
Flink Table API读取Kafka数据,并将结果sink到Kafka中
最近在小破站上学Flink,跟着做 “Flink Table API读取Kafka数据,并将结果sink到Kafka中”这样一个小练习,感觉平平无奇,但是一直运行报错
最近在小破站上学Flink,跟着做 “Flink Table API读取Kafka数据,并将结果sink到Kafka中”这样一个小练习,感觉平平无奇,但是一直运行报错。内心一阵抓狂,WTF!
废话少叙,切入正题。
使用的是 Flink-1.13.0,Scala版本是 2.12,JDK版本 1.8。
开始,我是这样写的:
1.pom 依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.13.0</version>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.11.3</version>
</dependency>
</dependencies>2.代码
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2.连接kafka,读取数据
tableEnv.connect(new Kafka()
.version("0.11")
.topic("sensor")
.property("zookeeper.connect", "192.168.56.150:2181")
.property("bootstrap.servers", "192.168.56.150:9092")
) // 连接kafka
.withFormat(new Csv()) // 定义数据格式化方法: 按照Csv格式进行格式化
.withSchema(
new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temp", DataTypes.DOUBLE())
) //定义表结构
.createTemporaryTable("inputTable"); // 创建临时表
// 3.过滤数据
Table inputTable = tableEnv.from("inputTable"); // 读取出表
tableEnv.toAppendStream(inputTable, Row.class).print();
Table resultTable = inputTable.select("id, temp").filter("id === 'sensor_5'");
// 4.建立Kafka连接,将结果输出到不同的topic下
tableEnv.connect(new Kafka()
.version("0.11")
.topic("sensor_simple")
.property("zookeeper.connect", "192.168.56.150:2181")
.property("bootstrap.servers", "192.168.56.150:9092")
)// 连接kafka
.withFormat(new Csv()) // 定义数据格式化方法: 按照Csv格式进行格式化
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("temp", DataTypes.DOUBLE())
) // 定义表结构(注意:输出的表结构要与输出的数据格式对应)
.createTemporaryTable("outputTable"); // 创建临时表
// 5.结果 sink 到 kafka中
resultTable.insertInto("outputTable");
// 6.提交执行作业
env.execute();然后执行上面代码,果不其然,报错了:
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Exception in thread "main" org.apache.flink.table.api.TableException: findAndCreateTableSource failed.
at org.apache.flink.table.factories.TableFactoryUtil.findAndCreateTableSource(TableFactoryUtil.java:45)
at org.apache.flink.table.planner.plan.schema.LegacyCatalogSourceTable.findAndCreateLegacyTableSource(LegacyCatalogSourceTable.scala:193)
at org.apache.flink.table.planner.plan.schema.LegacyCatalogSourceTable.toRel(LegacyCatalogSourceTable.scala:96)
at org.apache.calcite.rel.core.RelFactories$TableScanFactoryImpl.createScan(RelFactories.java:495)
at org.apache.calcite.tools.RelBuilder.scan(RelBuilder.java:1099)
at org.apache.calcite.tools.RelBuilder.scan(RelBuilder.java:1123)
at org.apache.flink.table.planner.plan.QueryOperationConverter$SingleRelVisitor.visit(QueryOperationConverter.java:351)
at org.apache.flink.table.planner.plan.QueryOperationConverter$SingleRelVisitor.visit(QueryOperationConverter.java:154)
at org.apache.flink.table.operations.CatalogQueryOperation.accept(CatalogQueryOperation.java:68)
at org.apache.flink.table.planner.plan.QueryOperationConverter.defaultMethod(QueryOperationConverter.java:151)
at org.apache.flink.table.planner.plan.QueryOperationConverter.defaultMethod(QueryOperationConverter.java:133)
at org.apache.flink.table.operations.utils.QueryOperationDefaultVisitor.visit(QueryOperationDefaultVisitor.java:92)
at org.apache.flink.table.operations.CatalogQueryOperation.accept(CatalogQueryOperation.java:68)
at org.apache.flink.table.planner.plan.QueryOperationConverter.lambda$defaultMethod$0(QueryOperationConverter.java:150)
at java.util.Collections$SingletonList.forEach(Collections.java:4822)
at org.apache.flink.table.planner.plan.QueryOperationConverter.defaultMethod(QueryOperationConverter.java:150)
at org.apache.flink.table.planner.plan.QueryOperationConverter.defaultMethod(QueryOperationConverter.java:133)
at org.apache.flink.table.operations.utils.QueryOperationDefaultVisitor.visit(QueryOperationDefaultVisitor.java:47)
at org.apache.flink.table.operations.ProjectQueryOperation.accept(ProjectQueryOperation.java:76)
at org.apache.flink.table.planner.plan.QueryOperationConverter.lambda$defaultMethod$0(QueryOperationConverter.java:150)
at java.util.Collections$SingletonList.forEach(Collections.java:4822)
at org.apache.flink.table.planner.plan.QueryOperationConverter.defaultMethod(QueryOperationConverter.java:150)
at org.apache.flink.table.planner.plan.QueryOperationConverter.defaultMethod(QueryOperationConverter.java:133)
at org.apache.flink.table.operations.utils.QueryOperationDefaultVisitor.visit(QueryOperationDefaultVisitor.java:72)
at org.apache.flink.table.operations.FilterQueryOperation.accept(FilterQueryOperation.java:67)
at org.apache.flink.table.planner.calcite.FlinkRelBuilder.queryOperation(FlinkRelBuilder.scala:184)
at org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:203)
at org.apache.flink.table.planner.delegation.PlannerBase.$anonfun$translate$1(PlannerBase.scala:167)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
at scala.collection.Iterator.foreach(Iterator.scala:937)
at scala.collection.Iterator.foreach$(Iterator.scala:937)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1425)
at scala.collection.IterableLike.foreach(IterableLike.scala:70)
at scala.collection.IterableLike.foreach$(IterableLike.scala:69)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at scala.collection.TraversableLike.map(TraversableLike.scala:233)
at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
at scala.collection.AbstractTraversable.map(Traversable.scala:104)
at org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:167)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1516)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:738)
at org.apache.flink.table.api.internal.TableImpl.executeInsert(TableImpl.java:572)
at org.apache.flink.table.api.internal.TableImpl.executeInsert(TableImpl.java:554)
at com.simba.flink.tableapi.KafkaPipeline.main(KafkaPipeline.java:96)
Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.factories.TableSourceFactory' in
the classpath.
Reason: Required context properties mismatch.
The matching candidates:
org.apache.flink.table.sources.CsvBatchTableSourceFactory
Mismatched properties:
'connector.type' expects 'filesystem', but is 'kafka'
The following properties are requested:
connector.properties.bootstrap.servers=192.168.56.150:9092
connector.properties.zookeeper.connect=192.168.56.150:2181
connector.property-version=1
connector.topic=sensor
connector.type=kafka
connector.version=0.11
format.property-version=1
format.type=csv
schema.0.data-type=VARCHAR(2147483647)
schema.0.name=id
schema.1.data-type=BIGINT
schema.1.name=timestamp
schema.2.data-type=DOUBLE
schema.2.name=temp
The following factories have been considered:
org.apache.flink.table.sources.CsvBatchTableSourceFactory
org.apache.flink.table.sources.CsvAppendTableSourceFactory
org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory
at org.apache.flink.table.factories.TableFactoryService.filterByContext(TableFactoryService.java:300)
at org.apache.flink.table.factories.TableFactoryService.filter(TableFactoryService.java:178)
at org.apache.flink.table.factories.TableFactoryService.findSingleInternal(TableFactoryService.java:139)
at org.apache.flink.table.factories.TableFactoryService.find(TableFactoryService.java:93)
at org.apache.flink.table.factories.TableFactoryUtil.findAndCreateTableSource(TableFactoryUtil.java:41)
... 43 more
Process finished with exit code 1
网上一通乱搜,结果发现,也没找到解决方法,但是我知道 tableEnv.connect 这个方法在V1.12已经过期了,我现在用的 Flink-1.13.0,可能版本太高,已经用不了了,于是根据热心市民的建议,改用官方提供的新方法:executeSql

