Redis学习笔记(最全!)
常用类型及使用场景String类型常用命令: set,get,mget ,decr,incr等。(写入值,取值,数值+1,数值-1)使用场景:普通存值List类型常用命令:lpush,rpush,lpop,rpop,lrange等。(从头插入,从尾插入,从头删除一个并返回元素,从尾删除第一个并返回元素,返回范围结果)使用场景:比如粉丝列表,关注等等列表信息实现方式:Redis list的实现为一个
什么是redis
redis是一种k-v存储形式的 nosql型数据库,常用的数据类型有五种,String,list,set,zset,hash,根据不同的场景可以选择不同的存储类型去使用;redis的数据是可以设置过期时间的,也可以做持久化数据的操作,持久化数据的方式主要有两种RDB和AOF,并且基于redis的特性也可以做分布式锁,还可以解决项目中的一些业务场景问题。
免费客户端下载链接:https://github.com/lework/RedisDesktopManager-Windows/releases
value常用类型及使用场景
String类型
常用命令: set,get,mget ,decr,incr等。
(写入值,取值,数值+1,数值-1)
使用场景:普通存值
List类型
常用命令:lpush,rpush,lpop,rpop,lrange(取指定位置的值),阻塞获取
(从头插入,从尾插入,从头删除一个并返回元素,从尾删除第一个并返回元素,返回范围结果)
使用场景:比如粉丝列表,关注等等列表信息
实现方式:
Redis list的实现为一个双向链表,可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Hash类型
常用命令:hget,hset,hgetall 等。
value是类似于map,多个feild+value
(获取指定值,设置值,取出所有值)
使用场景:一般存储对象都是用Hash类型来存
set类型
常用命令:sadd,srem,spop,smembers,sunion,sinter
(添加元素,删除元素,获取所有元素,获取两个set的并集,获取两个set的交集)
使用场景:因为有求并集交集的方法,并且所存储的元素不可重复,所以可以很方便的实现共同好友,共同关注等应用场景

zset类型
常用命令:zadd,zrange,zrem,zcard等
(添加元素,返回指定区间内的元素,用于移除有序集中的一个或多个成员,用于计算元素个数)
使用场景:可以做带权重的队列b,然后按序获取任务

redis的持久化机制
实现方式有两种:分别是RDB和AOF。
RDB:就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上
聊一聊RDB:
RDB的方式就是通过快照的方式去将数据完整的存储在磁盘上,在快照过程中,会生成一个临时文件,当持久化过程结束后才会去替换上次持久化的临时文件。并且快照过程是创建了一个子进程去执行的,并且主进程会停止IO操作,这样会更加高效。
当然也是有弊端的,比如设置了每隔五分钟去快照保存一次,当redis发生故障的时候,那么也有可能会丢失这五分钟的数据,所以有另一种持久化机制那就是AOF。
AOF:则是换了一个角度去持久化数据,就是将写命令去全部存储起来,当你重启的时候再把这些命令执行一遍,这样数据就恢复了
聊一聊AOF:
AOF方式很简单,就是将所有写命令存储起来,我们通过配置redis.conf中的appendonly yes就可以打开AOF功能,默认的AOF持久化策略是每一秒中记录一次,所以即便故障也只会丢失这一秒钟的数据。因为是采用追加的方式,所以AOF文件会越来越大,如果不做任何处理那么磁盘空间很可能被存满,为此,redis提供了AOF文件重写机制,当AOF超过设定的阈值,那么redis就会启用AOF文件内容压缩,只保留可以恢复数据的最小指令集。当恢复时出现错误,还可以使用redis提供的redis-check-aof工具去校验修复。
(重写机制)
首先会创建一个子进程去读取当前AOF文件进行重写,重写到一个临时文件中。主进程会将新收到的写命令一遍写入到缓存区,一遍写入到原来的AOF文件中,这样保证了原来AOF文件的可用性,当子进程重写结束后,会将缓存区中新的写命令追加到新的AOF文件中,然后将新的AOF与旧的AOF文件进行替换。
总结
这两种方式是可以同时使用的,如果redis重启,那么将优先使用AOF的方式去恢复数据,因为这样恢复的数据更加完整,当然如果没有持久化的需求,那么就可以关闭,作为一个纯内存数据库,就像memcache一样
主从结构
Redis是支持主从同步的,也支持一主多从,主从结构一是为了纯粹的冗余备份,二是为了提高读的效率。
Redis的主从同步是异步执行的,所以不会降低Redis的效率
主从架构中,可以考虑关闭主服务器的数据持久化功能,只让从服务器进行持久化,这样可以提高主服务器的处理性能。一般从服务器都会设置为只读模式,这样可以防止数据被误修改。
Redis集群的几种方式
