第一章 Hadoop体系介绍
Hadoop快速入门1:Hadoop简介Hadoop 是 Apache 软件基金会旗下的一个开源的分布式计算平台。Hadoop 提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理; “处理”什么问题? 海量数据的存储和海量数据的分析计算问题。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。Hadoop 的核心组件有:Common(基础组件):(工具
第一章 Hadoop体系介绍
一、Hadoop快速入门
1:Hadoop简介
- Hadoop 是 Apache 软件基金会旗下的 一个开源的分布式计算平台。
- Hadoop 提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理;
“处理”什么问题?
海量数据的存储和海量数据的分析计算问题。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。 - Hadoop 的核心组件有:
Common(基础组件):(工具包,RPC框架JNDI和RPC。
HDFS(Hadoop Distributed File System 分布式文件系统):HDFS是以分布式进行存储的文件系统,主要负责集群数据的存储与读取。
MapReduce(Map 和 Reduce 分布式运算编程框架):“MapReduce是一种计算模型,用于大规模数据集(大于1TB)的并行计算。“Map”对数据集上的独立元素进行指定的操作,生成键值对形式中间结果;“Reduce”则对之间结果中相同“键”的所有“值”进行规约,以得到最终结果;
YARN(Yet Another Resources N 运算资源调度系统) :Hadoop2.X中的资源管理器,它可以为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
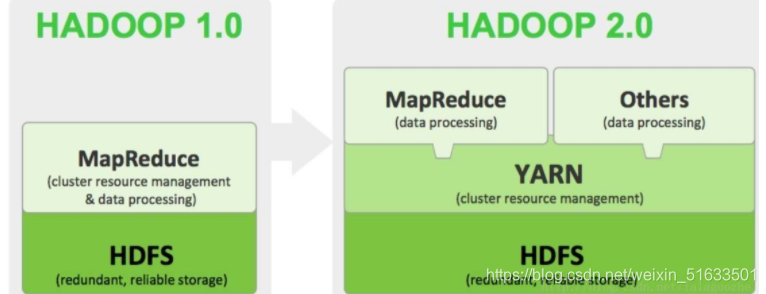
由图可以看出,Hadoop1.X内核主要由分布式存储系统(HDFS)和分布式计算框架(MapReduce)两个系统组成,而Hadoop2.X主要新增了 资源管理框架YARN。
Hadoop 1.X 生态几乎是以 MapReduce 为核心的,但是慢慢的发展,其扩展性差、资源利用率低、可靠性 等问题都越来越让人觉得不爽,于是才产生了 YARN,并且 Hadoop 2.X 生态都是以 YARN 为核心。
