flink回撤流分析
flink回撤流
Flink SQL 更新数据含有回撤数据的问题
案例问题一
问题描述
CREATE TABLE kafka_source (
`policy_id` BIGINT ,
`premium` int ,
`gmt_created` TIMESTAMP(3)
) WITH (
'format.type'='json',
'connector.type'='kafka',
'connector.version'='0.11',
'connector.topic'='data-flink-test-blcs-201912301523',
'connector.properties.bootstrap.servers'='kafka.test.za.net:9092',
'connector.properties.group.id'='local'
);
create view kafka_source_last_value as
select
policy_id,
LAST_VALUE(premium) as premium,
LAST_VALUE(gmt_created) as gmt_created
from kafka_source
group by `policy_id`
;
create table print_sink (
`date_str` varchar,
`policy_count` bigint,
`premium_sum` bigint,
primary key (date_str)
) with (
'connector.type'='print'
);
insert into print_sink
select
date_format(gmt_created, 'yyyy-MM-dd') as date_str,
count(policy_id) as policy_count,
sum(premium) as premium_sum
from kafka_source_last_value
group by date_format(gmt_created, 'yyyy-MM-dd');
-
输入数据顺序为
{“policy_id”:1, “premium”:1000, “gmt_created”:”2020-09-15 12:00:00”} {“policy_id”:2, “premium”:1500, “gmt_created”:”2020-09-15 12:00:03”} {“policy_id”:1, “premium”:1300, “gmt_created”:”2020-09-15 12:00:05”} -
期望的输出结果是
(true,2020-09-15,1,1000) (true,2020-09-15,2,2500) (true,2020-09-15,2,2800) -
实际的输出结果是
(true,2020-09-15,1,1000) (true,2020-09-15,2,2500) (true,2020-09-15,1,1500) (true,2020-09-15,2,2800)问题分析
问题点
-
在发送第三条数据的时候,因为要取LastValue, flink的数据发出了一条回撤数据,然后再新发一条新的数据更新统计结果
-
自定义的RichSinkFunction的在上游推送数据的invoke方法内往下游存储引擎写出了回撤数据
临时解决方案
- 参考flink官方的flink-jdbc实现方法,自定义的RichSinkFunction实现CheckpointedFunction接口
并实现snapshotState方法,在invoke方法内使用HashMap基于数据的key缓存上游推送的数据,
并在checkpoint触发时把HashMap一次写出到下游存储引擎 - 带来的问题就是数据输出的频率依赖checkpoint触发频率,如果checkpoint频率设置的过高,一方面将导致checkpoint存储压力加大,
特别是基于hdfs的存储方案,另一方面对于大state的任务,频繁的checkpoint将消耗大量时间用于checkpoint的操作而导致没有足够的时间
去消费数据处理数据
案例问题二
问题描述
CREATE TABLE individual_product (
gmt_created TIMESTAMP(3),
product_code VARCHAR,
product_type INT,
standard_premium BIGINT,
free_premium BIGINT
) WITH (
'format.type'='json',
'connector.type'='kafka',
'connector.version'='0.11',
'connector.topic'='individual-product',
'connector.properties.bootstrap.servers'='127.0.0.1:9092'
);
create view normal_product_view as
select
date_format(gmt_created, 'yyyy-MM-dd') as create_date,
count(product_code) as product_count,
sum(standard_premium) as premium_sum
from individual_product
where product_type = 1
group by date_format(gmt_created, 'yyyy-MM-dd');
create view free_product_view as
select
date_format(gmt_created, 'yyyy-MM-dd') as create_date,
count(product_code) as product_count,
sum(standard_premium - free_premium) as premium_sum
from individual_product
where product_type = 2
group by date_format(gmt_created, 'yyyy-MM-dd');
create view product_view as
select
create_date,
product_count,
premium_sum
from normal_product_view
union all
select
create_date,
product_count,
premium_sum
from free_product_view;
CREATE TABLE product_sink (
create_date VARCHAR ,
product_count BIGINT,
premium_sum BIGINT
) WITH (
'connector.type'='print'
);
insert into product_sink
select
create_date,
sum(product_count) as product_count,
sum(premium_sum) as premium_sum
from product_view
group by create_date;
-
输入数据顺序为
