实现Kafka的优先级消费
优先级消费是业务中经常碰到的场景。对于同一类消息,消息内容可能由于其业务上的属性不同,而具有不同的“重要程度”,比如在一个消息推送系统中,一条告警消息显然比一条营销消息重要的多,我们希望即使队列中已经有了大量消息的情形下,优先级更高的消息,仍能够实现“插队”的优先消费,以保证更重要的消息不回被低优先级的消息阻塞。
优先级消费是业务中经常碰到的场景。对于同一类消息,消息内容可能由于其业务上的属性不同,而具有不同的“重要程度”,比如在一个消息推送系统中,一条告警消息显然比一条营销消息重要的多,我们希望即使队列中已经有了大量消息的情形下,优先级更高的消息,仍能够实现“插队”的优先消费,以保证更重要的消息不回被低优先级的消息阻塞。
概述
实际上,这个需求也在Kafka的官方需求中(KIP-349: Priorities for Source Topics),目前的状态是Under Vote,这个Proposal是2019年提出来的,看来官方的方案是指望不上了,只能找些第三方的轮子,或者自己来实现。
在每个Topic中,Kafka顺序写以获得尽可能获得高吞吐,使用Index文件来维护Consumer的消息拉取,维护维度是Offset。Offset不包含优先级语义,但需要顺序语义,优先级语义本身包含非顺序语义,因此就语义来看,以Offset为维度的拉模型MQ和优先级需求本质是冲突的。所以对于单个Topic,在Kafka原生实现消息优先级可行性不高。
因此很自然的,我们能够想到,可以创建多个Topic,每个Topic代表一个优先级。
- 在生产者端,引入优先级字段,以数字来表示,数值越高优先级越高。在向broker推消息时,根据其优先级推送到不同的topic中。
- 在消费者端,通过实现对不同优先级Topic的消费,以实现消息的优先消费。
对于消息的生产,实现起来比较简单,问题的难点在于消费者端如何消费不同Topic的消息,以实现高优先级的消息能够被优先处理?
这里大致有三种方案
- 对于不同的topic,各个consumer分别拉取,拉去后在服务内部使用优先队列进行缓冲。
- 使用一个consumer,优先拉取高优先级消息,没有的话再拉去次优先级消息。
- 使用不同的consumer分别拉取各个topic,但是拉取的消息数量不同,对于高优先级的消息,拉取的“配额”更多。
服务内部优先队列缓冲
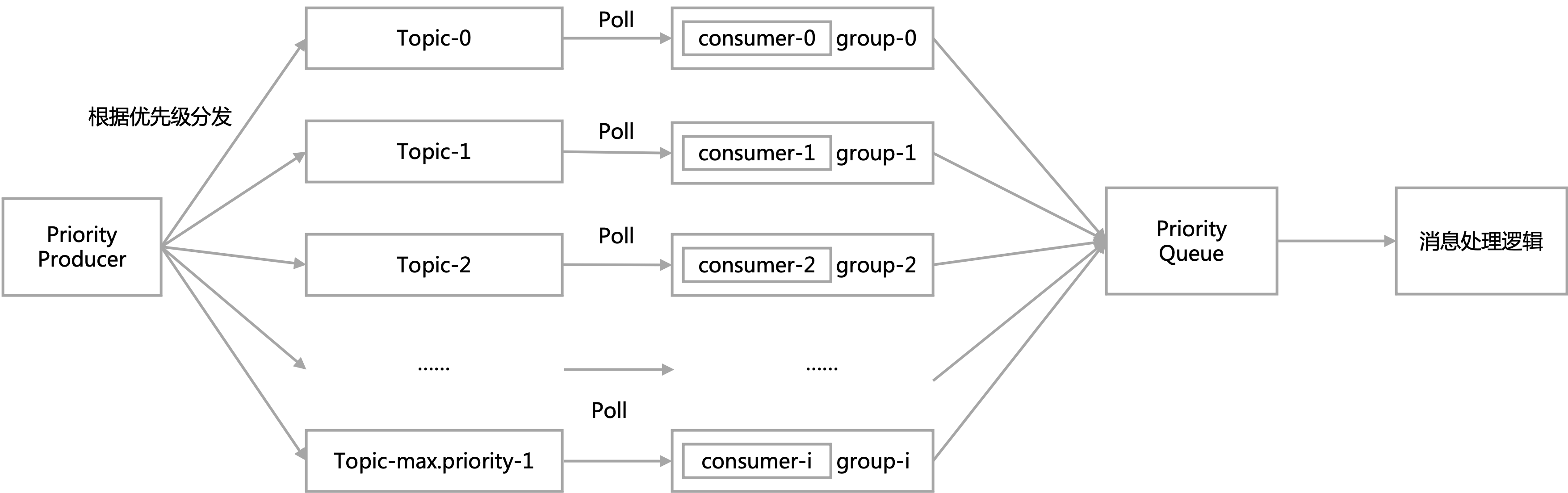
对于这种方案,为了避免OOM,需要使用有界优先队列。
然而对于有界优先队列,在消息消费逻辑复杂,处理速度不够快时,可能会导致优先队列的阻塞。
同时在阻塞时,消息的放入无法保证按照优先级放入,影响优先级的功能。
这里一个可能的做法是不在服务内部的优先队列中维护,而是将消息再放到Redis Zset中进行排序。这样会避免OOM和阻塞的问题,但是会增加系统的复杂度。
