ES分组聚合Agg nested
类似于select brandId,sum(salesVolume) from live_room group by brandId分组之后,再进行求和等运算
ES的分组聚合
类似于select brandId, sum(salesVolume) from live_room group by brandId ;
求每个品牌下的直播间销额有多少
正文开始
新建索引live_room
mapping结构如下
背景:直播间id关联的品牌销售情况,每个直播间都能带很多商品,自然的,每个直播间也能通过商品关联到很多品牌。计算每个品牌的销额销量等数据,就是此直播间这个品牌关联商品的和
注意: 如果需要使用分组完之后的聚合功能,需要把一些list的字段类型设为nested!

PUT live_room
PUT live_room/_mapping
{
"properties": {
"roomId": {
"type": "long"
},
"roomName": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"brandDataNested": {
"type": "nested",
"properties": {
"id": {
"type": "long"
},
"liveSales": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"productNum": {
"type": "long"
},
"salesVolume": {
"type": "long"
},
"sort": {
"type": "long"
}
}
}
}
}
数据情况
塞两条数据
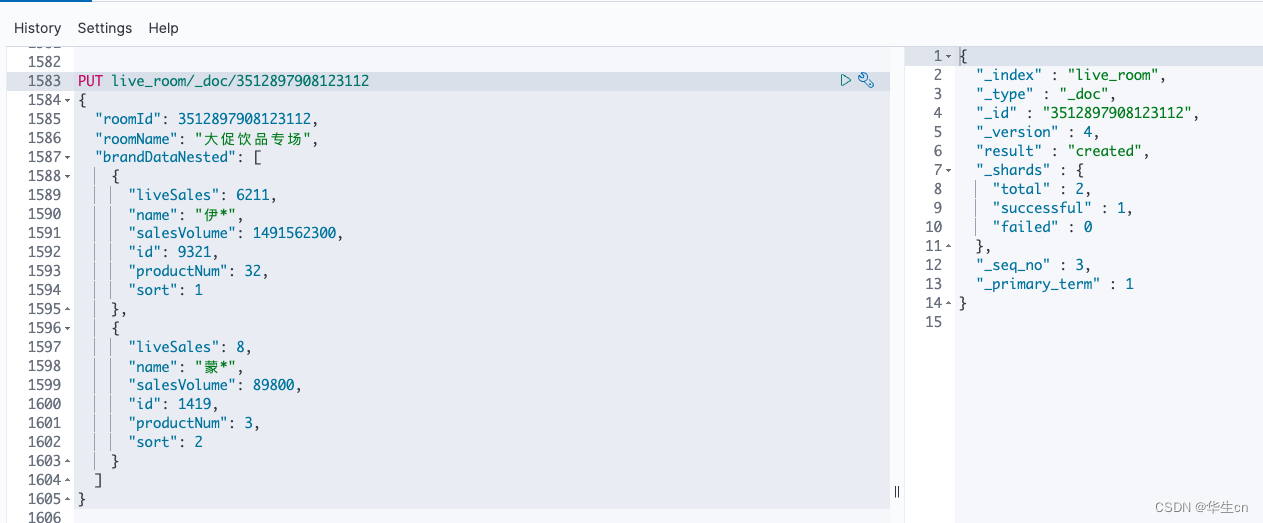
PUT live_room/_doc/3512897908123112
{
"roomId": 3512897908123112,
"roomName": "大促饮品专场",
