Hadoop集群的完整搭建(Hadoop完全分布式+ZooKeeper+Mysql+Hive+Hbase完全分布式+Spark完全分布式)
Hadoop集群的完整搭建准备工作网络环境的配置修改网关、IP配置映射、主机名重启网络服务,测试ssh的配置jdk的安装Hadoop完全分布式的安装准备工作修改配置文件slaveshadoop-env.shyarn-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml分发到其他节点测试安装Zookeeper准备工作修改配置文件分发
Hadoop集群的完整搭建
准备工作
网络环境的配置
修改网关、IP
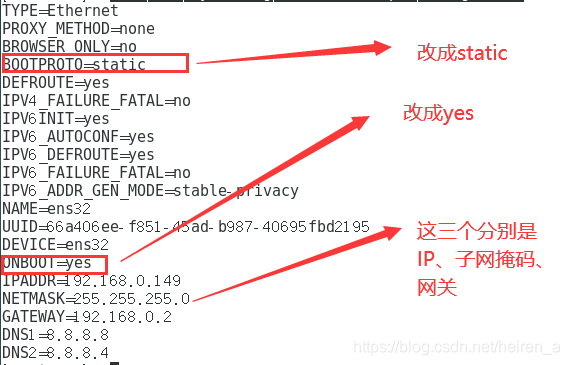
- 打开要修改的文件(最后一个文件名可能每个人的不一样):
vi /etc/sysconfig/network-scripts/ifcfg-ens32
配置映射、主机名
- 配置映射:
vi /etc/hosts

- 配置主机名:
vi /etc/sysconfig/network

重启网络服务,测试
- 命令:
service network restart

- 其他俩台也是如此
ssh的配置
-
命令:
ssh-keygen -t rsa,连续回车四次 -
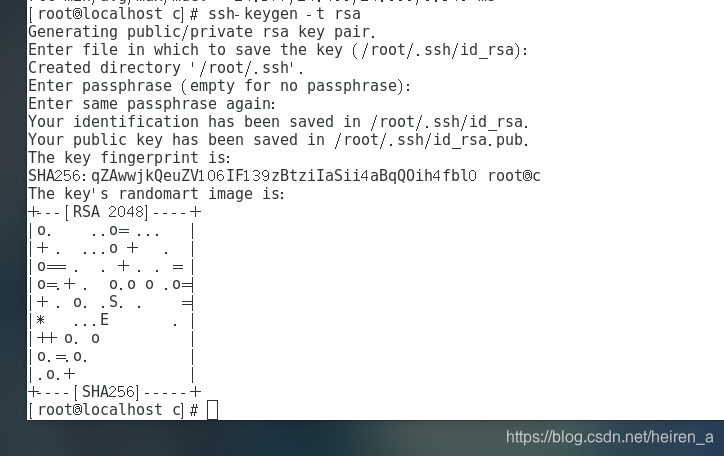
-
使用命令将公钥分发到其他的节点上:
ssh-copy-id b -
其他的节点如此
jdk的安装
- 解压压缩文件:
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /home/ - 重命名:
mv jdk1.8.0_161/ jdk - 配置环境变量:
vi /etc/profile
export JAVA_HOME=/home/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=${JAVA_HOME}/bin:$PATH
- 使环境变量生效:
source /etc/profile - 检测jdk是否安装成功:
java -version

