终于知道了Zookeeper在hbase集群中的作用
<configuration>...<property><name>hbase.zookeeper.property.clientPort</name><value>2222</value><description>Property from ZooKeeper's config zoo.cfg.The port
1.Hbase集群组件架构
Hbase集群主要的服务组件是Zookeeper,Hmaster和RegionServer。其中Hbase集群强依赖与Zookeeper提供的服务.为什么Hbase离不开ZK?
1.1Zookeeper在Hbase集群中的作用
Apache ZooKeeper是一个用于分布式协调的客户端/服务器系统,它公开一个类似于文件系统的接口,其中每个节点(称为znode)可能包含数据和一组子节点。每个 znode 都有一个名称,可以使用类似文件系统的路径(例如,/root-znode/sub-znode/my-znode)进行标识。节点创建完以后ZK会去追踪节点的状态。
在 Apache HBase 中,ZooKeeper 在 Masters 和 RegionServers 之间协调、通信和共享状态。HBase 的设计策略是仅将 ZooKeeper 用于瞬态数据(即用于协调和状态通信)。因此,如果 HBase 的 ZooKeeper 数据被删除,只会影响临时操作——数据可以继续写入/读取 HBase。
Zookeeper集群在Hbase集群中主要作用有如下几个:
- 实现Hmaster节点的高可用管理,HA
- 对集群所有RegionServer状态监控,宕机后会通知Hmaster;每个RS启动时都会在ZK上注册,然后master会去监控这个znode
- 分布式一致锁的提供,保证数据写入的事务性,表的删除,新建,更新需要维护全局锁
- 维护管理了Hbase相关元数据信息
其实配置zk集群和hbase集群的搭配使用,核心配置文件不多,主要就是Hbase zk集群节点信息,通信端口等。
<configuration>
...
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>
<description>Property from ZooKeeper's config zoo.cfg.
The port at which the clients will connect.
</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>rs1.example.com,rs2.example.com,rs3.example.com,rs4.example.com,rs5.example.com</value>
<description>Comma separated list of servers in the ZooKeeper Quorum.
For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost for local and pseudo-distributed modes
of operation. For a fully-distributed setup, this should be set to a full
list of ZooKeeper quorum servers. If HBASE_MANAGES_ZK is set in hbase-env.sh
this is the list of servers which we will start/stop ZooKeeper on.
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
<description>Property from ZooKeeper's config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
...
</configuration> 那么zookeeper到底在hbase集群中起到的作用需要后者强依赖于它呢,我们可以登录zookeeper集群,看下上面都有哪些变化,如下ls /hbase目录,我们可以看到/hbase目录下有很多子目录,下面我们详细分析一下这些目的作用,这也是zk在hbase集群中作用的体现。
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha, hbase]
[zk: localhost:2181(CONNECTED) 1] ls /hbase
[meta-region-server, rs, splitWAL, backup-masters, table-lock,
flush-table-proc, master-maintenance, online-snapshot, switch,
master, running, draining, namespace, rsgroup, hbaseid, table]
1.1.1 meta-region-server
meta-region-server 是维护hbase:meta表所在的节点信息。在Hbase集群中会维护一个hbase:meta表,这个表是集群中所有region的相关信息,包括region所在RS节点,region的rowkey范围,以及region所在表名,列值等信息。
这个bhase:meta表其实就是一个表的形式存储在hbase中的,只是这个表只有一个region,不切分;一般这个表/region不大,比如一个集群几十万个region的hbase:meta表也只有几百兆的大小。有些教程还有什么root:meta表,其实在hbase0.98之后,hbase就废弃了root表,仅保留meta表(还有namespace,这个类似于mysql中数据库吧,多租户时隔离表用),并且该meta表不允许split。
