

一、MongoDB 数据库定位
首先我们来看一下 MongoDB 是什么样的数据库。数据库分两大类:
- OLTP(Online Transaction Processing)联机事务处理。
- OLAP(On-Line Analytical Processing)联机分析处理。
OLTP 指手机应用、网页应用,有交互式的。需求数据库能够提供毫秒级的响应。
OLAP 指可以在晚上跑一个批,做分析处理,跑完以后把结果写到表里面,第二天来拿结果。
OLTP 和 OLAP 最大的区别就是时效性的区别。
MongoDB 是 OLTP 型的数据库,跟 Oracle、MySQL、SQL Server 等 OLTP 型 数据库对标。MySQL 能做的事情,MongoDB 都可以做,只不过做法不一样。从 MongoDB 4.0 开始完全支持跟交易相关的强事务。
MongoDB 的三个优点:
- 第一,横向扩展能力,数据量或并发量增加时候架构可以自动扩展。MongoDB 是原生的分布式数据库,通过分片技术,可以做到 TB 甚至 PB 级的数据量,以及数千数万数十 万到百万级的并发,或者是连接数等等。MySQL 就需要一些特定的分库分表,或者第三方的解决方案。
- 第二,灵活模型,适合迭代开发,数据模型多变场景。现在的开发都是讲究快速迭代,往往在第一个版本出来的时候,需求是不完整的,这个时候有一个比较灵活的、不固定结构的数据库,在开发时间上会节省非常多。
- 第三,JSON 数据结构,适合微服务/REST API。REST API 的后面其实都是我们现在用的都是一种 REST 或者 JSON 的数据结构,而 MongoDB 是一种非常原生的支持。
二、选型考量
基于技术需求选择 MongoDB
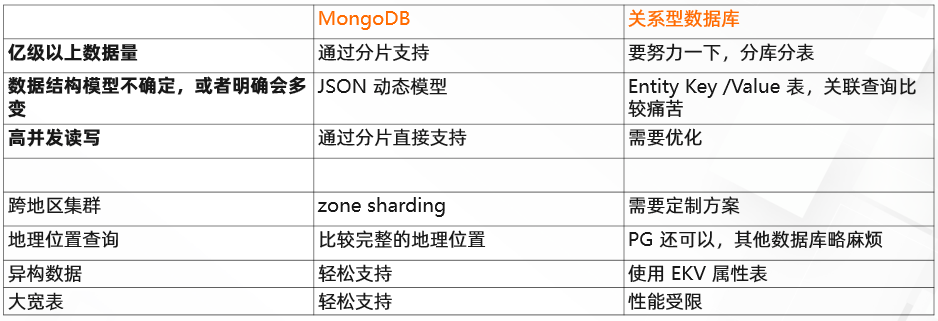
第一个指标:数据量。假设单表里面要保存的处理数据超过亿或者 10 亿的级别,而且使用挺频繁,这个时候就可以考虑使用 MongoDB。这种场景下如果用 MySQL 做分库分表,效率、稳定性、可靠性肯定没法跟 MongoDB 相比。
第二个指标,数据结构模型不确定,或者明确会多变。比如迭代开发的场景下, MongoDB 允许过程中快速迭代,不需要去修改它的 Schema,继续可以支持你的业务。
第三个指标,高并发读写,MongoDB 通过分片直接支持。比如线上应用,网上可能 是有很大很多的用户一起使用,并发性会非常高,这个时候考虑到 MongoDB 的分布式分片集群,可以支撑非常大的并发。基于单机的,比如说 Oracle、MySQL、SQL Server 可能都会有很大的瓶颈。
其他还有一些场景可以选择 MongoDB,如跨地区集群、地理位置查询、轻松支持异构数据与大宽表做海量数据的分析, MongoDB 都是非常明显的优势。
基于场景选择 MongoDB
基于场景选择 MongoDB 比较常见的有:移动/小程序 APP、电商、内容管理、物联 网、SaaS 应用、主机分流、实时分析、数据中台等。
移动应用: 对互联网公司来说,移动/小程序 APP 是必不可少的,它的特点是: 它是基于 REST API/JSON 进行交互,采用的是互联网公司的迭代式开发,两个星期一个迭代、 一个版本,著名的互联网公司每天都会出版本,月月新、周周新、天天新,手机移动的场景 下,会有非常多的地理位置。 成功的 APP 用户往往不是几万几十万,甚至百万千万上亿, 像微信、字节、抖音等移动应用场景, MongoDB 都能够支撑。

