redis内存碎片整理
redis在大量申请、释放资源后,会产生内存碎片,大量的内存碎片会影响新内存的申请,本文分析redis自带的内存碎片整理代码逻辑。
一、背景
什么是内存碎片?
Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 jemalloc。造成内存碎片的原因:
- jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节…)来分配内存,分配的内存一般都会比申请的大一些,多出来的内存可能无法使用;
- redis 释放的内存可能是不连续的。 这种不连续的内存可能不会再被使用,空闲但无法使用的就是内存碎片。
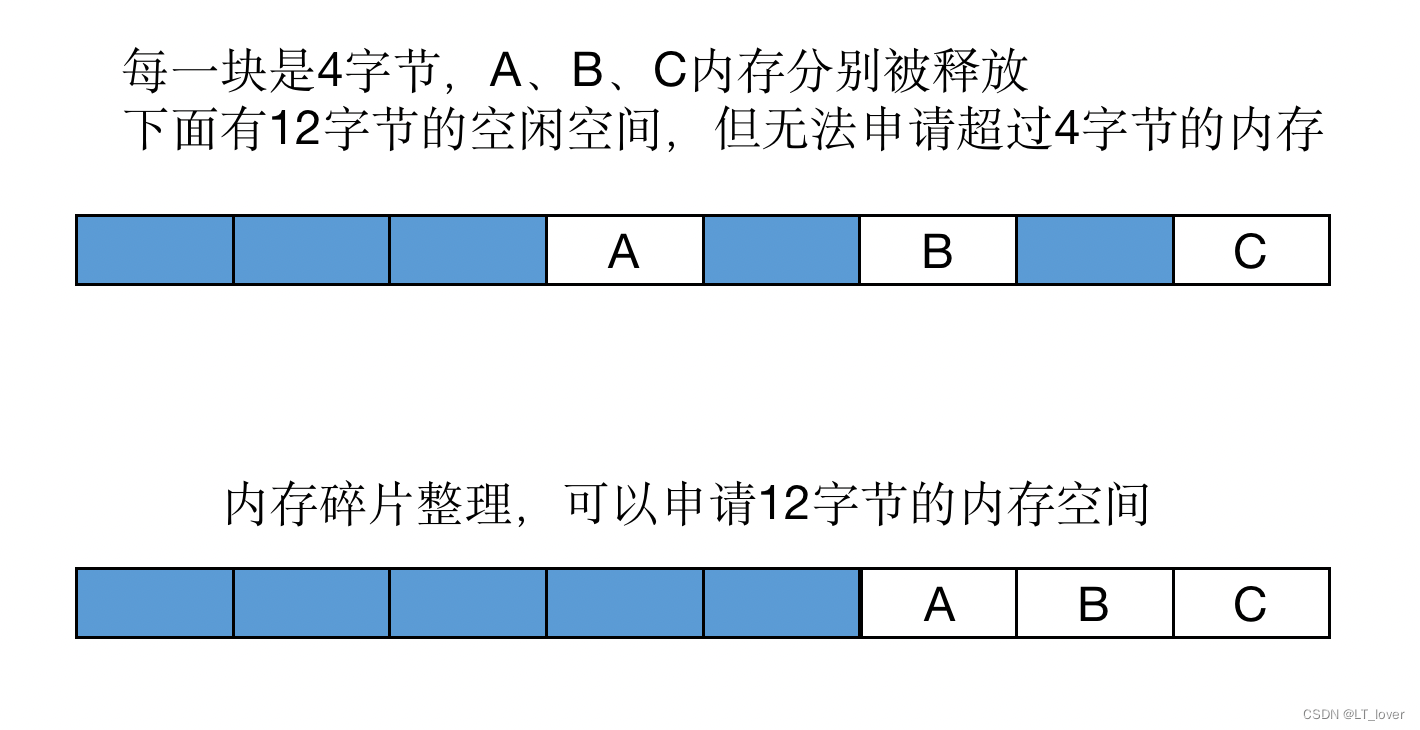
比如:
下面命令可以查看 redis 集群内存使用相关信息:
[root@localhost redis]# redis-cli info memory
# Memory
# 进程申请内存
used_memory:960000
# 实际分配内存
used_memory_rss:2800000
# 碎片率
mem_fragmentation_ratio:2.80
# 碎片大小(字节)
mem_fragmentation_bytes:1900000
...