优先拉取高优先级Topic
这种方法看起来还不错,但是实现起来逻辑比较复杂。
在每次拉取消息时,都需要先尝试拉取高优先级数据,没有数据再拉取低优先数据。这样的问题有
- 每次都要串行的判断各个优先级数据是否存在,实际的场景中往往是高优消息时比较少的,每次轮询到较低优先级才拉取到消息,性能上可能存在一定问题。
- 即使高优topic中有消息,也是比较少的,实际应用中kafka需要批量拉取消息,在高优消息较少,没有达到每次的拉取数量时,该如何去处理,这里也比较麻烦。
- 通过这种方式拉取消息,会导致低优先级的消息完全得不到消费的机会。
同时拉取多Topic,“权重”不同
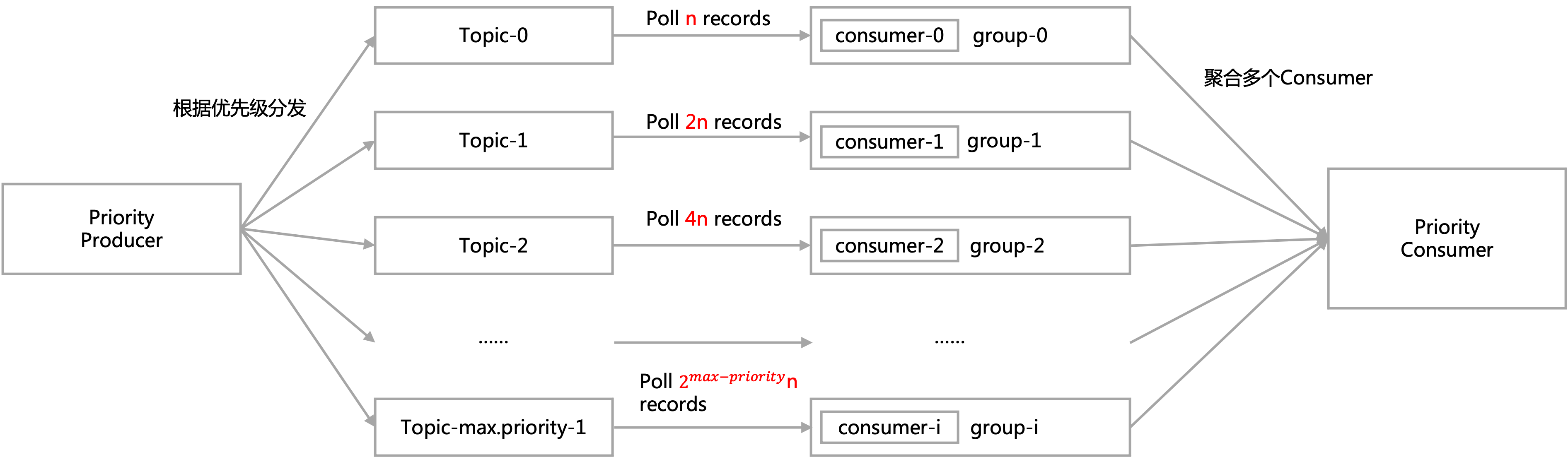
对于这种方式,这里有一个开源的实现flipkart-incubator/priority-kafka-client。
对于每次拉取,需要设定每次拉取的数量
// CapacityBurstPriorityKafkaConsumer.java
void updateMaxPollRecords(KafkaConsumer<K, V> consumer, int maxPollRecords) {
try {
Field fetcherField = org.apache.kafka.clients.consumer.KafkaConsumer.class.getDeclaredField(FETCHER_FIELD);
fetcherField.setAccessible(true);
Fetcher fetcher = (Fetcher) fetcherField.get(consumer);
Field maxPollRecordsField = Fetcher.class.getDeclaredField(MAX_POLL_RECORDS_FIELD);
maxPollRecordsField.setAccessible(true);
maxPollRecordsField.set(fetcher, maxPollRecords);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
对于每次拉取的数量,按照优先级的“权重”不同,分配到不同的topic上。默认的分配策略是按照指数分配。
比如对于每次拉取50个记录,3个优先级的情况下,三个优先级的比例按指数分布,为1:2:4,实际的配额即为7:14:29。
这里有一个很明显的问题是对于高优先级的数据,如果每次拉取不到指定的数量,这部分配额相当于被浪费掉了,这样会影响整体的拉取性能。
对于这种情况,代码中为每个优先级维护了一个“滑动窗口”来记录近期拉取的数量的历史记录,在拉取前,会根据历史拉取情况来进行配额的rebalance,以此来实现配额的动态分配。
for (int i = maxPriority - 1; i >= 0; --i) {