4. 广义上来说, Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈。
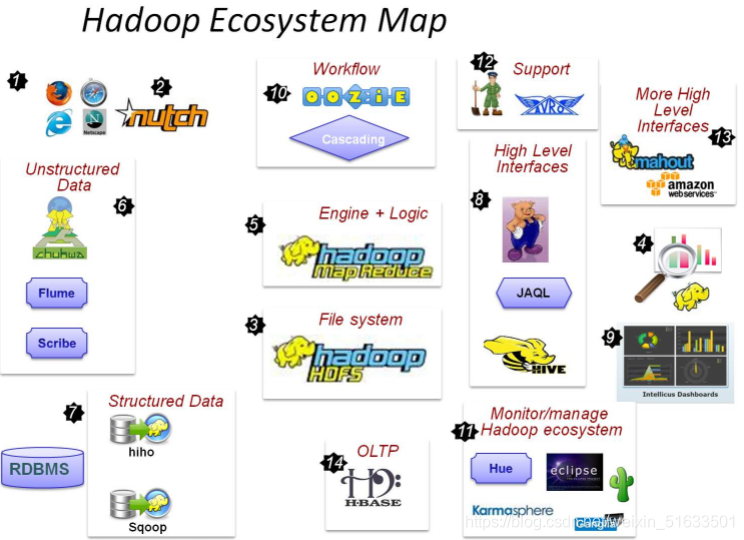
目前已经包含了多个子项目。除了核心的HDFS和MapReduce以外,Hadoop生态圈还包括Hive、ZooKeeper、HBase、Sqoop、Flume等功能组件。
Hadoop生态圈中的大部分组件的LOGO选用了动物图形,因此Hadoop的生态系统就像是一群动物在狂欢。
2.Hadoop特性
Hadoop 是一个能够让用户轻松架构和使用的分布式计算的平台。
(1)高可靠性:数据存储多个备份,集群设置在不同机器上,可以防止一个节点宕机造成集群损坏。当数据处理请求失败后,Hadoop会自动重新部署计算任务。Hadoop框架中有备份机制和校验模式,Hadoop会对出现问题的部分进行修复,也可以通过设置快照的方式在集群出现问题时回到之前的一个时间点。
(2)高扩展性:Hadoop 是在可用的计算机集群间分配数据并完成计算任务的。为集群添加新的节点并不复杂,所以集群可以很容易进行节点的扩展,扩大集群。
(3)高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(4)高容错性:Hadoop的分布式文件系统HDFS在存储文件时会在多个节点或多台机器上存储文件的备份副本,当读取该文档出错或者某一台机器宕机了,系统会调用其他节点上的备份文件,保证程序顺利运行。如果启动的任务失败,Hadoop会重新运行该任务或启用其他任务来完成这个任务没有完成的部分。
(5)低成本:Hadoop 是开源的,既不需要支付任何费用即可下载并安装使用,节省了软件购买的成本。
(6)可构建在廉价的机器上:Hadoop不要求机器的配置达到极高的水准,大部分普通商用服务器就可以满足要求,它通过提供多个副本和容错机制来提高集群的可靠性。
(7)Hadoop基本框架用Java语言编写:Hadoop含有使用Java语言编写的框架,因此运行在Linux生产平台上是非常理想的。
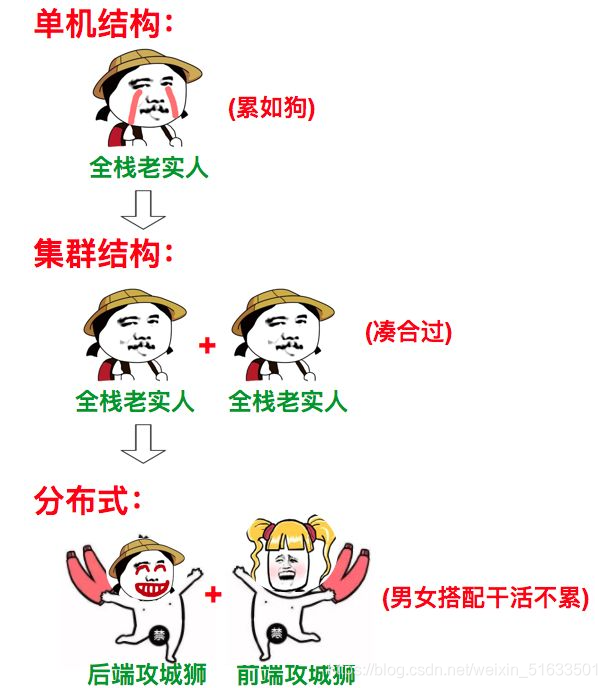
二、 分布式系统概述
1:分布式集群
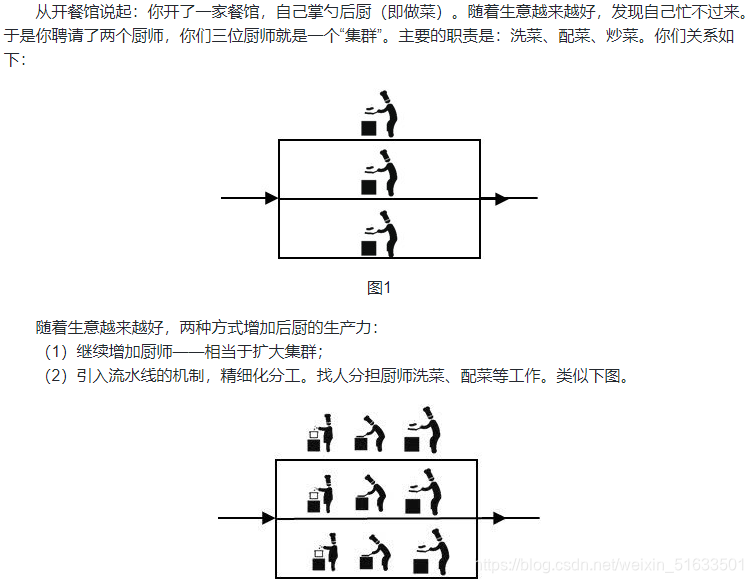
其实,流水线体现了分而治之的思想。即将一个大任务分解为多个小任务,提高小任务的生产力,从而提高了整体的生产力。而“分布式”解决问题的思路:正是吸取了将大任务分布为多个小任务的思想,才得到通过跨地域的分布解决大问题。
那么,集群和分布式的区别是什么?