内存碎片无法完全避免,只能降低碎片率。
二、内存碎片整理原理
原理很简单。如果在 Mysql 中如果一个表经过大量的增删改查造成大量的页空洞,导致表空间占用超过实际数据大小的时候,可以使用命令收缩表空间。就是一个 新建临时表 -> 拷贝数据 -> rename 临时表为 t 的过程。
在4.0之前,可以通过重启 Redis 实例来达到该目的。重启之后 Redis 加载 AOF 或者 RDB 文件来重新构造内存,从而达到碎片整理的目的。redis 4.0后,加入了内存碎片整理功能:active 碎片整理,不需要重启 Redis 实例的渐进式的整理内存。
自动清理内存碎片 需要内存分配器是 jemalloc 才能启用。核心点是利用了 jemalloc 的特性,不从线程缓存中获取内存,而是从新申请一块内存,从而将旧的有内存碎片的内存释放掉。
三、内存碎片整理流程
相关代码实现在 defrag.c 文件中。
1、初始化
在 main 函数中调用 initServer 进行各种配置的初始化操作,其中创建了 serverCron 定时任务函数。在定时函数中,最终调用了 activeDefragCycle 函数,进行渐进式的内存碎片整理。
void initServer(void) {
// ...
// 为server后台任务 创建定时事件
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
// ...
}
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// ...
// 执行数据库的后台操作
databasesCron();
// ...
}
void databasesCron(void) {
// ...
// 渐进式内存碎片整理
activeDefragCycle();
// ...
}
2、总体逻辑
activeDefragCycle 函数调用 computeDefragCycles 函数,检查是否需要碎片整理,如果不需要整理 直接返回即可。
void activeDefragCycle(void) {
// 每秒检查一次, 是否需要开始扫描碎片
run_with_period(1000) {
computeDefragCycles();
}
// 内存碎片 不需要整理
if (!server.active_defrag_running)
return;
// 计算函数可以执行的最大时间
start = ustime();
timelimit = 1000000*server.active_defrag_running/server.hz/100;
endtime = start + timelimit;
// ...
}
然后进行 while 循环,遍历所有 db 进行内存碎片处理,大概流程:
- 找到一个待处理的 db;
- 遍历 db 中所有的 key 进行检查,确定是否需要整理碎片,函数是 defragScanCallback、defragDictBucketCallback(后面详细说明)。
处理内存碎片的核心就是 dictScan 函数在遍历 db 所有 key 时的回调函数 defragScanCallback 和 defragDictBucketCallback。
-
defragDictBucketCallback:遍历 hash 的每个 bucket 时,回调一次这个函数;
-
defragScanCallback:遍历 hash 的每个 key-value 时都回调一次这个函数。
void activeDefragCycle(void) {
// 下面都是静态变量, 多次调用当前函数时, 可以继续上一次db的位置继续处理
static int current_db = -1;
static unsigned long cursor = 0;
static redisDb *db = NULL;
int quit = 0;
// ...
do {
// cursor不为0, 说明上次未扫描完成, 继续上次db未完成的扫描, 进行内存压缩, 降低内存碎片率
if (!cursor) {
// 延时处理大key, 后面有详细解释
if (db && defragLaterStep(db, endtime)) {
quit = 1; // 函数执行已经超时, 下次继续执行
break;
}
// 继续处理下一个db, 处理到最后一个停止
if (++current_db >= server.dbnum) {
// 所有db已经处理完毕, 对不属于db的keys进行碎片整理
defragOtherGlobals();
// 重置相关变量...