主从模式
特点:
-
主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库
-
从数据库一般都是只读的,并且接收主数据库同步过来的数据
-
一个master可以拥有多个slave,但是一个slave只能对应一个master
-
slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来
-
master挂了以后,不影响slave的读,但redis不再提供写服务,master重启后redis将重新对外提供写服务
-
master挂了以后,不会在slave节点中重新选一个master
机制:当slove启动的时候,会向master发送SYNC指令,并进行RDB快照和缓存快照期间的命令,然后将快照文件跟缓存的命令在slove执行、复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。
缺点:
从上面可以看出,master节点在主从模式中唯一,若master挂掉,则redis无法对外提供写服务。
Sentinel模式(哨兵模式)
特点:
- 哨兵模式是建立在主从模式上的
- 当master挂掉后会从slove中选取出新的master,并且会修改配置文件,其他slove的配置文件也会被修改
- 当原来的master重启后也将不再是master,而会变成slove,然后去同步新的master的数据
- 一个sentinel或sentinel集群可以管理多个主从Redis,多个sentinel也可以监控同一个redis
- sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了
机制:
1.每个sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个 PING 命令也就是心跳机制
2.如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被sentinel标记为主观下线。
3.如果一个master被标记为主观下线,那么所有监控它的哨兵会再次发送命令来确认是否为主观下线
4.当有足够多数量的哨兵确认它为主观下线后,就会被标记为客观下线,并对主服务器执行故障转移。
Cluster模式(集群模式)
当数据量过大的时候,会使用该模式
特点
- 多个redis节点网络互连
- 每一个节点都是一主一从或一主多从的结构,从库不提供服务,仅作为备份
- 客户端可以连接任意节点进行读写
RedisTemplate之opsForValue使用说明
1.set(K key, V value)
新增一个字符串类型的值,key是键,value是值。
redisTemplate.opsForValue().set("stringValue","bbb");
2、get(Object key)
获取key键对应的值。
String stringValue = redisTemplate.opsForValue().get("key")
3、append(K key, String value)
在原有的值基础上新增字符串到末尾。
redisTemplate.opsForValue().append("key", "appendValue");
String stringValueAppend = redisTemplate.opsForValue().get("key");
System.out.println("通过append(K key, String value)方法修改后的字符串:"+stringValueAppend);
4、get(K key, long start, long end)
截取key键对应值得字符串,从开始下标位置开始到结束下标的位置(包含结束下标)的字符串。
String cutString = redisTemplate.opsForValue().get("key", 0, 3);
System.out.println("通过get(K key, long start, long end)方法获取截取的字符串:"+cutString);
``
## 5、getAndSet(K key, V value)
获取原来key键对应的值并重新赋新值。
```java
String oldAndNewStringValue = redisTemplate.opsForValue().getAndSet("key", "ccc");
System.out.print("通过getAndSet(K key, V value)方法获取原来的值:" + oldAndNewStringValue );
String newStringValue = redisTemplate.opsForValue().get("key");
System.out.println("修改过后的值:"+newStringValue);
6、setBit(K key, long offset, boolean value)
