Redis-master节点宕机后的处理方式
在redis集群中,每个节点各司其职,有的当老大,有的当小弟,老大负责写,小弟负责读。但是如果老大挂了,这些小弟就群龙无首了,我们的服务就会崩盘,谁都不愿意这种事情发生,所以我们需要了解当master节点挂了之后redis的处置方式。如果第三项都一样,那么其实选哪个slave都一样,因为他们的数据都是最新的,都可以成为主节点,那么这时候就根据他们的id判断,id越小优先级越高。我们应该从slave
在redis集群中,每个节点各司其职,有的当老大,有的当小弟,老大负责写,小弟负责读。但是如果老大挂了,这些小弟就群龙无首了,我们的服务就会崩盘,谁都不愿意这种事情发生,所以我们需要了解当master节点挂了之后redis的处置方式。
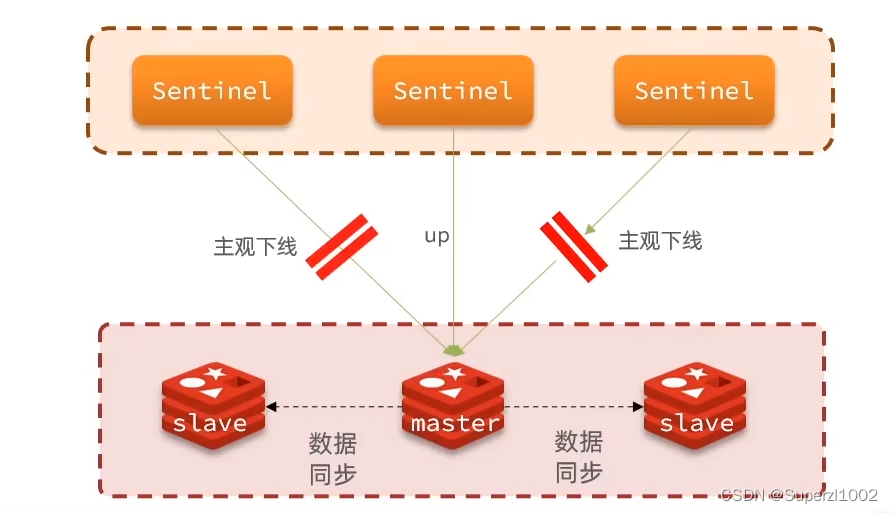
那么我们是怎么知道master挂了的呢?这里引出一个哨兵sentinel的概念,sentinel(通常为集群)基于心跳机制监测服务状态,会帮我们监测redis集群的健康状态每隔一秒向redis集群中的每个实例发送ping,如果某个实例在规定时间内未完成响应,则认为该实例主观下线。
什么是主观下线?通俗点讲就是我单方面认为你挂了,但是你实际上挂没挂我不知道,只是我认为你挂了。
客观下线:与主观下线相对应,当超过指定数量(quorum,数量最好超过sentinel实例数量的一半)的sentinel都认为该实例主观下线了,则认为该实例客观下线

当确定了集群中某个master确实挂了,那么我们应该怎么处理呢?
我们应该从slave节点中选举出一个新的master节点,并且让原来的slave节点的老大都变成这个新的老大。那么应该选谁当这个新老大呢?这里我们有一套标准。
1.首先判断slave节点与master节点断开的时间长短,如果超过了指定值(可配置),则会排除该slave节点
2.每个slave节点都有一个slave-priority值,表示优先级,这个值越小优先级越高,如果是0则永不参与选举
3.如果slave-priority一样,则判断slave节点的offset值,越大则说明slave的数据越新,优先级越高
4.如果第三项都一样,那么其实选哪个slave都一样,因为他们的数据都是最新的,都可以成为主节点,那么这时候就根据他们的id判断,id越小优先级越高
ok,到此为止,新的master已经选举出来了,那么我们要让这个集群继续正常运行,还需要进行一些配置操作,也就是故障转移。
1.首先sentinel要给新master节点(此时还是slave,只是他是准master)发送slave of no one命令,表示让该节点成为master
2.其次,另外的节点要和这个新master建立主从关系。sentinel向其他的slave发送slave of “新master的ip和端口”,让这些slave成为新master的从节点,开始从新的master上同步数据
3.最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新master的从节点


华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)