computeDefragCycles(); /* if another scan is needed, start it right away */
if (server.active_defrag_running != 0 && ustime() < endtime)
continue;
break;
} else if (current_db==0) {
// 开始处理第一个db, 记录时间
start_scan = ustime();
start_stat = server.stat_active_defrag_hits;
}
// 处理一个新的db
db = &server.db[current_db];
cursor = 0;
}
// 处理当前db数据
do {
// 在扫描下一个bucket之前, 看是否有前一个bucket留下来的大object需要处理
if (defragLaterStep(db, endtime)) {
// 当前次时间片已经用完, 而且还有数据等待处理, 下次继续处理
quit = 1;
break;
}
// 扫描整个db的所有kv(db->dict), 每扫描到一个object时, 调用函数defragScanCallback进行内存碎片整理
cursor = dictScan(db->dict, cursor, defragScanCallback, defragDictBucketCallback, db);
// 没有数据 或者 遍历很多次了, 检查下是否超过时间限制, 如果超时 就退出, 等待下次cron任务再进行处理
if (!cursor || (++iterations > 16 || server.stat_active_defrag_hits - prev_defragged > 512 ||
server.stat_active_defrag_scanned - prev_scanned > 64)) {
if (!cursor || ustime() > endtime) {
quit = 1;
break;
}
// 执行还未超时, 清空相关计数, 继续执行
iterations = 0;
prev_defragged = server.stat_active_defrag_hits;
prev_scanned = server.stat_active_defrag_scanned;
}
} while(cursor && !quit);
} while(!quit);
}
3、defragDictBucketCallback
首先看下 defragDictBucketCallback 函数,函数会遍历 bucket 下的所有 key-value,调用 activeDefragAlloc 函数进行处理。
// 哈希表每个bucket进行循环扫描, 对dictEntry进行碎片整理
void defragDictBucketCallback(void *privdata, dictEntry **bucketref) {
while(*bucketref) {
dictEntry *de = *bucketref, *newde;
if ((newde = activeDefragAlloc(de))) {
*bucketref = newde;
}
// 继续处理bucket中的下一个key-value元素
bucketref = &(*bucketref)->next;
}
}
activeDefragAlloc 函数,作用是 判断哪块内存碎片化比较严重,将该内存中的数据移动到其他内存中,回收碎片化严重的内存。
// 将ptr内存移动到新的内存块上. 如果不需要移动, 返回NULL, 否则返回新地址, 老地址不可用
void* activeDefragAlloc(void *ptr) {
int bin_util, run_util;
size_t size;
void *newptr;
// jemalloc添加的方法, 帮助我们理解 那些指针值得移动, 那些不值得移动
if(!je_get_defrag_hint(ptr, &bin_util, &run_util)) {
server.stat_active_defrag_misses++;
return NULL;
}
// 用于判断是否需要进行碎片整理. 如果当前指针指向内存块的利用率 高于 平均利用率(或者已经用满), 则直接跳过
if (run_util > bin_util || run_util == 1<<16) {
server.stat_active_defrag_misses++;
return NULL;
}
// 申请新内存块, 将数据拷贝到新内存块中
size = zmalloc_size(ptr);
newptr = zmalloc_no_tcache(size); // 绕过jemalloc线程缓存, 直接分配内存块
memcpy(newptr, ptr, size);
zfree_no_tcache(ptr);
return newptr;
}
4、defragScanCallback
在处理 db 下的 hash 表时,每个 bucket 下的每个 key-value 都会调用这个函数。
void defragScanCallback(void *privdata, const dictEntry *de) {
// 根据key的不同类型 进行新内存地址的申请
long defragged = defragKey((redisDb*)privdata, (dictEntry*)de);
// 次数信息统计
}
核心是 defragKey 函数,就是先调整 key 的内存,再根据 object 的编码类型调整 value 的内存。
// 扫描整个dict, 尝试将不同类型的需要 整理内存碎片的key指针 进行存储
long defragKey(redisDb *db, dictEntry *de) {
sds keysds = dictGetKey(de);
robj *newob, *ob;
sds newsds;
// 重新调整key的内存
newsds = activeDefragSds(keysds);
// 根据object的类型 对value进行不同的调整
ob = dictGetVal(de);
if (ob->type == OBJ_STRING) {
/* Already handled in activeDefragStringOb. */
} else if (ob->type == OBJ_HASH) {
if (ob->encoding == OBJ_ENCODING_ZIPLIST) {
// ...