Hadoop完全分布式的安装
准备工作
- 解压缩:
tar -zxvf hadoop-2.7.1_64bit.tar.gz -C /home/ - 重命名:
mv hadoop-2.7.1/ hadoop - 在解压好的hadoop目录下创建几个文件夹
mkdir tmp
mkdir -p hdfs/name
mkdir hdfs/data
修改配置文件
slaves
b
c
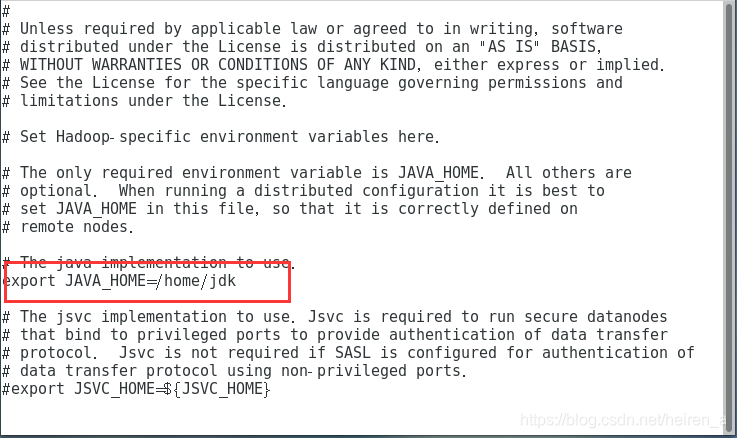
hadoop-env.sh
- jdk的路径
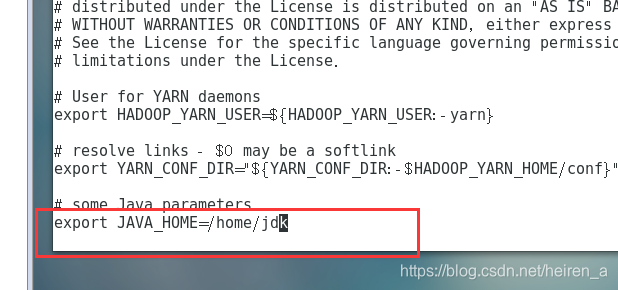
yarn-env.sh
- jdk的路径
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://a:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>a:50090</value>
</property>
mapred-site.xml
- 如果没有
mapred-site.xml可以将mapred-site.xml.template复制为,mapred-site.xml,命令是:mv mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>a:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>a:19888</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>a</value>
</property>
分发到其他节点
scp -r /home/hadoop b:/home
测试
-
在主节点的bin目录下格式化:
hadoop namenode -format -
在主节点的sbin目录下开启集群:
start-all.sh -
主节点的进程:
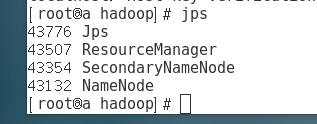
-
从节点的进程