key键对应的值value对应的ascii码,在offset的位置(从左向右数)变为value。
redisTemplate.opsForValue().setBit("key",1,false);
newStringValue = redisTemplate.opsForValue().get("key")+"";
System.out.println("通过setBit(K key,long offset,boolean value)方法修改过后的值:"+newStringValue);
7、getBit(K key, long offset)
判断指定的位置ASCII码的bit位是否为1。
boolean bitBoolean = redisTemplate.opsForValue().getBit("key",1);
System.out.println("通过getBit(K key,long offset)方法判断指定bit位的值是:" + bitBoolean);
8、size(K key)
获取指定字符串的长度
Long stringValueLength = redisTemplate.opsForValue().size("key");
System.out.println("通过size(K key)方法获取字符串的长度:"+stringValueLength);
9、increment(K key, double delta)
以增量的方式将double值存储在变量中。
double stringValueDouble = redisTemplate.opsForValue().increment("doubleKey",5);
System.out.println("通过increment(K key, double delta)方法以增量方式存储double值:" + stringValueDouble);
10、increment(K key, long delta)
以增量的方式将long值存储在变量中。
double stringValueLong = redisTemplate.opsForValue().increment("longKey",6);
System.out.println("通过increment(K key, long delta)方法以增量方式存储long值:" + stringValueLong);
11、setIfAbsent(K key, V value)
如果键不存在则新增,存在则不改变已经有的值。
boolean absentBoolean = redisTemplate.opsForValue().setIfAbsent("absentKey","fff");
System.out.println("通过setIfAbsent(K key, V value)方法判断变量值absentValue是否存在:" + absentBoolean);
if(absentBoolean){
String absentValue = redisTemplate.opsForValue().get("absentKey")+"";
System.out.print(",不存在,则新增后的值是:"+absentValue);
boolean existBoolean = redisTemplate.opsForValue().setIfAbsent("absentKey","eee");
System.out.print(",再次调用setIfAbsent(K key, V value)判断absentValue是否存在并重新赋值:" + existBoolean);
if(!existBoolean){
absentValue = redisTemplate.opsForValue().get("absentKey")+"";
System.out.print("如果存在,则重新赋值后的absentValue变量的值是:" + absentValue);
12、set(K key, V value, long timeout, TimeUnit unit)
设置变量值的过期时间。
redisTemplate.opsForValue().set("timeOutKey", "timeOut", 5, TimeUnit.SECONDS);
String timeOutValue = redisTemplate.opsForValue().get("timeOutKey")+"";
System.out.println("通过set(K key, V value, long timeout, TimeUnit unit)方法设置过期时间,过期之前获取的数据:"+timeOutValue);
Thread.sleep(5*1000);
timeOutValue = redisTemplate.opsForValue().get("timeOutKey")+"";