} else if (ob->encoding == OBJ_ENCODING_HT) {
defragged += defragHash(db, de);
}
}
// ...
return defragged;
}
下面着重看一下 hash 表类型的内存调整,流程如下:
- 如果 hash 表数量不是很多,遍历 hash 表所有的 key-value,进行碎片整理;
- redis 全局 redisObject 中 ptr 指向的 hash 表的内存整理;
- hash 表这个 redisObject 中的 ht 占用的内存整理。
总结就是,从 redisObject 开始,所有的动态内存都进行一遍整理。
long defragHash(redisDb *db, dictEntry *kde) {
robj *ob = dictGetVal(kde);
dict *d, *newd;
d = ob->ptr;
if (dictSize(d) > server.active_defrag_max_scan_fields)
defragLater(db, kde); // hash表过大, 等待下一次循环 延迟进行碎片整理, 避免影响主线程
else
activeDefragSdsDict(d, DEFRAG_SDS_DICT_VAL_IS_SDS); // hash表不是很大, 遍历hash表 进行碎片整理
// 处理hash表的 object占用的这个内存
if ((newd = activeDefragAlloc(ob->ptr)))
ob->ptr = newd;
// 处理hash表object内部的table指向的内存
defragged += dictDefragTables(ob->ptr);
return defragged;
}
上面遗留了一个问题,如果 hash 表中数量过多,避免影响主线程,会在下一次循环延迟处理。
5、defragLaterStep
这个函数是在 activeDefragCycle 主流程函数中调用的,针对之前循环中的大 object 进行处理。
// db->defrag_later存储的是比较大的object, 这里进行延迟整理, 小的object遍历时就直接处理了
int defragLaterStep(redisDb *db, long long endtime) {
static sds current_key = NULL;
static unsigned long cursor = 0;
unsigned int iterations = 0;
do {
if (!cursor) {
// 从头开始处理
listNode *head = listFirst(db->defrag_later);
if (current_key) {
// 处理完一个大object, 开始处理下一个
sdsfree(head->value);
listDelNode(db->defrag_later, head);
cursor = 0;
current_key = NULL;
}
// 处理完毕
head = listFirst(db->defrag_later);
if (!head)
return 0;
current_key = head->value;
cursor = 0;
}
dictEntry *de = dictFind(db->dict, current_key);
do {
int quit = 0;
// 真正的处理de这个object, 将内存全部拷贝一份到新的内存块中(不同类型不同处理方式)
if (defragLaterItem(de, &cursor, endtime))
quit = 1; // 超时
// 一次循环只处理一个大object
if (!cursor)
quit = 1;
// 检查是否超时 或者 处理了足够多的数据
if (quit || (++iterations > 16 || server.stat_active_defrag_hits - prev_defragged > 512 ||
server.stat_active_defrag_scanned - prev_scanned > 64)) {
if (quit || ustime() > endtime) {
return 1;
}
iterations = 0;
}
} while(cursor);
} while(1);
}
四、总结
总体逻辑:
- 遍历所有 db,遍历每个 db 的全局 hash 表;
- hash 表中的每个 key-value 都进行评估,需要处理的 进行内存碎片整理;
- 内存碎片整理时,会根据 object 的不同类型做不同的处理;
- 针对一个大 object,为了避免阻塞太久,会延迟单独处理;
- 内存碎片整理的逻辑,是重新申请一块新内存使用,释放原有内存。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)