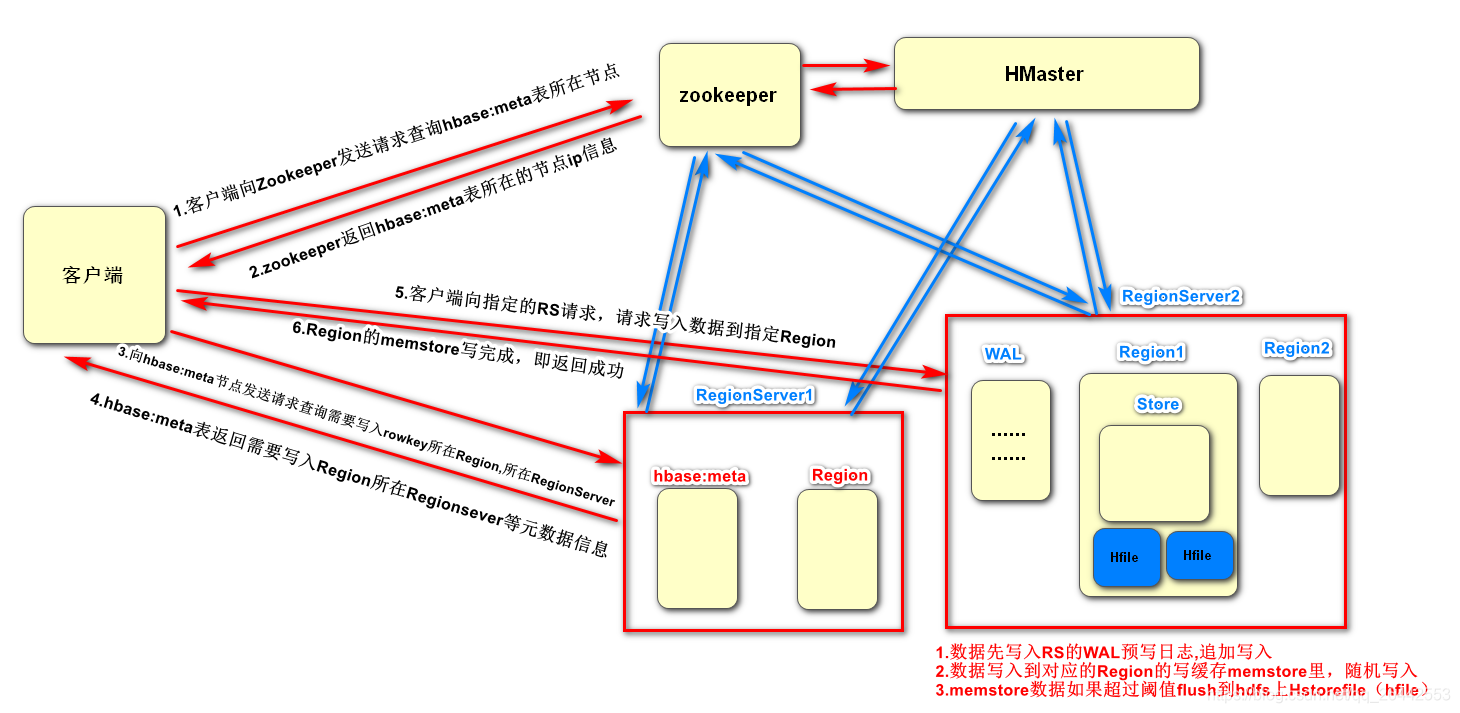
这个hbase:meta表或者说这个region也会存储在hbase节点上,具体存储在哪个节点上我们需要维护一下,这件事就是ZK干的(因为是region就可能因为RS的挂掉,负载均衡等移动位置。Hmaster在启动时会将hbase:meta表加载到ZK集群)。所以用户CRUD表时需要先去ZK上找到这个hbase:meta元数据表存在哪个节点上,然后在去跟这个节点通信,获取对应的元数据信息。如下图往hbase写一条数据ZK对元数据管理的作用

如下,我们在zk上get /hbase/meta-region-server,看下,发现habse:meta表存储在10.21.129.48这个节点上。很多人会有疑问,这个meta表既然这么重要为啥不直接向hive一样弄个元数据库存一下,或者指定节点存储这个meta表,大家都指定访问这个ip去请求元数据不就行了嘛?干嘛还有通过zk多一层查询?
[zk: localhost:2181(CONNECTED) 5] get /hbase/meta-region-server
�master:16000�
�T9�
�PBUF
*
10-21-129-48-jhdxyjd.mob.local�}��Ċ�/
cZxid = 0xc0012cae2
ctime = Wed Mar 17 23:46:56 CST 2021
mZxid = 0x110020d849
mtime = Wed Jun 16 09:54:38 CST 2021
pZxid = 0xc0012cae2
cversion = 0
dataVersion = 17
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 77
numChildren = 01.1.2 rs
rs就比较简单了,就是保存了hbase集群中的所有存活RegionServer的节点,RS每个节点在启动时会去该/hbase/rs目录下注册,注册一个属于自己的临时节点。如果节点超时,就会被清理,Hmaster也会去监听状态,这样RS下线就会知道,好将对应的region转移走。
[zk: localhost:2181(CONNECTED) 7] ls /hbase/rs
[10-90-48-217-jhdxyjd.mob.local,16020,1624976906164, 10-90-48-215-jhdxyjd.mob.local,16020,1625031043975,
10-21-129-47-jhdxyjd.mob.local,16020,1616003544583, 10-21-129-50-jhdxyjd.mob.local,16020,1616003544064, 10-90-48-216-jhdxyjd.mob.local,16020,
1616003544204, 10-21-129-48-jhdxyjd.mob.local,16020,1616003544351, 10-90-50-69-jhdxyjd.mob.local,16020,1623810752097, 10-90-50-68-jhdxyjd.mob.local,16020,1625036813762, 10-21-129-49-jhdxyjd.mob.local,16020,1625025595518, 10-90-48-214-jhdxyjd.mob.local,16020,1625037902449]
---查看具体节点下的信息
[zk: localhost:2181(CONNECTED) 12] get /hbase/rs/10-90-48-217-jhdxyjd.mob.local,16020,1624976906164
�regionserver:16020[�34��dPBU�}�
2.1.0-cdh6.1.0Wfi+e:///c-++ai+e_._edha+7/b+i+d/cdh/hba_e/2.1.0-cdh6.1.0/_-+/BUILD/hba_e-2.1.0-cdh6.1.0U+++-++"+e++i+_*Th+ Dec 6 16:59:58 PST 20182 1d0b6db6b151eb26a67d5c6b3e6a29998@
cZ|id = 0|1100265e4d
c+i+e = T+e J++ 29 22:28:29 CST 2021
+Z|id = 0|1100265e4d
++i+e = T+e J++ 29 22:28:29 CST 2021
-Z|id = 0|1100265e4d
c+e__i-+ = 0
da+aVe__i-+ = 0
ac+Ve__i-+ = 0
e-he+e_a+O++e_ = 0|578414c9bc3370e
da+aLe+g+h = 232
+++Chi+d_e+ = 0
[z+: +-ca+h-_+:2181(CONNECTED) 13] 1.1.3 splitWAL
望文生义,splitWAL切分RegionServer中的预写日志HLOG/WAL。所以这个是为了提高故障转移效率使用的。就是Master可以要求集群中所有的RegionServer未回放日志的切分,提高故障转移效率。而ZK主要用来协调Master和RS使用的。
[zk: localhost:2181(CONNECTED) 4] ls /hbase
[meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, master-maintenance, online-snapshot, switch, master, running, draining, namespace, rsgroup, hbaseid, table]
[zk: localhost:2181(CONNECTED) 5] get /hbase/splitWAL