-
访问50070端口
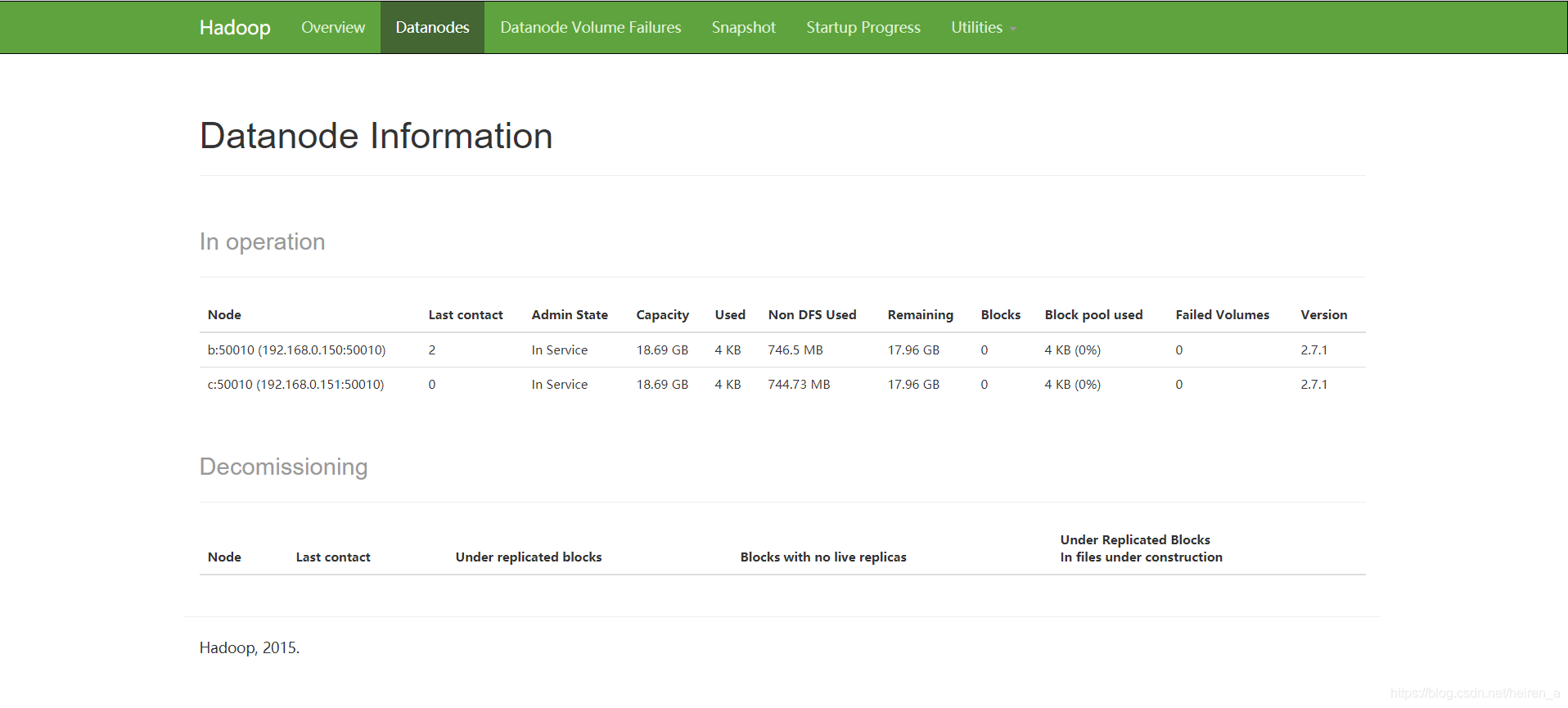
-
访问8088端口
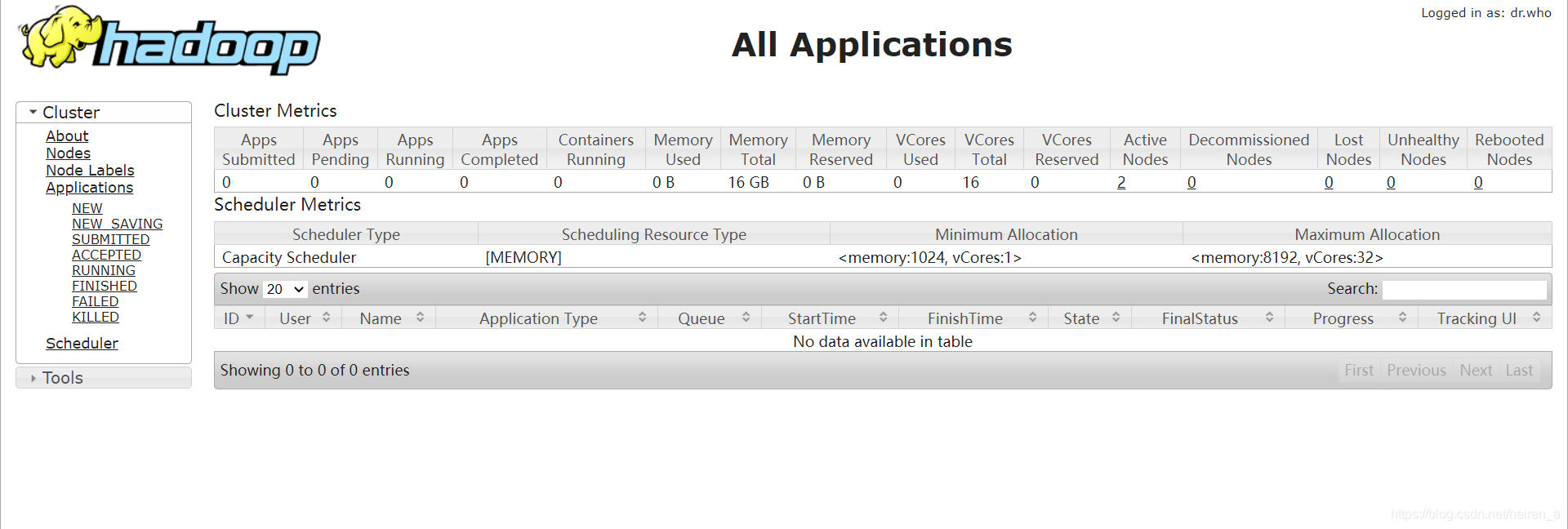
安装Zookeeper
准备工作
- 解压缩:
tar -zxvf zookeeper-3.4.8.tar.gz -C /home/ - 重命名:
mv zookeeper-3.4.8/ zookeeper - 在解压缩的目录下创建文件夹
mkdir logs
mkdir data
修改配置文件
- 将conf目录下的zoo_samlp.cfg文件复制为zoo.cfg
- 修改zoo.cfg文件
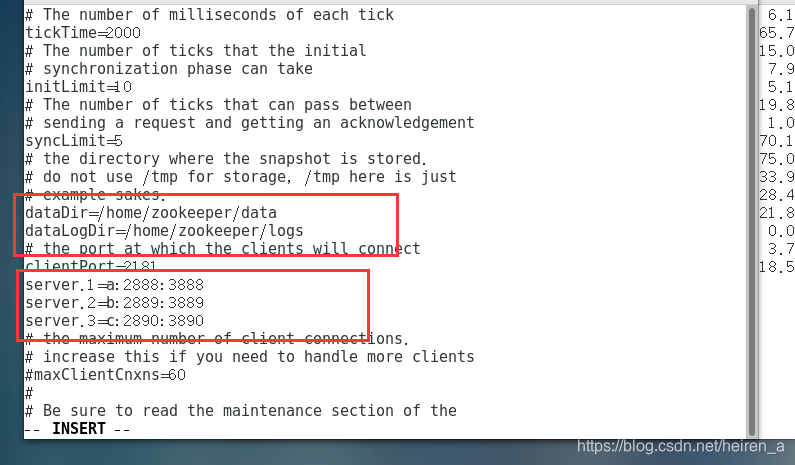
分发即修改文件
- 分发给其他的节点:
scp -r /home.zookeeper b:/home - 分别执行下面代码,数字与zoo.cfg中的相对应:
echo 1 > data/myid
测试
- 开启:
bin/zkServer.sh start - 查看状态:
bin/zkServer.sh status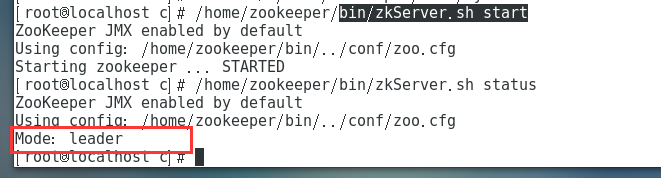
MYSQL的安装
准备工作
解压、重命名
- 解压缩:
tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -C /home/ - 重命名:
mv mysql-5.7.31 mysql
创建MySQL用户
groupadd mysql
useradd -r -g mysql mysql
创建存储文件、并且赋权
mkdir -p /data/mysql
chown -R mysql:mysql /data/mysql/
修改配置文件
- 修改etc下的my.cnf文件
[mysqld]
bind-address=0.0.0.0
port=3306
user=mysql
datadir=/data/mysql
basedir=/home/mysql/
pid-file=/data/mysql/mysql.pid
log-error=/data/mysql/mysql.err
socket=/tmp/mysql.sock
symbolic-links=0
character_set_server=utf8mb4
explicit_defaults_for_timestamp=true
启动并且测试
-
在MySQL的解压目录下格式化:
bin/mysqld --defaults-file=/etc/my.cnf --basedir=/home/mysql/ --datadir=/data/mysql/ --user=mysql --initialize -
执行下面代码以便快速开启mysql服务:
cp /home/mysql/support-files/mysql.server /etc/init.d/mysql -
打开my.cnf设置的mysql.err文件,查看初始密码
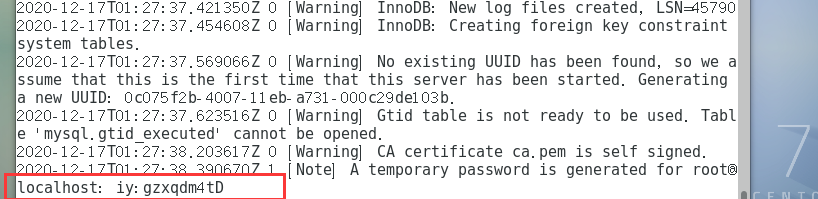
-
开启mysql服务
service mysql start