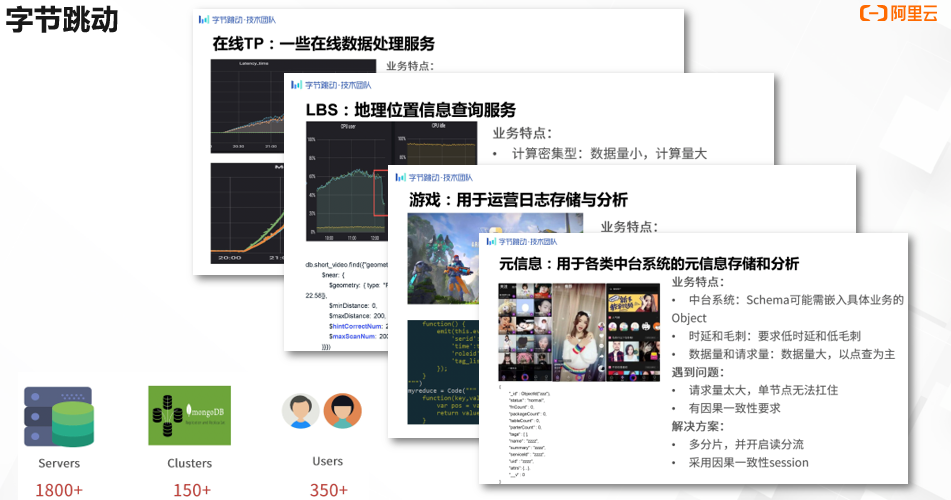
字节跳动: 字节去年的分享,一年前的时候,他们正在大量的迁移 MySQL 的应用到 MongoDB 上面来。主要的考量就是并发量和数据量达到一定地步以后,MySQL 集群的性能不能稳定工作,毛刺比较多。另外就是扩容困难,和业务迭代速度跟不上。他们一天要发布几十个版本,即使 DBA 响应时间再快,也快不过迭代,DBA 就干脆把这个步骤省掉。 字节的场景非常多,去年就已经有 150 多个集群,350 多个用户项目。今年应该更多了。 他们使用的场景有几大类,在线 TP 业务,和地理位置相关的查询业务,游戏,以及中台系统的元数据信息等,都需要通过 MongoDB 支撑。
主机分流/读写分离:这个场景在金融行业比较常见。
金融行业的特点是业务系统、交易系统用的很多的都是 IBM 或者小型机,上面运行 DB2 或者比较老的关系数据库。特点是按量付费,它并不是买断的,每读一次写一次都有 额外的计费,叫 MIPS。最近几年,银行在做大量手机端的开发,把交易数据放到手机端,手机端对交易数据的读的流量猛增。根据某个银行的统计,现 99%的流量都是读流量,对成本增加非常高。
还有关系业务模型改动非常困难,想去创新,想去增加一些新的业务,需要非常高的成本。有一个策略,是把这些数据拿出来,做读写分离,用另外一种数据库来支持这种读。
在这样的场景下,MongoDB 是非常好的选择。相比关系数据库 MongoDB 是基于内存的一种读写,它的分布式可以把海量数据、几年的历史数据拿过来放到热数据库里面,让其支撑手机端的交易查询。比如海外的花旗银行,国内的中国银行。

主机分流案例:中国银行
业务需求是在手机银行里支撑历史交易数据的查询,其他的金融日历应用。比如查询三年的账单,三年数据每天都有 6000 万,月末的时候还有几个亿,加上三年算下来有几百几千亿的数据,是非常海量的数据。他们最终是选择了 MongoDB 分片集群来做这样的事情。