cZxid = 0xc0012ca7f
ctime = Wed Mar 17 23:45:59 CST 2021
mZxid = 0xc0012ca7f
mtime = Wed Mar 17 23:45:59 CST 2021
pZxid = 0x11002159ae
cversion = 18
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 01.1.4 backup-masters
记录集群中备份Master的节点信息,当Master挂了后故障转移使用的,比如主master挂了,zookeeper就会通过选举机制,从备master中选举出来一个当主master角色。比如我这个集群有三个备份master。这个主要就是用来保证Master HA机制的。
[zk: localhost:2181(CONNECTED) 9] ls /hbase
[meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, master-maintenance, online-snapshot, switch, master, running, draining, namespace, rsgroup, hbaseid, table]
[zk: localhost:2181(CONNECTED) 10] ls /hbase/backup-masters
[10-90-50-49-jhdxyjd.mob.local,16000,1616003829600, 10-90-50-48-jhdxyjd.mob.local,16000,1616003957172,
10-90-48-146-jhdxyjd.mob.local,16000,1616003544404]1.1.5 table-lock
Zookeeper在分布式系统中的一大核心作用就是提供了分布式锁,保证每次操作的事务性。我们都知道Hbase中表的存储是分布式存储的,一张表分多个region存储在不同的RegionServer上,那么如果我们通过多个客户端同时操作一个表,如何在分布式的情况下保证表数据的准确性呢?所以客户端每次在对表的DDL之前都需要先获取表的全局锁,防止多个操作互相冲突。最终实现单次操作的原子性,要么都成功,要么都失败,进而保证分布式数据的准确性。而这个分布式全局锁的提供者就是zookeeper。
[zk: localhost:2181(CONNECTED) 12] get /hbase/table-lock
cZxid = 0xc0012ca81
ctime = Wed Mar 17 23:45:59 CST 2021
mZxid = 0xc0012ca81
mtime = Wed Mar 17 23:45:59 CST 2021
pZxid = 0xc0012ca81
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 01.1.5 flush-table-proc
[zk: localhost:2181(CONNECTED) 14] ls /hbase
[meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, master-maintenance, online-snapshot, switch, master, running, draining, namespace, rsgroup, hbaseid, table]
[zk: localhost:2181(CONNECTED) 15] ls /hbase/flush-table-proc
[abort, acquired, reached]1.1.6 table
这个很重要,存放了Hbase集群中所有表信息。
[zk: localhost:2181(CONNECTED) 18] ls /hbase/table
[ga:device_period_bssid_list_202006, ga:device_period_bssid_list_202007, ga:device_period_bssid_list_202008, ga:device_period_bssid_list_202009, ga:gapoi_device_mapping_sec, ga:rp_gapoi_ieid_pid_device, ga:rp_gapoi_device_samewifi_202101, ga:rp_gapoi_device_samewifi_202102,,,,,,,,,,,,,,,,,,1.1.7 namespace
namespace类似于mysql中的数据库概念,在hbase中主要区分多租户时做表空间的逻辑隔离;
[zk: localhost:2181(CONNECTED) 26] ls /hbase/namespace
[default, ga, hbase]1.18 draining/hbaseid
draining用于通过创建具有serverName,port,startCode形式的子znode,就是/habse/rs下的子节点信息(如,/hbase/draining/10-90-48-216-jhdxyjd.mob.local,16020,
1616003544204)这使您可以停用多个 RegionServers,而不会存在将区域临时移动到稍后将停用的 RegionServer 的风险。
hbaseid其实就hbase集群的唯一标识符。因为我们可以将一个zk集群共享,供多个hbase集群复用,所以要唯一标识一个集群。
1.19online-snapshot
用来实现在线snapshot操作,杂Hbase中Master下达snapshot命令、RegionServer反馈snapshot结果都是通过ZooKeeper完成的。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)