"brandDataNested": [
{
"liveSales": 6211,
"name": "伊*",
"salesVolume": 1491562300,
"id": 9321,
"productNum": 32,
"sort": 1
},
{
"liveSales": 8,
"name": "蒙*",
"salesVolume": 89800,
"id": 1419,
"productNum": 3,
"sort": 2
}
]
}
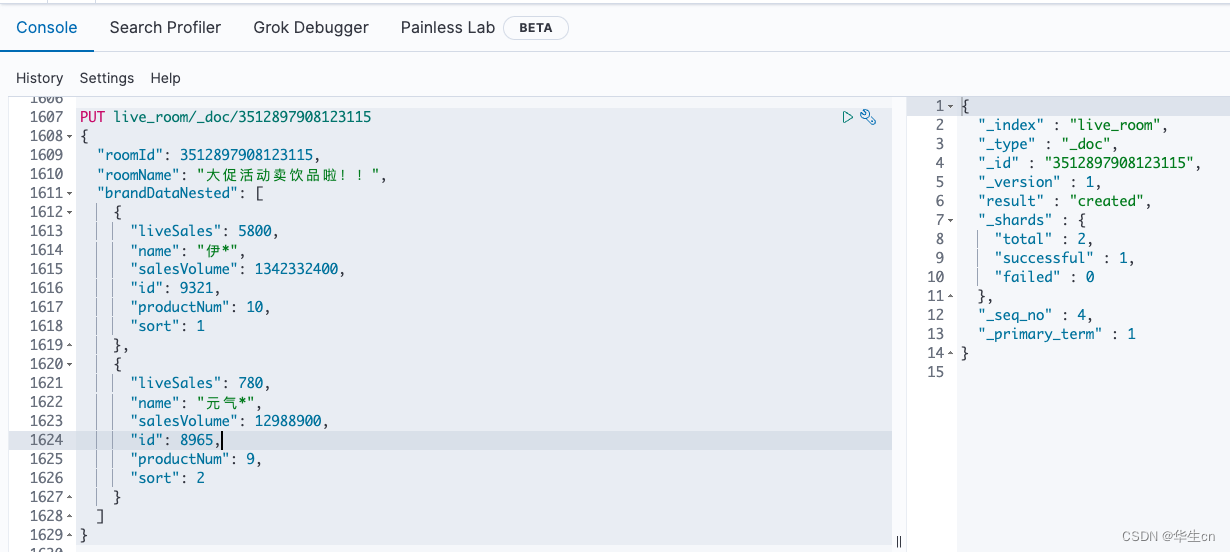
PUT live_room/_doc/3512897908123115
{
"roomId": 3512897908123115,
"roomName": "大促活动卖饮品啦!!",
"brandDataNested": [
{
"liveSales": 5800,
"name": "伊*",
"salesVolume": 1342332400,
"id": 9321,
"productNum": 10,
"sort": 1
},
{
"liveSales": 780,
"name": "元气*",
"salesVolume": 12988900,
"id": 8965,
"productNum": 9,
"sort": 2
}
]
}
使用Agg聚合数据
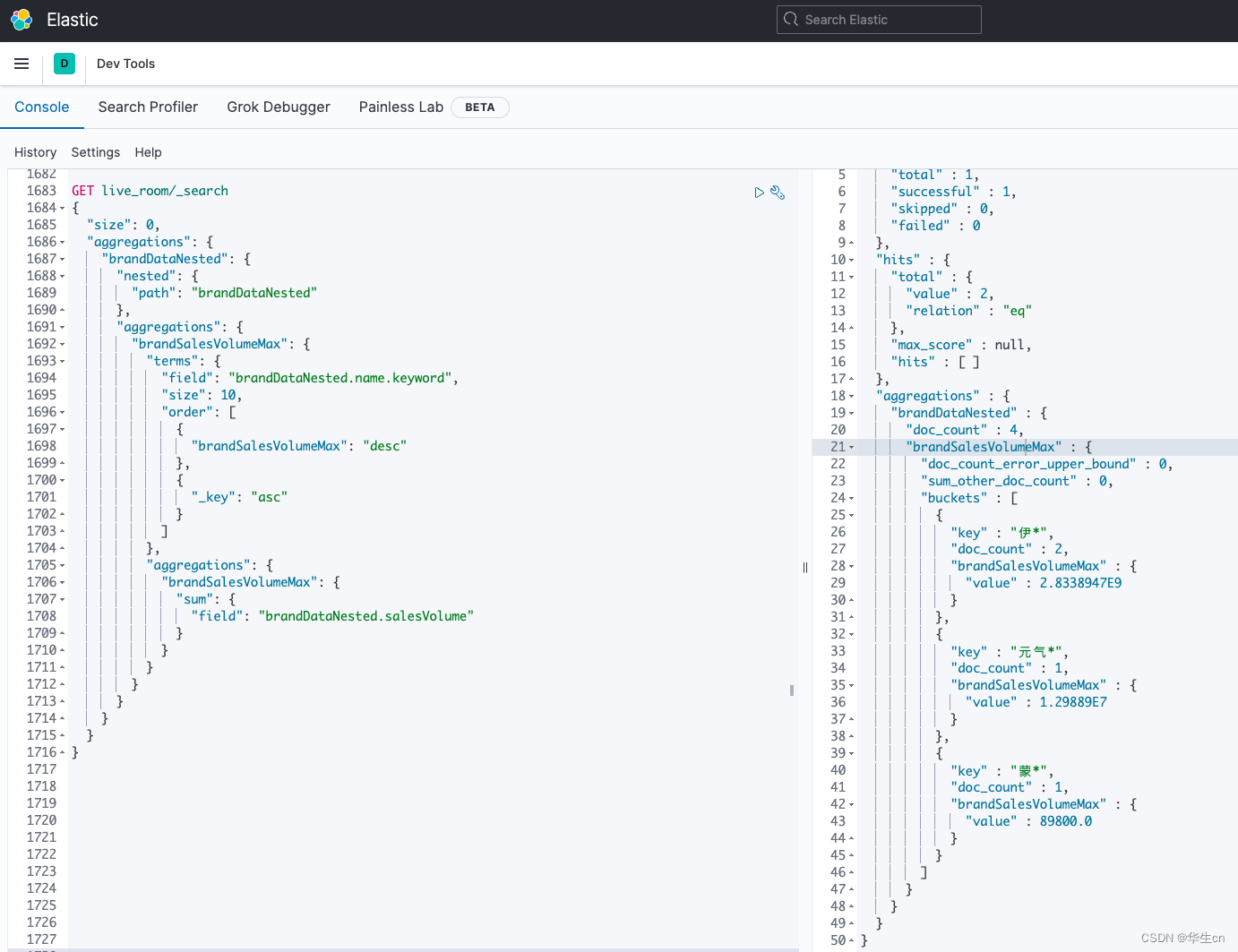
GET live_room/_search
{
"size": 0,
"aggregations": {
"brandDataNested": {
"nested": {
"path": "brandDataNested"
},
"aggregations": {
"brandSalesVolumeMax": {
"terms": {
"field": "brandDataNested.name.keyword",
"size": 10,
"order": [
{
"brandSalesVolumeMax": "desc"