if (isEligibleToBurst(i)) {
int burstCapacity = burstCapacity(i);
if (burstCapacity > 0) {
priorityBurst = i;
int finalCapacity = burstCapacity + maxPollRecordDistribution.get(i);
log.info("Burst in capacity for priority {} to {}", priorityBurst, finalCapacity);
updateMaxPollRecords(consumers.get(priorityBurst), finalCapacity);
}
break;
}
}
感兴趣的朋友可以看一下代码里的具体实现。这里就不再赘述了。
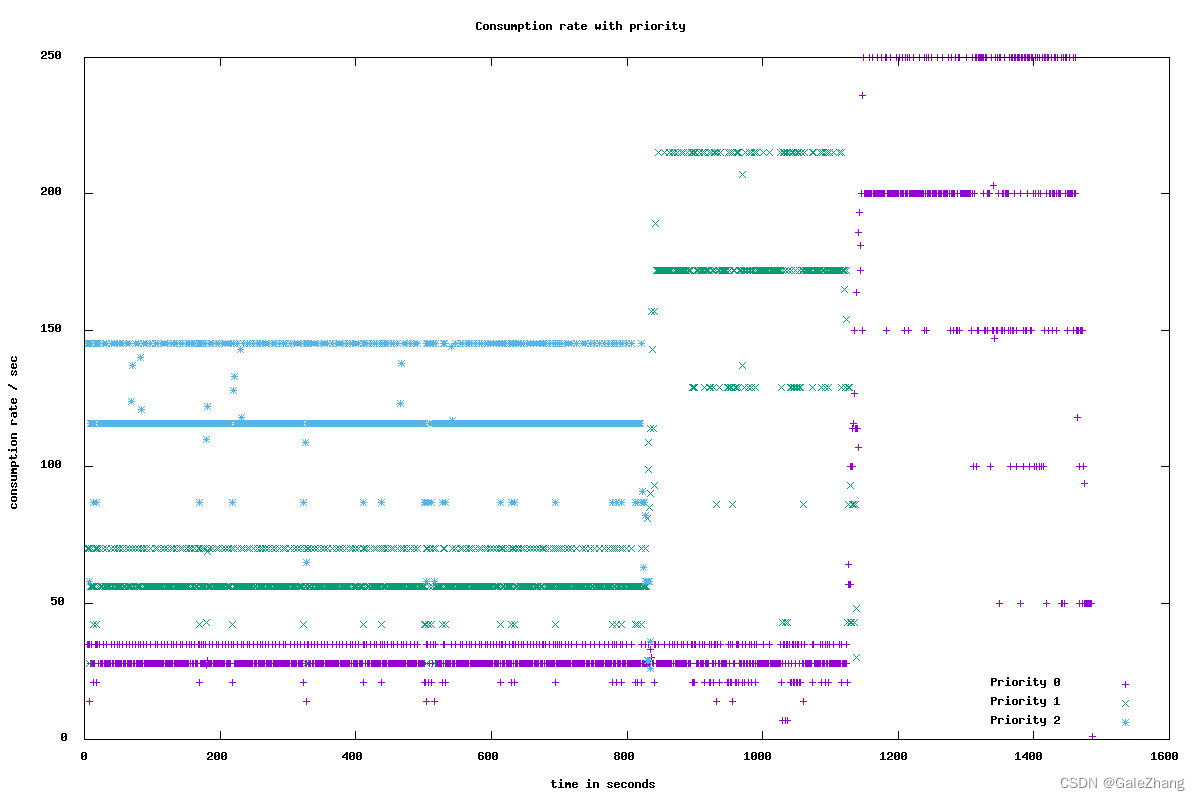
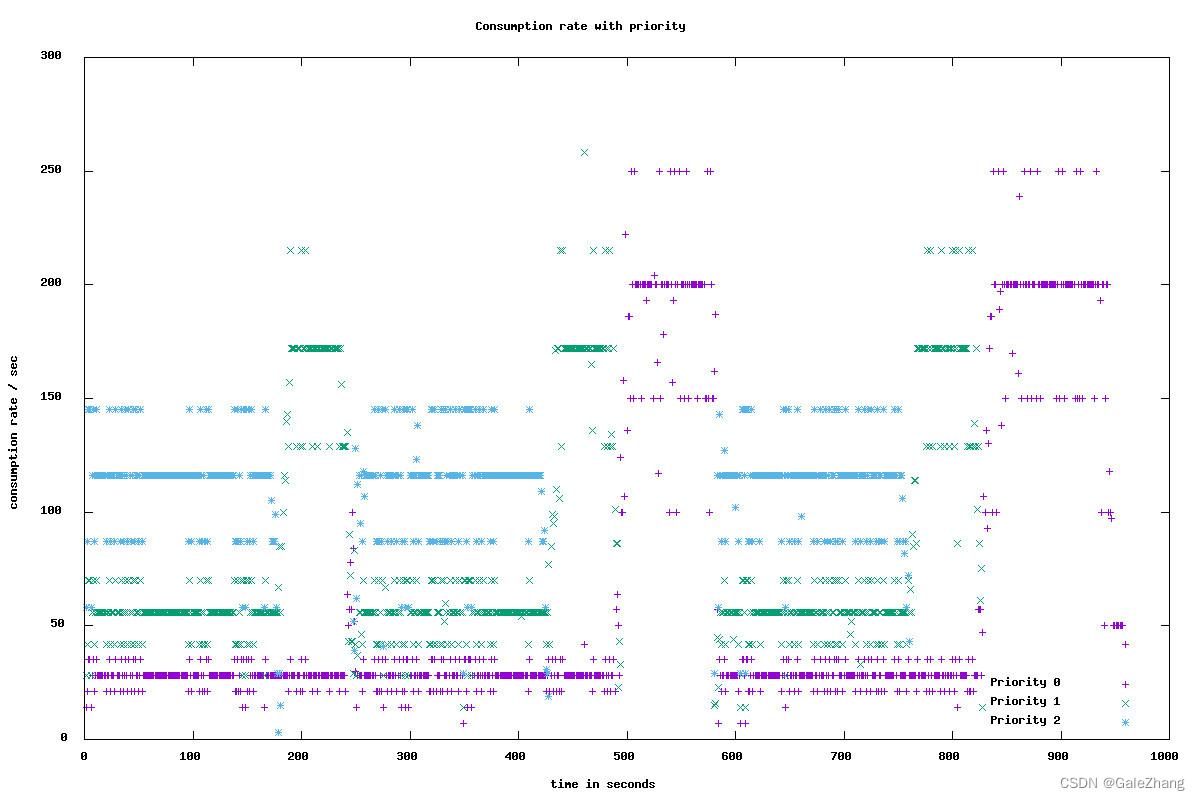
可以看到最终的优先级效果,对于图1,消费者能够按照优先级进行对高优先级的优先消费,当高优先级消费完成后,将配额分配给低优先级topic。对于图2,当高优先级的的数据再次生产后,能够再对优先级进行优先消费,实现了优先级的功能。
在项目中,我也是最终使用了这种方案。
由于在maven仓库中没有该开源实现,我直接将jar包放到了源代码的lib目录下,通过本地引入的方式导入了库。
<dependency>
<groupId>com.flipkart</groupId>
<artifactId>priority-kafka-client</artifactId>
<version>1.0.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/priority-kafka-client-1.0.0.jar</systemPath>
</dependency>
在打包时,也需要增加相应的配置
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
</plugin>
</plugins>
</build>
引入后,具体的使用还是比较简单的。为PriorityKafka进行相应的配置,就可通过依赖注入的方式进行使用了。
@Configuration
public class PriorityKafkaConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.max-priority}")
private Integer maxPriority;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Value("${spring.kafka.consumer.max-poll-records}")