(1)从解决问题的角度看:分布式是以缩短单个任务的执行时间来提升效率的;集群则是通过提高单位时间内执行的任务数来提升效率。
(2)从软件部署的角度看:分布式是指将不同的业务分布在不同的地方;集群则是将几台服务器集中在一起,实现同一业务。


**分布式中的每一个节点,都可以做集群,集群并不一定就是分布式的。**其实这个赛龙舟的图,整体来看属于分布式,包括打鼓和划桨两个分布式节点,而划桨的节点又是集群的状态。
综上所述,一个较为理想的分布式集群应该是这样的:一个分布式系统,是通过多个节点组成的,各节点都是集群化,并且个集群还是分布式的。
2:负载均衡
集群服务器之间如何分工,需要借助的是负载均衡。
负载均衡是指将请求分摊到多个操作单元也就是分开部署的服务器上,Nginx是常用的反向代理服务器,可以用来做负载均衡。集群与负载均衡之间有紧密联系,可以结合理解。
负载均衡的本质和分布式系统一样,是分治。由一个独立的统一入口来收敛流量,再做二次分发的过程就是负载均衡。
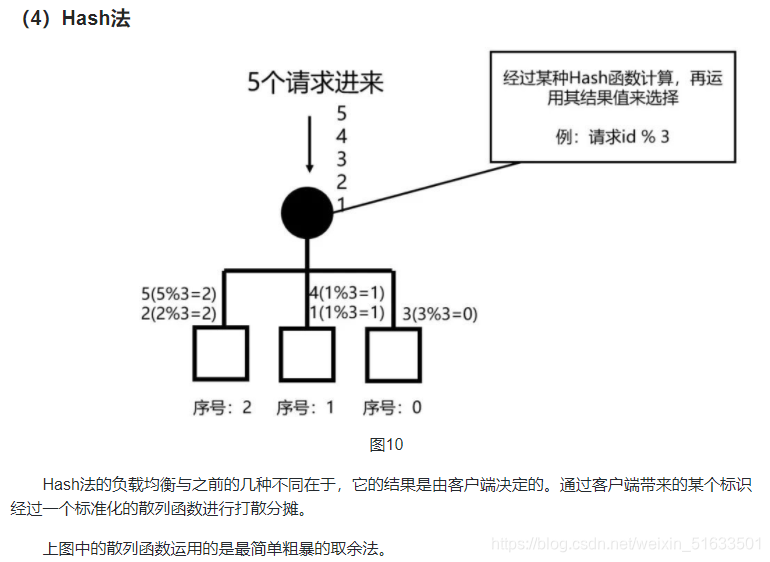
怎么均衡的背后是策略在起作用,而策略的背后是由某些算法或者说逻辑来组成的。
下面来罗列一下日常工作中最常见负载均衡策略:
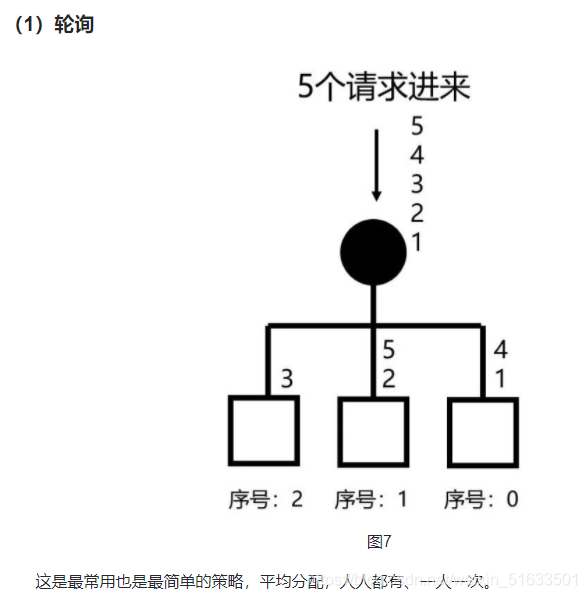

那么,负载均衡和分布式的区别又是什么?