-
开启MySQL:
mysql -uroot -p -
重设密码
SET PASSWORD=PASSWORD('123456');
ALTER USER 'ROOT'@'LOCALHOST' PASSWORD EXPIRE NEVER;
FLUSH PRIVILEGES;
设置mysql远程登录
use mysql;
UPDATE USER SET HOST ='%' WHERE USER ='ROOT';
FLUSH PRIVILEGES;
- 如果mysql忘记密码或者初始密码错误,请看链接: 重置MySQL密码.
Hive的安装
准备工作
解压、重命名
- 解压缩:
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /home/ - 重命名:
mv apache-hive-3.1.2-bin/ hive
移动mysqljar包
- 移动mysqljar包到hive的lib目录下:
cp /home/download/mysql-connector-java-5.1.40-bin.jar /home/hive/lib/
修改配置文件
- 修改hive-env.sh文件
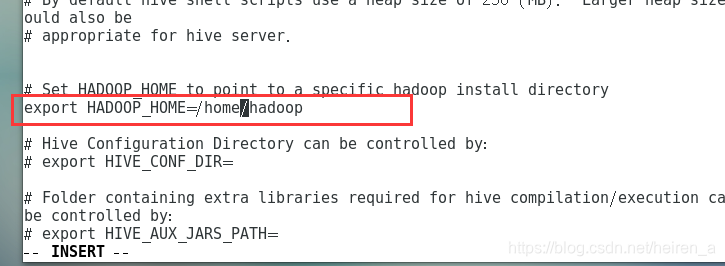
- 修改hive-site.xml文件
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://a:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
</configuration>
测试
- 初始化:
bin/schematool -dbType mysql -initSchema - 启动:
bin/hive
Hbase的搭建
准备工作
解压重命名
- 解压:
tar -zxvf hbase-1.4.12-bin.tar.gz -C /home/ - 重命名:```mv hbase-1.4.12 hbase
修改配置文件
- 修改hbase-env.sh文件
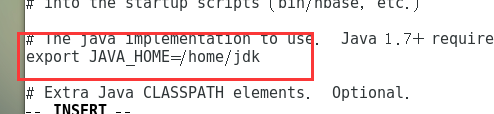