private Integer maxPollRecords;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
@Bean
public PriorityKafkaProducer<Integer, String> createPriorityProducer() {
Properties props = new Properties();
props.put(ClientConfigs.MAX_PRIORITY_CONFIG, String.valueOf(maxPriority));
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
PriorityKafkaProducer<Integer, String> producer = new PriorityKafkaProducer<Integer, String>(props);
return producer;
}
@Bean
public org.apache.kafka.clients.consumer.Consumer<Integer, String> createPriorityConsumer() {
Properties props = new Properties();
props.put(ClientConfigs.MAX_PRIORITY_CONFIG, String.valueOf(maxPriority));
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, String.valueOf(maxPollRecords));
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "60000");
props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, "10500000");
props.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, "10500000");
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "120000");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
"org.apache.kafka.clients.consumer.RoundRobinAssignor");
org.apache.kafka.clients.consumer.Consumer<Integer, String> consumer
= new CapacityBurstPriorityKafkaConsumer<Integer, String>(props);
return consumer;
}
}
以下是我对原先使用的KafkaProducer以及通过@KafkaListener进行消费的改造,改动量还是比较小的。
@Resource
private PriorityKafkaProducer<Integer, String> producer;
/**
* 推送数据到kafka broker, 带优先级
* @param obj
*/
public void send(int priority, Object obj, String topic) {
String jsonStr = JSONObject.toJSONString(obj);
//发送消息
ProducerRecord<Integer, String> record
= new ProducerRecord<Integer, String>(topic, jsonStr);
producer.send(priority, record, (recordMetadata, exception) -> {
if(exception == null) {
//成功的处理
log.info(topic + " - 生产者 发送消息成功:" + jsonStr);
} else {
//发送失败的处理
log.error(topic + " - 生产者 发送消息失败:" + exception.getMessage());
}
});
}
//优先级消费,consumer需注入 @Resourceprivate Consumer<Integer, String> consumer;
ConsumerRecords<Integer, String> records = consumer.poll(100);
if (records.isEmpty()) {
break;
}
log.info("poll {} data form topic {}", records.count(), MESSAGE_TOPIC);
for (TopicPartition partition : records.partitions()) {
for (ConsumerRecord<Integer, String> record : records.records(partition)) {
PushMessage message = JSONObject.parseObject(record.value(), PushMessage.class);
pushHandlerService.handlePushMsg(message);
}
}
consumer.commitAsync();

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)