负载均衡:请求是不可拆分的,是独立的一个请求,被服务器当中的任何一台接收并处理即可。
分布式:任何一个任务(请求)需要节点相互协作共同完成,是可以拆分的。
总结:
(1)集群
- 多个人紧密协作,来完成一个工作,就像一个人似的。
- 比如:餐馆里的所有厨师就可以看做一个集群
- 集群的好处:
- 做菜的能力比一个人时增加了
- 多招一个厨师,就能轻易增加做菜的数量(横向伸缩)
(2)分布式
- 一个任务由多个人协作完成。
- 比如:餐馆里有负责洗菜、配菜的配菜师,有专门负责做菜的厨师。
(3)负载均衡 - 将一系列任务逐项分发给多个人,完成任务的能力增加,而且让大家都不闲着(提高资源利用率),减少任务等待的时间(降低延迟)
- 比如:餐馆里做菜的厨师有多个,新的菜来了让谁做呢?
- 可以像发牌似的,一人一个轮流来(轮询)
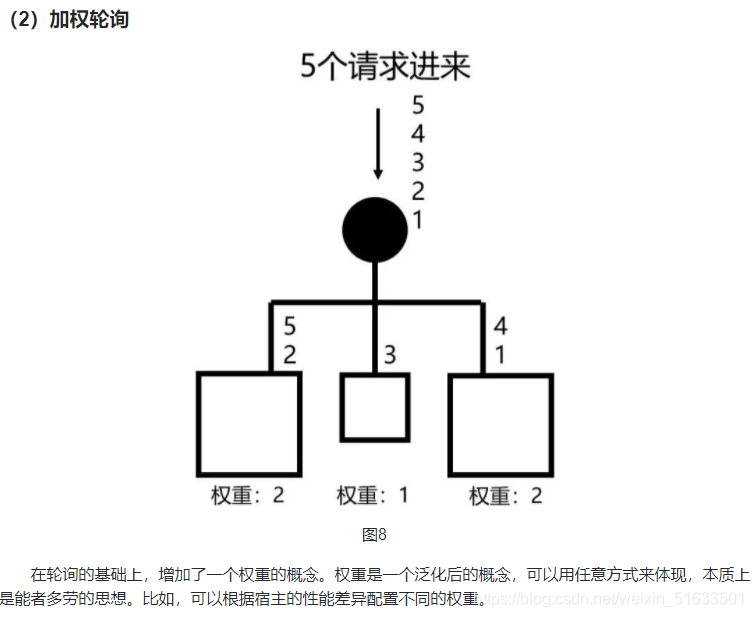
- 有人做的快,有人做的慢,可以按照一定的比例轮流(加权轮询)
三、 离线分析系统结构概述
1:需求分析
1.案例名称
XX 网/XX app 点击流日志数据挖掘系统
网站分析的主要手段是分析网站的点击流数据。
XX 网/XX app 点击流日志数据挖掘系统
网站分析的主要手段是分析网站的点击流数据。
(1)点击流的概念
点击流( Click Stream)是指用户在网站上持续访问的轨迹。 这个概念更注重用户浏览网站的整个流程。 用户对网站的每次访问包含了一系列的点击动作行为,这些点击行为数据就构成了点击流数据( Click Stream Data),它代表了用户浏览网站的整个流程。
总结:点击流其实就是用户日常浏览网站时产生的日志信息。
(2)日志规模分析