},
{
"_key": "asc"
}
]
},
"aggregations": {
"brandSalesVolumeMax": {
"sum": {
"field": "brandDataNested.salesVolume"
}
}
}
}
}
}
}
}
这里实现了按品牌名分组聚合统计,并且计算了每个品牌的销额sum
Java代码实现
//第一组聚合,按brandDataNested的name分组
//这个size是一个可配置的精度
TermsAggregationBuilder brandNameAgg = AggregationBuilders.terms("brand")
.field("brandDataNested.name.keyword").size(10);
//第二组聚合,按name分组之后再使用sum求销额的和
String sumName = "brandSalesVolume";
SumAggregationBuilder brandSalesVolume = AggregationBuilders.sum(sumName).field("brandDataNested.salesVolume");
//第一组聚合中提交第二组聚合
brandNameAgg.subAggregation(brandSalesVolume);
//聚合排序,这里使用销额倒排
brandNameAgg.order(BucketOrder.aggregation(sumName, false));
//在最外层的查询将agg聚合设置进去,并且使用nested
NestedAggregationBuilder nestedAggregationBuilder = AggregationBuilders.nested("brandDataNested", "brandDataNested")
.subAggregation(brandNameAgg);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//此处可以添加筛选语句
// searchSourceBuilder.query(query);
//聚合查询
searchSourceBuilder.aggregation(nestedAggregationBuilder);
//只返回聚合统计结果,不返回关联的具体文档
searchSourceBuilder.size(0);
SearchRequest request = new SearchRequest("live_room");
request.source(searchSourceBuilder);
try {
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//获取所有桶
Aggregations brandNameAggregations = search.getAggregations();
ParsedNested brandDataNested = brandNameAggregations.get("brandDataNested");
Aggregations brandDataNestedAggregations = brandDataNested.getAggregations();
Terms brandNameTerms = brandDataNestedAggregations.get("brand");
for (Terms.Bucket brandNameTermsBucket : brandNameTerms.getBuckets()) {
Aggregations aggregationsSon = brandNameTermsBucket.getAggregations();
String keyAsString = brandNameTermsBucket.getKeyAsString();
long docCount = brandNameTermsBucket.getDocCount();