上图所示是架构图,首先它的借记卡系统和信用卡系统是基于 Oracle 做的,使用 CDC 的技术,是实时数据库同步的机制,把数据从库里边:“增删改”都拿出来,然后通 过 Spark 进行计算处理,然后放到 MongoDB 的集群里面,再变成 JSON 文件的格式, 再通过 API 的后端,把数据暴露出去给手机 APP 的前端。
通过这种方式,数据实时的从主机系统同步过来,通过 API 的方式,可以提供非常高效率、高性能的查询给到手机 APP,保证用户的体验。这种场景是比较常见的金融数据的查询库,很多银行都在使用。
数据中台 它的架构是把企业多个业务系统数据汇聚到一个中台,通过治理服务出去,快速的提高企业的业务响应能力,形成大中台小前端的方式。
场景特点:
• 多源系统数据汇聚场景,数据模型多样化。
• 存储量较大,需要能够分布式存储。
• 快速业务响应能力意味着快速数据建模和快速发布。
• 支持企业所有业务系统的数据需求,查询性能需要保证。
基于数据中台场景的特性,MongoDB 的结构非常适合多元数据的聚合。比如大的差 异性字段,字段的个数、属性的个数、都是不一样的。这个时候建一张新的 Schema 允许过程中快速迭代,不需要去修改它的 Schema 结构是非常困难的。通过 JSON 的这种动态模型,很容易把它结合起来。MongoDB 的横向扩展能力,可以让一套系统支撑多套业 务系统的数据存储。 MongoDB 还有内存缓存的读写能力,或者是快速高并发的读能力,可以支撑数据中台业务。
MongoDB 选型考量总结:
• JSON 动态结构支持异构数据非常轻松。原生的横向扩展能力(通过分片)。
• 基于内存缓存的读写能力,可以提供多套业务系统使用同一份数据。
三、场景举例
数据中台案例 —— 周生生全渠道实时数据服务平台:
周生生珠宝在中港台澳各地有数百家门店,在建立数据服务平台之前,中广台澳各地有很多套业务系统,有销售、库存、商品、会员等等,数据散落在这些系统中间,并没有统一。
订单跨地业务,需要完整的最新的库存信息。
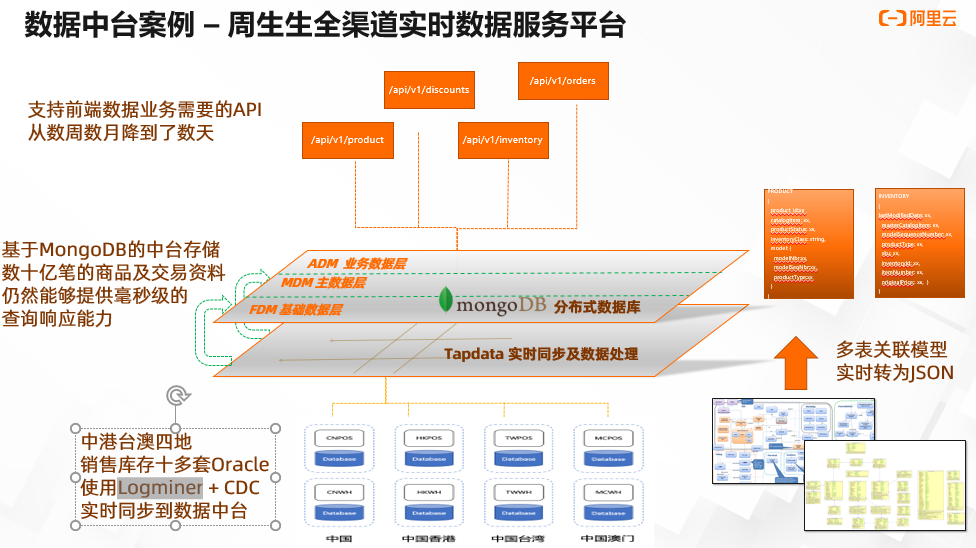
基于这些构建了数据中台系统,使用 Tapdata 实时同步功能,基于 Logminer 和 CDC 机制,把数据从 Oracle 里面把它抽出来,实时同步到 MongoDB。过程中采用实时处理能力,把基于关系模型的各种多表合并成一个 JSON,实时的固化视图放在 MongoDB 里面。它的价值就是能够存储数十亿笔资料,同时能够提供毫秒级的响应。
另外一点,提供中港台跨地区分布,保证用户能够最快访问数据。然后结合 API 能力, 让前端开发小程序的时候,原先需要几个星期几个月,通过中台可以降到数天, 整个效率 提高非常多。这些都依赖于 MongoDB 数据库非常强的整合能力和查询能力,也是中台所需要数据的特性。如下图所示:
实时分析
场景的特点:
• 个性化、推荐系统、标签等场景需要对所有用户进行海量计算,效率很低且数据不实时。
• 采用实时分析可以针对性的分析,并且数据实时。
• 要求快速计算,秒级响应。
• 数据库系统需能够支撑大量数据,及快速数据聚合分析能力。
比如,晚上他会把全量的用户行为数据整个跑一遍,结合其他的数据跑出一些个性化的 标签,然后放到一个关系库里面。 第二天当你访问就会得到结果。
这种做法有缺陷,效率很低。因为活跃用户比例很低,所以每天晚上都在跑 100%的用户,对计算资源的需求非常大,其中 90%的数据都是没用的,因为很多用户没有登陆使用。 所以有些实时的场景推进系统,比如根据你第一个网页点击的内容,给你推荐一些相关的信息,这个时候就没法做到了。
MongoDB 可以做快速的聚合性计算,做统计分析,得到这种结果,推荐相应的信息。 另外如果给足够的内存,也可以在内存里面计算。
MongoDB 选型考量:
• 使用 MongoDB 缓存机制,利用内存计算加速。
• 使用 MongoDB 聚合框架,实现统计分析功能。
• 使用 MongoDB 的灵活结构存储中间结果。
• 满足大多数简单实时统计分析场景。
世界顶级航旅服务商:亿级数据量实时分析
世界级的这种航旅服务商可以支撑世界上大部分的航空公司的票务查询、订票、选票、 票价计算等等场景。
每天要处理 16 亿的预定等相关的请求与分析。所谓的分析就是要根据用户查询的目的 地、时间段,推荐比较合适的路线,或者相应的航旅产品酒店之类。如果想事先计算,100 多家航空公司的所有会员,用户量太大,根本没法计算。
另外一种场景,使用 MongoDB 实时计算能力,在几十台物理机上部署了很多的微分 片,把数据打散在这些机器上,当有需求过来,可以通过并行机制,很快的把用户的数据基于 ID、目的地、时间段进行过滤,输入的分析数据就比全量数据少了几个数量级。通过 MongoDB 的实时数据分析能力,得出推荐的结果。