一般中型的网站(10W 以上的PV,即页面浏览量),每天会产生 1G 以上 Web 日志文件。大型或超大型的网站,可能每小时就会产生 10G 的数据量。 具体来说,比如某电子商务网站,在线团购业务。每日 PV 数 100w,独立 IP 数5w。用户通常在工作日上午 10:00-12:00 和下午 15:00-18:00 访问量最大。日间主要是通 过 PC 端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的 80%,PC 用户不足 1% 的用户会消费,移动用户有 5% 会消费。
对于日志的这种规模的数据,用 Hadoop 进行日志分析,是最适合不过的了。
2.案例需求描述
“Web 点击流日志” 包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率,访客来源信息,访客终端信息等。
网站分析基础指标:
(1)浏览量(PV)
定义:Page View,即页面浏览量或点击量,用户每打开一个页面就被记录1次。
(2)访问次数
定义:访问次数即Visit,访客在网站上的会话(Session)次数,一次会话过程中可能浏览多个页面。
(3)访客数(UV)
定义:Unique Visitor,即唯一访客数,一天之内网站的独立访客数(以Cookie 为依据 ),一天内同一访客多次访问网站只计算 1 个访客。
(4)独立IP数
定义:Internet Protocol,指独立IP数。一天之内,访问网站的不同独立IP个数加和。其中同一IP无论访问了几个页面,独立 IP 数均为 1。
3.数据来源
本案例的数据主要由用户的点击行为记录。
获取方式:在页面预埋一段 js 程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发 ajax 请求到后台 servlet 程序,用 log4j 记录下事件信息,从而在 Web 服务器(nginx、tomcat 等)上形成不断增长的日志文件。 形如:
58.215.204.118 ‐ ‐ [18/Sep/2019:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/"
"Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
字段解析:
(1)访客IP地址:58.215.204.118
(2)访客用户信息: - -
(3)请求时间:[18/Sep/2019:06:51:35 +0000]
(4)请求方式:GET
(5)请求的URL:/wp-includes/js/jquery/jquery.js?ver=1.10.2
(6)请求所用协议:HTTP/1.1
(7)响应码:304
(8)返回的数据流量:0
(9)访客的来源URL:http://blog.fens.me/nodejs-socketio-chat/
(10)访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
2:数据处理流程
- 流程图解析
整体流程如下:
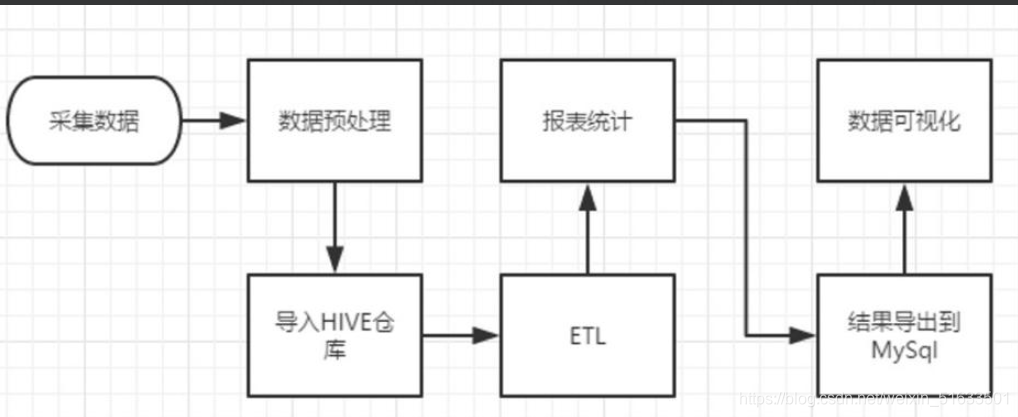
该项目是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流程进行,依此有以下几个大的步骤:
(1)数据采集:定制开发采集程序,或使用开源框架 Flume。将各服务器上生成的点击流日志通过实时或批量的方式汇聚到HDFS文件系统中。
(2)数据预处理:定制开发 MapReduce 程序运行于 Hadoop 集群。通过MapReduce 程序对采集到的点击流数据进行预处理,比如清洗、格式整理、滤除脏数据等。
(3)数据仓库技术:基于 Hadoop 之上的 Hive。将预处理之后的数据导入到Hive仓库中相应的库和表中,根据需求开发ETL分析语句,得出各种统计结果。