{"gmt_created":"2020-09-27 12:00:00", "product_code":"app_01", "product_type":1, "standard_premium":1000, "free_premium": 30} {"gmt_created":"2020-09-27 12:00:01", "product_code":"app_02", "product_type":2, "standard_premium":1500, "free_premium": 50} {"gmt_created":"2020-09-27 12:00:03", "product_code":"app_03", "product_type":1, "standard_premium":1100, "free_premium": 30} {"gmt_created":"2020-09-27 12:00:09", "product_code":"app_04", "product_type":2, "standard_premium":1200, "free_premium": 40} {"gmt_created":"2020-09-27 12:00:10", "product_code":"app_05", "product_type":1, "standard_premium":1600, "free_premium": 70} {"gmt_created":"2020-09-27 12:00:13", "product_code":"app_06", "product_type":1, "standard_premium":1200, "free_premium": 10} {"gmt_created":"2020-09-27 12:00:20", "product_code":"app_07", "product_type":2, "standard_premium":1300, "free_premium": 30} -
实际的输出结果是
{"state":"upsert","data":{"create_date":"2020-09-27","product_count":1,"premium_sum":1000}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":2,"premium_sum":2450}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":1,"premium_sum":1450}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":3,"premium_sum":3550}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":2,"premium_sum":2100}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":4,"premium_sum":4710}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":2,"premium_sum":2610}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":5,"premium_sum":6310}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":2,"premium_sum":2610}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":6,"premium_sum":7510}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":4,"premium_sum":4900}} {"state":"upsert","data":{"create_date":"2020-09-27","product_count":7,"premium_sum":8780}}问题分析
问题点
-
由于两个union的结果计算逻辑不一致且都有回撤的数据,union之后回撤的情况更加频繁了,写出到下游存储引擎回撤的情况更加严重,业务几乎不能正常使用
-
flink官方的flink-jdbc实现内,既基于checkpoint触发频率写出数据,又基于目前数据累积是否达到一批数据的条数写出数据,当中间回撤
数据和后续的更新数据分在了两个批次写到下游储存引擎将会导致问题
临时解决方案
- 无
产生回撤数据的原因
-
在解释原因之前,首先需要先了解一些概念,当flinkSQL中有聚合逻辑时,流处理就会以聚合的字段为Key持续的产生更新的数据。
比如上面的例子,date_str就是key,根据每一个key,premium的数据会持续计算更新。而更新的策略有Acc和AccRetract两种模式。
retractionTraits.scala -
Acc模式。 当lastValue发现policy1的premium从1000更新为1600的时候,向下游的operator发送一条数据true,policy1,1600的数据,所以Acc模式就是指当数据产生更新时,只将更新后的这条数据下发的模式。
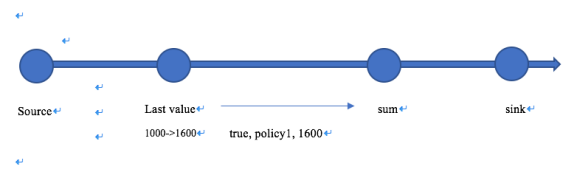
-
AccRetract模式。 当lastValue发现policy1的premium从1000更新为1600的时候,向下游的operator发送两条数据,第一条是更新前的数据false,policy1,1000;第二条更新后的数据true,policy1,1600的数据,这种方式称为AccRetract模式。这边false代表撤回1000这条数据,true代表下发1600这条数据。
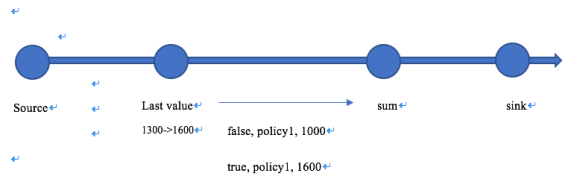
-
这也就很好的解释了premium为什么没有从2300直接变成2900。而是先变成1300再变成2900这一过程。因为sum先收到了-1000的消息(也就是撤回更新前premium为1000的数据),然后再收到+1600的消息,两次计算分别输出两条数据1300和2900。
那为什么不能通过Acc的模式直接发一条数据计算呢?为什么要那么复杂发两条数据计算,因为做不到,在lastValue算子里面维护了一个map用来保存每一条保单的历史记录,所以当接收到policy1,1600的记录的时候是知道数据更新前是什么样的,但是在sum这边只维护了当前的总计值,
所以当它接收到policy1,1600记录之后,他并不知道这条记录是一条新记录还是已有数据的更新值?更新前的值又是什么,所以必须由上游的算子告诉他们。所以flink使用Acc模式,还是使用AccRetract模式,不是用户可以选择的,是flink自己判断的,
而判断的基准是某个算子的下游还有聚合算子依赖当前算子的计算结果,通俗的讲就是当SQL逻辑出现两个以上的聚合,并且有嵌套的关系,就会变成AccRetract模式,所以随着SQL的逻辑越来越复杂,
内部回撤的数据也会越来复杂,尤其是使用了union之类的语法之后,中间计算结果的频繁输出严重的影响了业务的使用。
基于checkpoint触发写出是如何解决中间回撤数据问题的?
