详解HBase Connection 的使用
对于很多初次接触HBase的伙伴,在使用其客户端API来构建Connection连接对象的时候,有可能会陷入以下几个误区。类比druid等mysql数据库连接池,自己封装一个Connection对象的资源池,每次使用都从池中取出一个Connection对象;在多线程的工作环境中,每个线程都会创建一个Connection对象,造成Connection对象被频繁创建,快速消耗;每次访问HBase的时候
对于很多初次接触HBase的伙伴,在使用其客户端API来构建Connection连接对象的时候,有可能会陷入以下几个误区。
-
类比druid等mysql数据库连接池,自己封装一个Connection对象的资源池,每次使用都从池中取出一个Connection对象;
-
在多线程的工作环境中,每个线程都会创建一个Connection对象,造成Connection对象被频繁创建,快速消耗;
-
每次访问HBase的时候临时创建一个Connection对象,使用完之后调用close方法,关闭连接;
参考HBase技术社区文章
连接HBase的正确姿势中对Connection的源码分析,我们可知:
-
HBase客户端中的Connection对象并不是简单对应一个socket连接。
-
HBase客户端的Connection包含了对Zookeeper、HBase Master、HBase RegionServer三种socket连接的封装。因此,Connection对象每次被创建出来的开销是很大的,使用完毕之后断开,会带来严重的性能损耗。
-
在HBase中Connection类已经实现了对连接的管理功能,所以我们不需要自己在Connection之上再做额外的管理。另外,Connection是线程安全的,而Table和Admin则不是线程安全的,因此正确的做法是,在一个JVM进程中共用一个Connection对象,而在不同的线程中使用单独的Table和Admin对象。
在并发系统中,多个线程每个都去创建一个Connection对象,那么你会马上面临如下窘境:

error-log

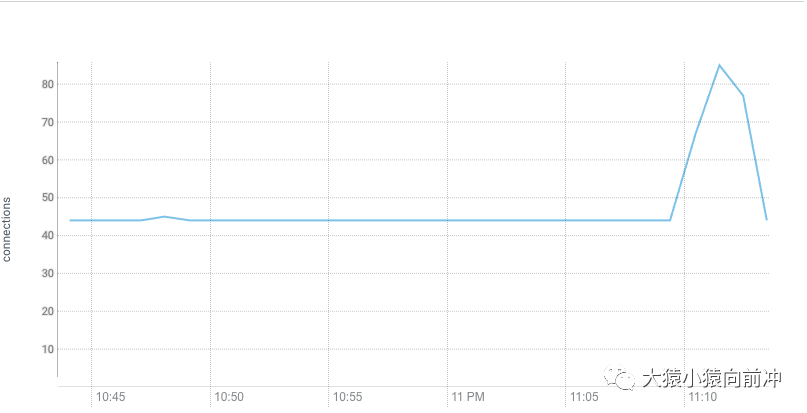
connections-full
上图所示的是HBase Zookeeper的连接被大量占用,某一个客户端连接Zookeeper的连接数超过了60,大量连接创建的请求被拒绝。这样会增加ZK的压力,也会导致客户端系统性能急剧下降。
单例模式维护HBase的Connection
在普通的Java程序中,如果没有并发场景的存在,我们可以简单地使用下面这种方式来创建Connection的对象。
///所有进程共用一个connection对象
connection = ConnectionFactory.createConnection(config);
...
///每个线程使用单独的table对象
Table table = connection.getTable(TableName.valueOf("test"));
try {
...
} finally {
table.close();
}
然而,在多线程中的场景中,我们又该如何来管理我们的连接对象呢?聪明的你,一定会首先想到单例模式。
单例模式是一种简单的设计模式,它的优点是只生成一个实例,可以保证在同一个JVM进程中,对象只存在一个。所以能节约系统资源,减少性能开销,同时能够严格控制用户对它的访问。
关于单例模式的实现,我知道的至少有十种,常见的有饿汉式、懒汉式、双重检测锁式、静态内部类式和枚举单例。
上述实现方式各有优劣,但使用时需要注意,线程是否安全和平衡效率。关于其具体的实现细节,网上有很多文章可供参考,这里不做详细罗列,只举例双重检测锁式的单例实现方式,在管理HBase客户端连接对象中的应用。具体实现代码:
public class SingleConnectionFactory {
private static final Logger LOGGER = LoggerFactory.getLogger(SingleConnectionFactory.class);
private volatile static Connection connection;
private SingleConnectionFactory() {}
public static Connection getConnection(Configuration configuration) {
if (connection == null) {
synchronized (SingleConnectionFactory.class) {
if (connection == null) {
try {
connection = ConnectionFactory.createConnection(configuration);
LOGGER.info("the connection of HBase is created successfully.");
} catch (IOException e) {
LOGGER.error("the connection of HBase is created failed.");
throw new HBaseSdkConnectionException(e);
}
}
}
}
return connection;
}
}
上述单例Connection对象创建工厂类,在多线程的测试环境中亦可保证同一个JVM进程中,只有一个Connection对象被创建出来,观察ZK客户端连接数监控,几乎无波动。
多例模式中维护HBase的Connection
在cuckoo-cloud(布谷鸟,微服务版大数据组件统一管理平台,目前已集成hbase-manager和kafka-manager的功能)中迁移我们的hbase-manager应用时,遇到这样一个问题。
cuckoo-cloud平台上会管理我们的多个HBase集群,这些HBase集群的连接信息被保存进数据库中,可以进行动态维护。大数据培训在设计HBase的连接管理功能时,如果采用单例模式,那么,无论切换任意一个集群,始终操作的是最开始被初始化连接的集群;如果放弃单例模式,Connection对象又会被滥用。
所以,我需要一个容器,它能保存不同集群的连接对象,且每个对象在一个JVM进程中只保留一个。
我曾尝试创建ThreadLocal变量,利用同一个ThreadLocal所包含的对象,在不同的Thread中保留不同的副本。这样,每一个Thread内都有自己的实例副本,且该副本只能由当前Thread来使用,即保证了在多线程环境中只保留一个对象,又规避了多线程环境中的并发安全问题,可折腾了一圈,最终以失败告终。(不知是我学艺不精,还是ThreadLocal不适合这种应用场景?)
接着又尝试构建guava单例缓存池,利用缓存池中key的唯一性来保证多个被保存的对象唯一。兴致勃勃写好代码,一上线测试,问题未有半点改善。
关于ThreadLocal和guava缓存池的应用场景和相关细节,还请参考网上的优秀文章。
最后想到了多例模式(一开始多例模式是脑海中虚构的概念,我想,既然有单例,那就应该存在多例。一百度,还真有这种设计模式存在)。可是能搜到的网上贴出来的多例实现代码都是基于创建多个固定对象的,但我需要的是动态创建对象,最终的实现效果如下:
public class MultipleConnectionFactory {
private static final Logger LOGGER = LoggerFactory.getLogger(MultipleConnectionFactory.class);
private volatile static Map<String, Connection> connectionMap;
private MultipleConnectionFactory() {
}
public static Connection getConnection(Configuration configuration) {
String cluster = configuration.get(HConstants.ZOOKEEPER_QUORUM);
if (connectionMap == null || !connectionMap.containsKey(cluster)) {
synchronized (MultipleConnectionFactory.class) {
if (connectionMap == null || !connectionMap.containsKey(cluster)) {
try {
if (connectionMap == null) {
connectionMap = new HashMap<>(2);
}
if (!connectionMap.containsKey(cluster)) {
Connection connection = ConnectionFactory.createConnection(configuration);
LOGGER.info("the connection of HBase cluster [{}] is created successfully.", cluster);
connectionMap.put(cluster, connection);
}
} catch (IOException e) {
LOGGER.error("the connection of HBase is created failed.");
throw new HBaseSdkConnectionException(e);
}
}
}
}
return connectionMap.get(cluster);
}
}
类比双重检测锁式的单例实现方式,在此使用ZK的连接地址为key,来保证每一个集群的连接对象在同一个JVM进程中唯一存在。
ConnectionFactory.createConnection方法中的连接池参数
ConnectionFactory.createConnection(Configuration conf, ExecutorService pool, User user)
调用此方法时,可以传入三个参数,conf是连接配置相关,user是用户认证相关,在此不必细说。ExecutorService pool的作用是什么呢?
参考文章中的解释是,HBase客户端连接池。
HBase访问一条数据的过程中,需要连接Zookeeper、HBase Master、HBase RegionServer,HBase客户端的Connection包含了对以上三种socket连接的封装。
Connection对象和实际的socket连接之间的对应关系如下图:

socket
在HBase客户端的代码中,真正对应socket连接的是RpcConnection对象。HBase中使用PoolMap这种数据结构来存储客户端到HBase服务器之间的连接。PoolMap封装了ConcurrentHashMap<>的结构,key是ConnectionId(封装了服务器地址和用户ticket),value是一个RpcConnection对象的资源池。当HBase需要连接一个服务器时,首先会根据ConnectionId找到对应的连接池,然后从连接池中取出一个连接对象。
HBase中提供了三种资源池的实现,分别是Reusable,RoundRobin和ThreadLocal。具体实现可以通过hbase.client.ipc.pool.type配置项指定,默认为Reusable。连接池的大小也可以通过hbase.client.ipc.pool.size配置项指定,默认为1。
关于pool的用意,扒拉了半天源码,嵌套实在太深也太复杂,为了保证文章完整性,只能引用参考文章,(如有侵权,请私信我删除)
如果对ExecutorService pool有特殊需求,可以构造相应的连接池,通过配置合理的连接池的大小,来提升系统请求HBase集群的性能。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)