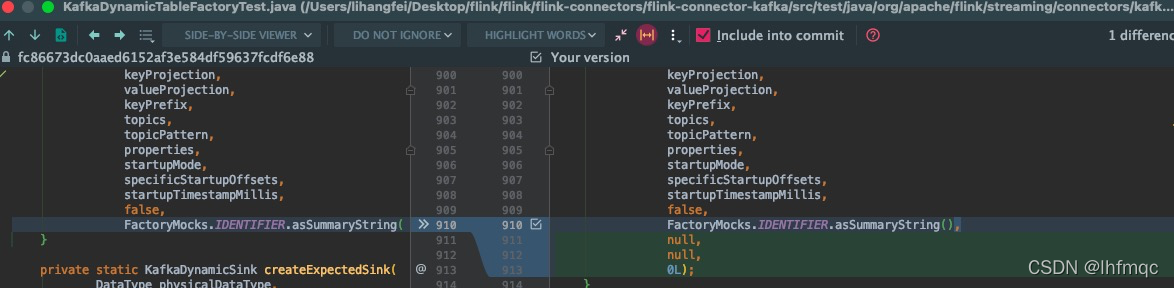
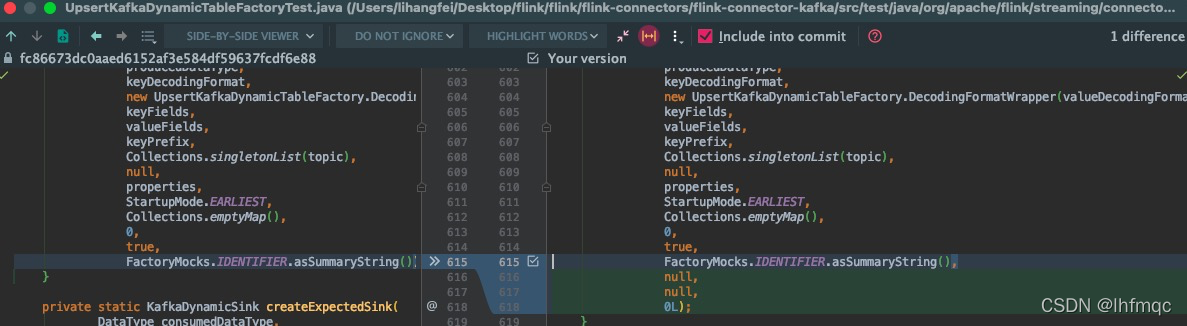
具体的测试代码如下:
1,创建运行环境
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(streamExecutionEnvironment,settings);
2,建表
有3种设置结束偏移位置的方式,以下是具体案例
// 1,建表语句,latest-offset
// 'scan.endup.mode' = 'specific-offsets',\n" +
String connectSql = "CREATE TABLE KafkaTable (\n" +
" `user_id` BIGINT,\n" +
" `item_id` BIGINT,\n" +
" `age` BIGINT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'test02',\n" +
" 'properties.bootstrap.servers' = 'localhost:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'scan.endup.mode' = 'latest-offset',\n" +
" 'format' = 'csv'\n" +
")";
// 2,建立连接sql 特定偏移位置
// 'scan.endup.mode' = 'specific-offsets',\n" +
// 'scan.endup.specific-offsets' = 'partition:0,offset:22',\n" +
String connectSql = "CREATE TABLE KafkaTable (\n" +
" `user_id` BIGINT,\n" +
" `item_id` BIGINT,\n" +
" `age` BIGINT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'test02',\n" +
" 'properties.bootstrap.servers' = 'localhost:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'scan.endup.mode' = 'specific-offsets',\n" +
" 'scan.endup.specific-offsets' = 'partition:0,offset:22',\n" +
" 'format' = 'csv'\n" +
")";
// 3,建立连接sql 特定时间点
// " 'scan.endup.mode' = 'timestamp',\n" +
// " 'scan.endup.timestamp-millis' = '1648124880000',\n" +
String connectSql = "CREATE TABLE KafkaTable (\n" +
" `user_id` BIGINT,\n" +
" `item_id` BIGINT,\n" +
" `age` BIGINT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'test02',\n" +
" 'properties.bootstrap.servers' = 'localhost:9092',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'scan.endup.mode' = 'timestamp',\n" +
" 'scan.endup.timestamp-millis' = '1648124880000',\n" +
" 'format' = 'csv'\n" +
")";
//执行sql创建表
streamTableEnvironment.executeSql(connectSql);
3,输出逻辑
//查询逻辑
Table result = streamTableEnvironment.sqlQuery("select user_id ,item_id,age from KafkaTable");
//表数据转流数据 方便输出
DataStream<Row> rowDataStream = streamTableEnvironment.toDataStream(result);
streamExecutionEnvironment.execute();
https://www.cnblogs.com/eryuan/p/15791843.html

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)