电商
电商场景的特点是:商品信息特别多不好管理,因为不同的商品有非常不同的属性,大家去过淘宝京东就知道了,信息是包罗万象。数据库模式设计困难,当并发访问量大的时候,压力也是非常大。
• 商品信息包罗万象。
• 商品的属性不同品类差异很大。
• 数据库模式设计困难。
• 并发访问量大,特别是促销。
MongoDB 在电商场景下有非常独特的优势,JSON 动态模型,可以允许同一张商品表里面有不同的字段类型。比如同一张表可以有自行车、衣服、电脑,电脑可能是有 50 个 字段,自行车可能有 30 个字段,衣服可能有 20 个字段都没问题。
MongoDB 选型考量总结:
• JSON 模型无需固定格式,可以记录不同商品属性。
• 可变模型适合迭代。
• 并发性能保证。
• 京东商城 / 小红书 / 思科。
世界顶级网络设备生产商:电商平台重构
思科是一个做网络设备的公司,两年前把基于 Oracle 的电商系统,整个迁移到了 MongoDB 上面,这是每年几百亿美元的流水,包括商品信息、订单、用户交互。
迁移过来以后,14 个关系型表集合成 1 个集合,非常高效。 60 个索引优化到 7 个, 因为表的数量少了,效率增加了非常多。代码量减少了 12 万。之前的 3~5 秒页面刷新时间 降低了小于一秒,都是非常实际的价值呈现。

内容管理是博客、营销系统、内容管理系统,涉及到的都是非结构化、半结构化、多结构化的数据管理。
• 内容数据多样,文本,图片,视频。
• 扩展困难,数据量爆发增长。
传统数据库只能做结构化数据。当有文本、PDF、音频、视频需要统一管理,关系数据库就吃力了。MongoDB 的 JSON 可以支持各种结构的数据,甚至二进制的数据,文本、 日志更不在话下,它的分片结构可以支撑海量数据。
所以 Gartner 魔力象限里面最顶上的两位,Adobe AEM 和 Sitecore 两个 CMS 文档管理系统的软件,都是用的 MongoDB 来做数据管理和存储。
MongoDB 选型考量总结:
• JSON 结构可以支持非结构化数据。
• 分片架构可以解决扩展问题。 Adobe AEM / Sitecore。
物联网的场景特点是:
• 传感器的数据结构往往是半结构化
• 传感器数量很大,采集频繁
• 数据量很容易增长到数亿到百亿
首先它有非常多的传感器,每个传感器都是不同厂家提供的,它并没有标准的数据模型。 管理看上去是一个传感器,但实际上它有非常不同的数据类型和属性。这个时候有 JSON 模型就非常有优势。
另外传感器是机器数据,频繁的时候可以每秒都一次,5 秒一次,甚至每 100 毫秒一 次,数据不断的进到系统里面。如果没有能够支撑高并发海量数据的系统,是无法支撑数据库的,数据很快就增长了百亿、千亿级
因为这个原因,类似于华为 / Bosch / Mindsphere 这些著名的物联网平台,后面都是采用 MongoDB。 MongoDB 选型考量总结:
• JSON 结构可以支持半结构化数据 使用分片能力支撑海量数据
• JSON 数据更加容易和其他系统通过 REST API 进行集成 华为 / Bosch / Mindsphere
MongoDB 什么时候不太适用?
• MongoDB 模型设计不建议太多分表设计,关联能力较弱。
• 传统数据仓库:建立各种维度表,然后使用大量关联进行分析。
• 大型 ERP 软件,一级数据对象数量较多(超过数十数百),必须依赖于各种关联。
• 数据结构模型非常成熟固定,并且数据量不大,如财务系统。MongoDB 的弹性模型 和分布式没有意义。团队没有 MongoDB 能力,也没有时间让工程师学习新技术。







 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)