System.out.print(",等待10s过后,获取的值:"+timeOutValue);
13、set(K key, V value, long offset)
覆盖从指定位置开始的值。
redisTemplate.opsForValue().set("absentKey","dd",1);
String overrideString = redisTemplate.opsForValue().get("absentKey");
System.out.println("通过set(K key, V value, long offset)方法覆盖部分的值:"+overrideString);
14、multiSet(Map<? extends K,? extends V> map)
设置map集合到redis。
Map valueMap = new HashMap();
valueMap.put("valueMap1","map1");
valueMap.put("valueMap2","map2");
valueMap.put("valueMap3","map3");
redisTemplate.opsForValue().multiSet(valueMap);
15、multiGet(Collection keys)
根据集合取出对应的value值。
//根据List集合取出对应的value值
List paraList = new ArrayList();
paraList.add("valueMap1");
paraList.add("valueMap2");
paraList.add("valueMap3");
List<String> valueList = redisTemplate.opsForValue().multiGet(paraList);
for (String value : valueList){
System.out.println("通过multiGet(Collection<K> keys)方法获取map值:" + value);
}
16、multiSetIfAbsent(Map<? extends K,? extends V> map)
如果对应的map集合名称不存在,则添加;如果存在则不做修改。
Map valueMap = new HashMap();
valueMap.put("valueMap1","map1");
valueMap.put("valueMap2","map2");
valueMap.put("valueMap3","map3");
redisTemplate.opsForValue().multiSetIfAbsent(valueMap);
启动客户端命令
redis-cli.exe -h 127.0.0.1 -p 6379
缓存穿透
指:客户端的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,请求就都会打到数据库
解决方案:
1.缓存空对象
优点:(简单粗暴)
缺点:可能造成短期的不一致,额外消耗内存
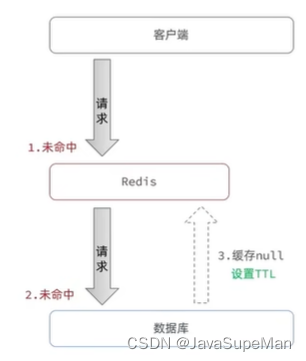
2.布隆过滤器
它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
优点:内存占用少,没有多余的key
确定:实现复杂,存在误判可能

3.基础校验
可以根据要查询的key,做基础的校验过滤,过滤掉不可能存在的key
缓存雪崩
指在同一时段大量的缓存key同时过期或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
解决方案:
1.给不同的key的TTL添加随机值
2.利用Redis集群提高服务的可用性
3.给缓存业务添加降级限流策略
4.给业务添加多级缓存
缓存击穿
缓存击穿问题也叫热点key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击,失效原因主要是设置了TTL
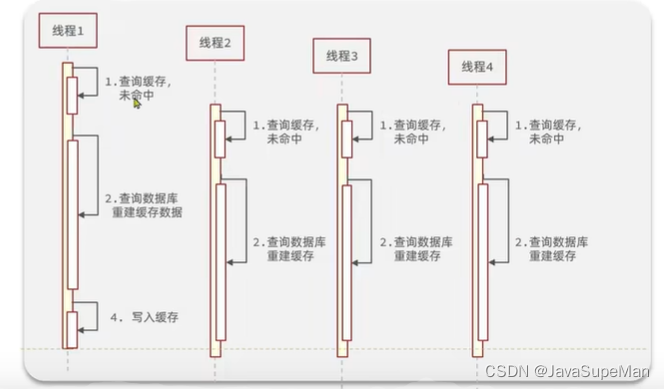
主要思想就是让key永不过期!
解决方案:
1.使用互斥锁,在缓存重建阶段持有锁才可以操作
(可以基于Redis实现互斥锁,SETNX)
优点:强一致性,实现简单,没有额外的内存消耗
确定:线程需要等待,性能受影响,可能有死锁风险

2.逻辑过期
在value里增加一个字段用来存储过期时间,并且重建缓存数据通过异步执行,先返回过期数据
优点:线程无需等待,性能较好
缺点:不保证一致性,有额外内存消耗,实现复杂

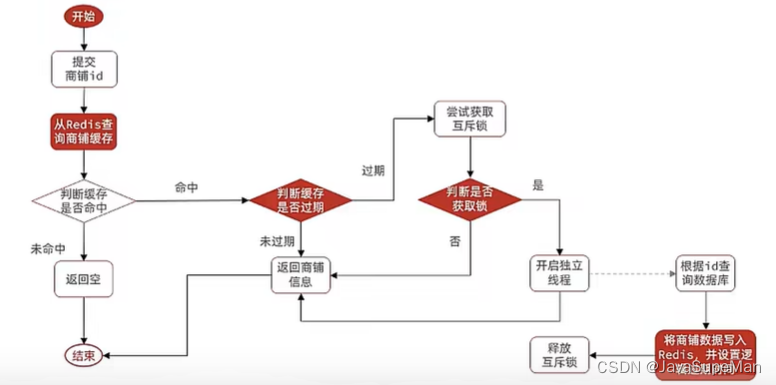
3.定时检查热点key并更新过期时间

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容
 免费领云主机
免费领云主机


 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)