ParsedSum brandSalesVolumeMax1 = aggregationsSon.get(sumName);
double value = brandSalesVolumeMax1.getValue();
}
} catch (Exception e) {
log.error("es查找报错,{}: {}", EsIndexEnum.DCM_LIVE_SEARCH_FOR_FIND.getIndex(), e.getMessage(), e);
}
代码中的size 10需要依据自己业务进行配置,es官网文档中的解释是:
示例会确保当字段唯一值在 100 以内时会得到非常准确的结果。尽管算法是无法保证这点的,但如果基数在阈值以下,几乎总是 100% 正确的。高于阈值的基数会开始节省内存而牺牲准确度,同时也会对度量结果带入误差。
还有一点,如果说,你需要聚合非常多的数据,在此文档的例子中的话,就是直播间数量巨大,需要聚合计算的品牌也众多,你可能需要提前计算好hash值,官网文档中的解释是:
现在 cardinality 度量会读取 “color.hash” 里的值(预先计算的哈希值),取代动态计算原始值的哈希。
单个文档节省的时间是非常少的,但是如果你聚合一亿数据,每个字段多花费 10 纳秒的时间,那么在每次查询时都会额外增加 1 秒,如果我们要在非常大量的数据里面使用 cardinality ,我们可以权衡使用预计算的意义,是否需要提前计算 hash,从而在查询时获得更好的性能,做一些性能测试来检验预计算哈希是否适用于你的应用场景。。
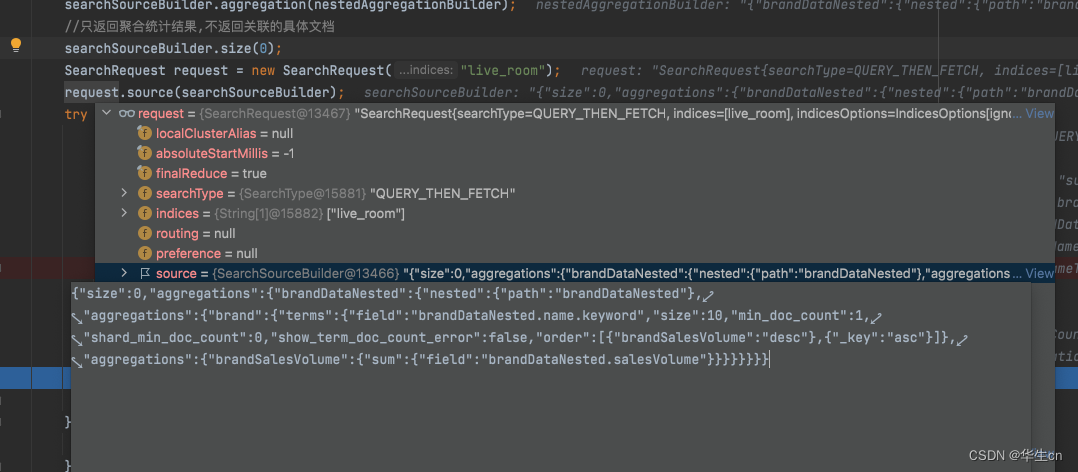
debug调试结果:
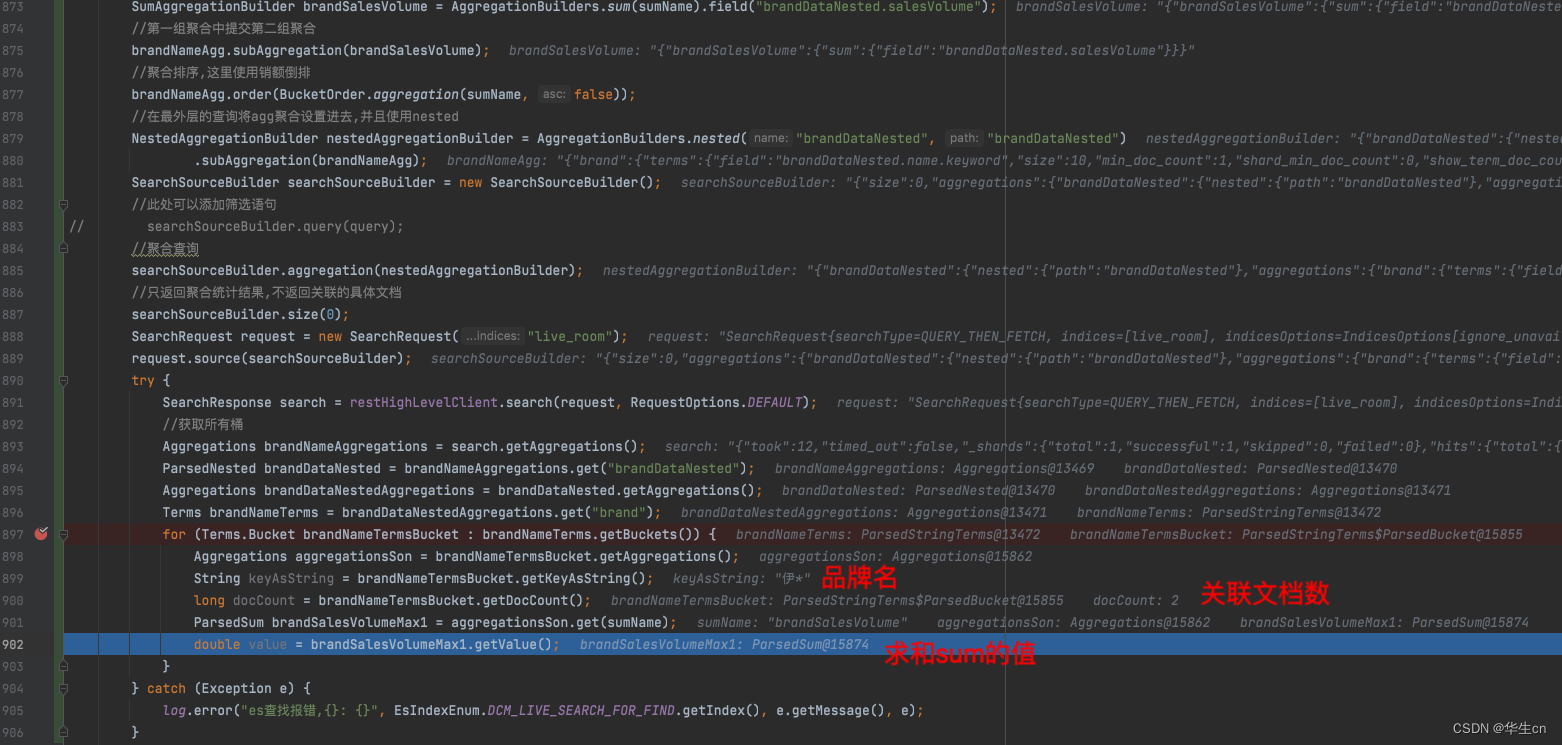
这里还有一个小技巧,在调试的时候,最后发起请求的request中,直接点击source,会拼接好es的dsl语句,可以直接复制在es的kibana控制台使用

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)