- 先让我们了解一下checkpoint的是如何执行的,而说到checkpoint就必须先说一下它的核心组件checkpointBarrier,让我们一起看看它是如何保证数据的完整性的。
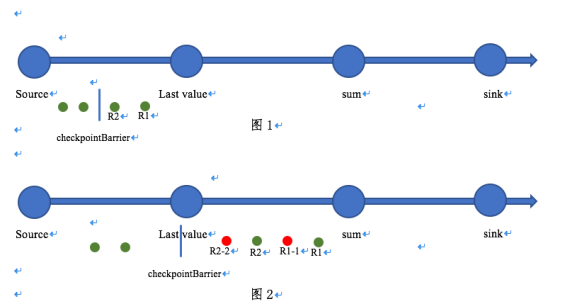
- 图1的R1,R2分别是两条数据,后面的竖线是checkpointBarrier。
- 图2的R1-1和R1-2是经过LastValue之后分列出来的回撤数据。
checkpointBarrier是由source端定时下发到数据处理的pipeline的,这个频率由checkpoint设置的频率决定。对齐的checkpointBarrier能够将数据分成一个个数据段,
不同的数据段的数据不可能越过checkpointBarrier来到另一个数据段。当checkpointBarrier到达各个算子的时候就会触发checkpoint的执行,整个checkpoint的执行大致分为两个阶段:
- 准备阶段:比如调用我们上文中提到的所有实现snapshotState接口的方法等,创建异步执行checkpoint等对象。
- 执行阶段:将RocksDB的state数据异步写入到HDFS。
而这两个阶段当中,阶段一是同步的,所以checkpointBarrier会阻塞后面的数据,确保每一个算子的执行都是一个完整的数据。而第二部分是真正的checkpoint写入阶段,通过rocksDB的接口触发数据flush到HDFS上面,整个写入是异步执行。这就是为什么基于checkpoint写入数据可以解决数据的完整性。
如何既能解决中间回撤数据问题又能及时的写出数据?
-
基于checkpoint的原理,我们就可以设计出一种新的事件,我们称为transactionBarrier,流程其实和checkpointBarrier相似,但是更加轻量级,省略了不必要的工作,只保留了对齐和写数据的触发。
过程如图: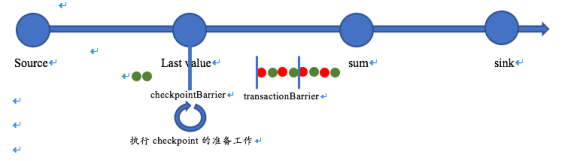
-
相对短细的竖线代表transactionBarrier;
-
相对粗长的竖线代表checkpointBarrier;
transactionBarrier也是source端定时触发的,我们默认设置500毫秒,它和checkpointBarrier有三个相同点: -
会将数据分成一个个数据段,不会越过前面的数据,也不被后面的数据超越,所以保证了数据的完整性;
-
会做数据对齐工作,对齐工作是内存操作,对性能影响微乎其微;
-
同步触发snapshotState方法,而snapshotState主要是执行批量写数据,这个和SinkFunction的invoke方法中同步执行批量写数据是同样的道理。所以即使高频触发transactionBarrier也不会带来性能影响。
-
不同点在于:
-
跳过了snapshotState以外的几乎所有同步执行的准备阶段的工作。
-
跳过了checkpoint的执行阶段。
所以transactionBarrier整个执行过程更轻量级。可以高频的触发,性能影响更小。这样就可以将写数据的时效性和checkpoint的频率区分开,做到低频的checkpoint触发,高频的数据写操作。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)