(4)数据导出:基于 Hadoop 的 Sqoop 数据导入导出工具 ,将 Hive中的数据导出到 MySQL等关系型数据库中。
(5)数据可视化:定制开发 Web 程序或使用 Echarts、Highcharts 等产品 。数据展现的目的是将分析所得的数据进行可视化,以便运营决策人员能更方便地获取数据,更快更简单地理解数据。
(6)整个过程的流程调度: Hadoop 生态圈中Oozie/Azkaban 工具或其他类似开源产品 - 项目整体技术架构图
由于本项目是一个纯粹数据分析项目,其整体结构亦跟分析流程匹配,并没有特别复杂的结构,如下图所示:
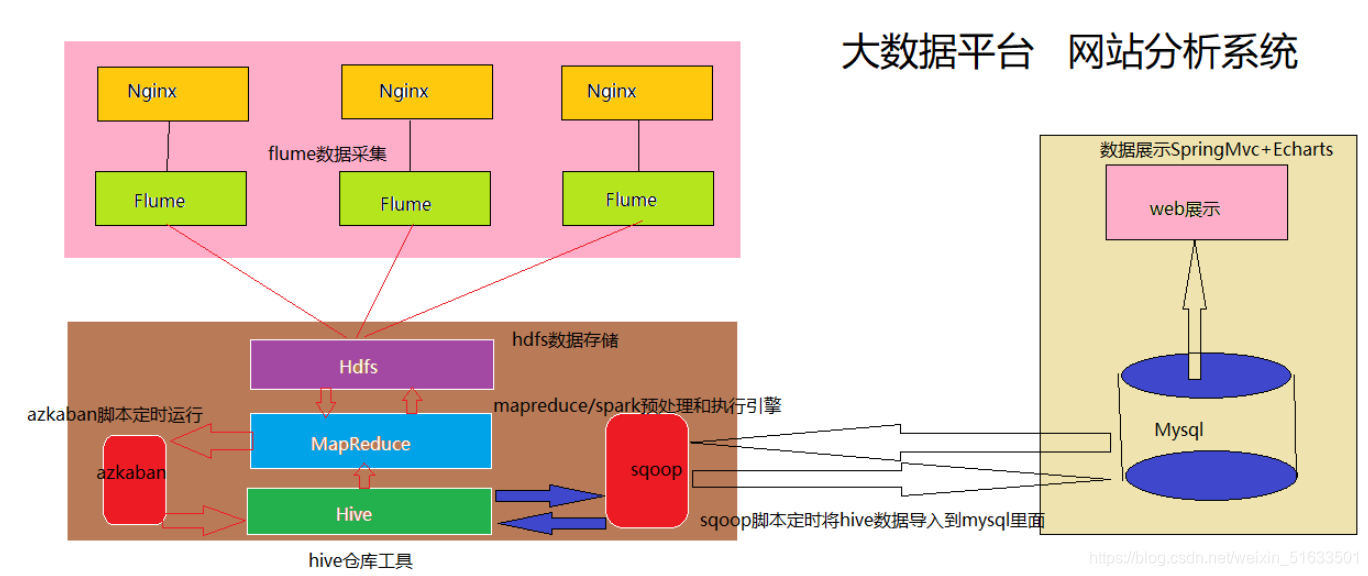
其中,需要强调的是:系统的数据分析不是一次性的,而是按照一定的时间频率反复计算,因而整个处理链条中的各个环节需要按照一定的先后依赖关系紧密衔接,即涉及到大量任务单元的管理调度,所以,项目中需要添加一个任务调度模块。 - 项目相关截图
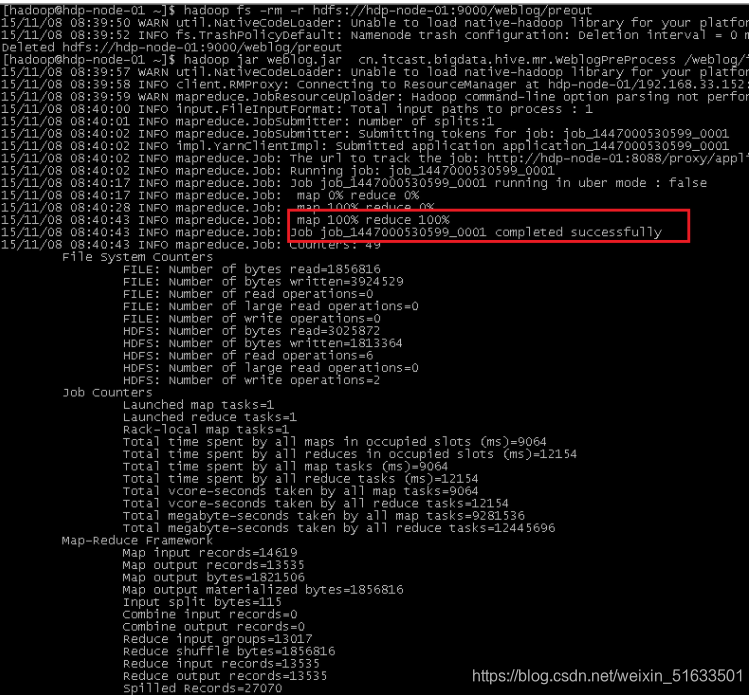
(1)MapReduce运行
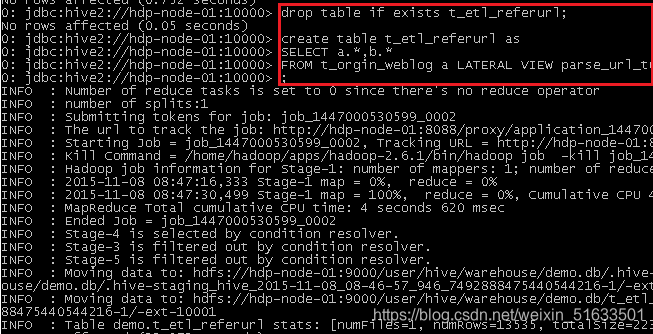
(2) 数据仓库 Hive 中查询数据
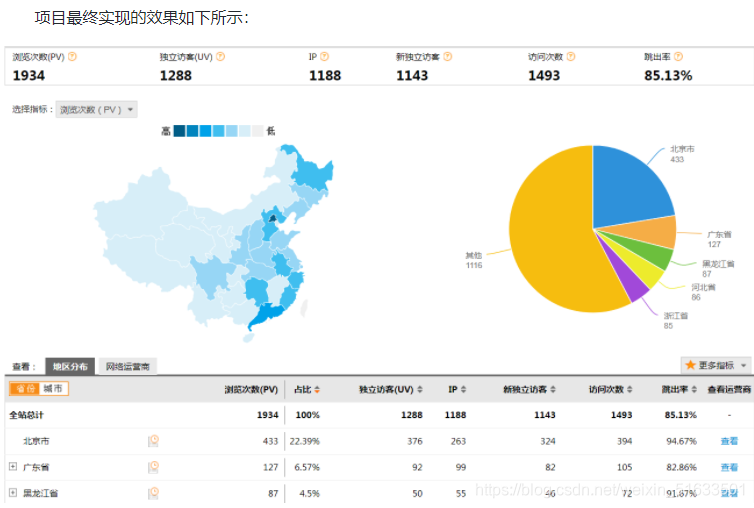
3:项目最终效果
经过复杂的数据处理流程后,会周期性输出各类统计指标的报表。在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,市面上有许多开源的数据可视化工具,比如:Echarts。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)