- 修改hbase-site.xml文件
<property>
<name>hbase.rootdir</name>
<value>hdfs://a:9000/hbase</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>a,b,c</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hbase/jn</value>
</property>
- 修改regionservers 文件
b
c
测试
- 分发到其他节点:
scp -r /home/hbase/ b:/home/
scp -r /home/hbase/ c:/home/
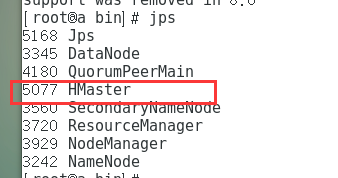
- 在bin目录下开启:```start-hbase.sh
- 主节点
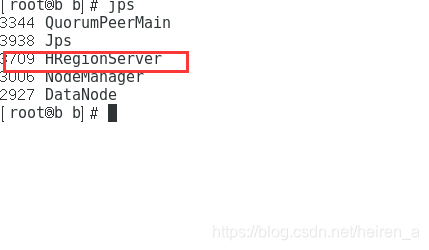
- 从节点
spark的安装
先安装Scala
解压、配置环境变量
- 解压缩:
tar --zxvf scala-2.10.4.tgz - 配置环境变量
export SCALA_HOME=/home/scala
export PATH=$PATH:$SCALA_HOME/bin
测试Scala是否安装成功
- 在Scala的bin目录下

准备工作
- 解压、重命名
- 解压:
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /home - 重命名:
mv spark-2.2.0-bin-hadoop2.7/ spark
配置文件
- 修改spark-env.sh文件
export JAVA_HOME=/home/jdk
export HADOOP_HOME=/home/hadoop
export HADOOP_CONF_DIR=/home/hadoop/etc/conf
export SPARK_MASTER_PORT=7077
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=a,b,c
-Dspark.deploy.zookeeper.dir=/spark"
- 修改slaves文件
b
c
测试
-
在bin目录下打开进程:
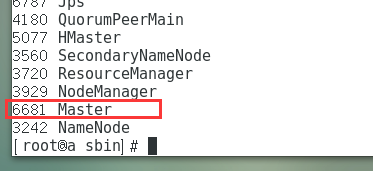
start-all.sh -
主节点
-
从节点
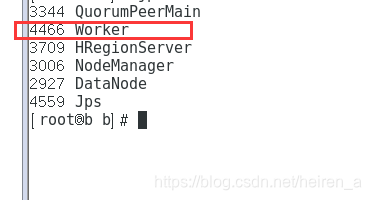
-
在sbin目录下打开spark:
spark-shell
Hadoop-HA的搭建
HDFS-HA
- 修改core-site.xml文件
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>a,b,c</value>
</property>
- 修改hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>n1,n2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.n1</name>
<value>a:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.n2</name>
<value>b:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.n1</name>
<value>a:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.n2</name>
<value>b:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://a:8485;b:8485;c:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
yarn-HA
- 修改yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>r1,r2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.r1</name>
<value>a</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.r2</name>
<value>b</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.r1</name>
<value>a:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.r2</name>
<value>b:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>a,b,c</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
启动、测试
- 启动各个节点的journalnode进程:
/home/hadoop/sbin/hadoop-daemon.sh start journalnode - 格式化某一个namenode节点;
/home/hadoop/bin/hadoop namenode -format - 将格式化过的namenode节点下的tmp目录复制到没有格式化的namenode下:
scp /home/hadoop/tmp b:/home/hadoop - 格式化zkfc进程:
/home/hadoop/bin/hadoop zkfc -formatZK - 在namenode节点上启动zkfc进程:```/home/hadoop/sbin/hadoop-daemon.sh start zkfc
- 启动进程:
/sbin/start-all.sh

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)