于是,代码变成了下面这样:
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2.连接kafka,读取数据
tableEnv.executeSql(
"create table inputTable(" +
"`id` STRING," +
"`timestamp` BIGINT," +
"`temp` DOUBLE" +
")with(" +
"'connector' = 'kafka'," +
"'topic' = 'sensor'," +
"'properties.zookeeper.connect' = '192.168.56.150:2181'," +
"'properties.bootstrap.servers' = '192.168.56.150:9092'," +
"'properties.group.id' = 'testGroup'," +
"'scan.startup.mode' = 'earliest-offset'," +
"'format' = 'csv'," +
"'csv.field-delimiter' = ','" +
")");
// 3.过滤数据
Table resultTable = tableEnv.sqlQuery("select id, temp from inputTable where id = 'sensor_5'");
// 4.建立Kafka连接,将结果输出到不同的topic下
tableEnv.executeSql(
"create table outputTable(" +
"`id` STRING," +
"`temp` DOUBLE" +
")with(" +
"'connector' = 'kafka'," +
"'topic' = 'sensor_simple'," +
"'properties.zookeeper.connect' = '192.168.56.150:2181'," +
"'properties.bootstrap.servers' = '192.168.56.150:9092'," +
"'properties.group.id' = 'testGroup'," +
"'scan.startup.mode' = 'earliest-offset'," +
"'format' = 'csv'," +
"'csv.field-delimiter' = ','" +
")");
// 5. sink
resultTable.executeInsert("outputTable");
env.execute();再次执行,不出所料,又是报错,不过这次错误不一样了,说明方向是对的,哈哈哈哈。
错误信息很长,这里摘录下面一句:
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'csv' that implements 'org.apache.flink.table.factories.DeserializationFormatFactory' in the classpath.
很明显,是说找不到 CSV 格式描述器,可是我明明引入:

查看下当前环境中 org.apache.flink.table.factories.DeserializationFormatFactory 接口的实现类,发现只有 RawFormatFactory 一个,估计是我引的CSV 格式描述器版本不对,于是引一个更高版本:

再查看 DeserializationFormatFactory 的实现类,发现了Csv版本的:

再次执行代码,上面的问题没了,但是,又抛出一个新异常:
Caused by: java.lang.NoSuchMethodError: org.apache.flink.table.factories.DynamicTableFactory$Context.getCatalogTable()Lorg/apache/flink/table/catalog/CatalogTable;
at org.apache.flink.streaming.connectors.kafka.table.KafkaDynamicTableFactoryBase.createDynamicTableSource(KafkaDynamicTableFactoryBase.java:81)
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:128)
... 19 more分析下,是 KafkaDynamicTableFactoryBase.java 这个类少方法,这个类又是flink-kafka 的连接器提供的,推测应该也是版本的问题。

引入高版本的连接器:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<!--<version>1.11.3</version>-->
<version>1.13.0</version>
</dependency>再次运行,控制台还是有报错,但是可以正常运行:
生产输入测试:

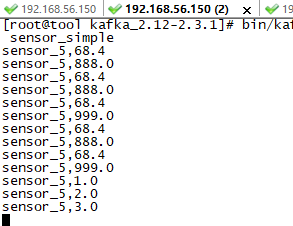
消费 sensor_simple topic,可以接收到数据:
控制台错误:
Exception in thread "main" java.lang.IllegalStateException: No operators defined in streaming topology. Cannot execute.
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraphGenerator(StreamExecutionEnvironment.java:2019)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:2010)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:1995)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1834)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1817)
at com.simba.flink.tableapi.KafkaPipeline.main(KafkaPipeline.java:96)网上搜了一下,有人说是由于executeSql已经是异步提交了作业,生成Transformation后会把缓存的Operation清除,见TableEnvironmentImpl#translateAndClearBuffer,执行execute也会走那一段逻辑,报了上面异常,但是这个异常不影响程序执行。
那么,我把这行注掉,再试下

果然可以了:
producer:

consumer:

终于,解决了!轻松些许,哈哈哈!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)