Redis 中的数据持久化策略(RDB)
Redis 是一个内存数据库,所有的数据都直接保存在内存中,那么,一旦 Redis 进程异常退出,或服务器本身异常宕机,我们存储在 Redis 中的数据就凭空消失,再也找不到了。Redis 作为一个优秀的数据中间件,必定是拥有自己的持久化数据备份机制的,redis 中主要有两种持久化策略,用于将存储在内存中的数据备份到磁盘上,并且在服务器重启时进行备份文件重载。RDB 和 AOF 是 Redis
Redis 是一个内存数据库,所有的数据都直接保存在内存中,那么,一旦 Redis 进程异常退出,或服务器本身异常宕机,我们存储在 Redis 中的数据就凭空消失,再也找不到了。
Redis 作为一个优秀的数据中间件,必定是拥有自己的持久化数据备份机制的,redis 中主要有两种持久化策略,用于将存储在内存中的数据备份到磁盘上,并且在服务器重启时进行备份文件重载。
RDB 和 AOF 是 Redis 内部的两种数据持久化策略,这是两种不同的持久化策略,一种是基于内存快照,一种是基于操作日志,那么本篇就先来讲讲 RDB 这种基于内存快照的持久化策略。
一、什么是 RDB 持久化策略
RDB(redis database),快照持久化策略。RDB 是 redis 默认的持久化策略,你可以打开 redis.conf,默认会看到这三条配置。
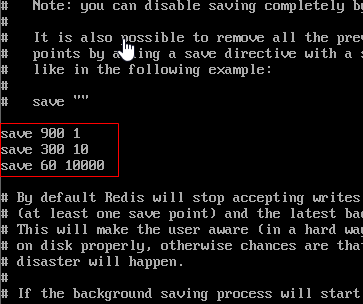
save 900 1 # 900秒内执行一次set操作 则持久化1次
save 300 10 # 300秒内执行10次set操作,则持久化1次
save 60 10000 # 60秒内执行10000次set操作,则持久化1次
RDB 又分为两种:
- 一种是同步的,调用 save 命令即可触发 redis 进行 RDB 文件生成备份,但是这是一个同步命令,在备份完成之前,redis 服务器不响应客户端任何请求。
- 另一种是异步的,调用 bgsave 命令,redis 服务器 fork 一个子进程进行 RDB 文件备份生成,与此同时,主进程依然可以响应客户端请求。
显然,异步的 RDB 生成策略才是主流,除了某些特殊情况,相信不会有人会在生产环境中用 save 命令阻塞 redis 服务来生成 RDB 文件的。
以上我们介绍的两个命令,save 和 bgsave 这两个命令需要我们手动的在客户端发送请求才能触发,我们叫做 主动触发。
而我们之前匆匆介绍过的配置触发,这种我们叫做 被动触发,被动触发有一些配置,下面我们来看看。
1、save 配置
save 配置是一个非常重要的配置,它配置了 redis 服务器在什么情况下自动触发 bgsave 异步 RDB 备份文件生成。
基本语法格式:
save <seconds> <changes>
当 redis 数据库在多少秒内,数据库中的 keys 发生了多少次变化,那么就会触发 bgsave 命令的调用。
2、dbfilename 配置
dbfilename 配置项决定了生成的 RDB 文件名称,默认配置为 dump.rdb。
dbfilename dump.rdb
3、rdbcompression 配置
rdbcompression 配置的是 rdb 文件中压缩启用配置,基本语法格式:
rdbcompression yes(|no)
如果 rdbcompression 配置为 yes,那么即代表 redis 进行 RDB 文件生成中,如果遇到字符串对象并且其中的字符串值占用超过 20 个字节,那么就会对字符串进行 LZF 算法进行压缩。
4、stop-writes-on-bgsave-error 配置
stop-writes-on-bgsave-error 配置了,如果进行 RDB 备份文件生成过程中,遭遇错误,是否停止 redis 提供写服务,以警示用户 RDB 备份异常,默认是开启状态。
stop-writes-on-bgsave-error yes(|no)
5、dir 配置
dir 配置的是 rdb 文件存放的目录,默认是当前目录。
dir ./
6、rdbchecksum 配置
rdbchecksum 配置 redis 是否使用 CRC64 校验算法校验 RDB 文件是否发生损坏,默认开启状态,如果你需要提升性能,可以选择性关闭。
rdbchecksum yes(|no)
二、saveparams 和 dirty 计数器
我们 redisServer 结构体中有这么两个字段:

saveparams 结构定义如下:
struct saveparam {
time_t seconds; //秒数
int changes; //变更次数
};
相信你能够想到,上述配置文件中的 save 配置就对应了两个参数,多少秒内数据库发生了多少次的变更便触发 bgsave。
映射到代码就是我们 saveparam 结构,每一个 saveparam 结构都对应一行 save 配置,而最终会以 saveparam 数组的形式被读取到 redisServer 中。
ps:介绍这个目的是为我们稍后分析 RDB 文件生成的源码实现做前置铺垫。
除此之外,redisServer 数据结构中还有这么两个字段:

- dirty 字段记录了自上次成功备份 RDB 文件之后,包括 save 和 bgsave 命令,整个 redis 数据库又发生了多少次修改。
- dirty_before_bgsave 字段可以理解为上一次 bgsave 命令备份时,数据库总的修改次数。
还有一些跟持久化相关时间字段,上一次成功 RDB 备份的时间点,上一次 bgsave 命令开始执行时间等等。

下面我们也粘贴粘贴源码,分析分析看 redis 是如何进行 RDB 备份文件生成的。
int serverCron(....){
.....
//如果已经有子进程在执行 RDB 生成,或者 AOF 恢复,或者有子进程未返回
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
int statloc;
pid_t pid;
//查看这个进程是否返回信号
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
//持久化异常,打印日志
if (pid == -1) {
serverLog(LL_WARNING,"wait3() returned an error: %s. "
"rdb_child_pid = %d, aof_child_pid = %d",
strerror(errno),
(int) server.rdb_child_pid,
(int) server.aof_child_pid);
} else if (pid == server.rdb_child_pid) {
//成功持久化 RDB 文件,调用方法用心的RDB文件覆盖旧的RDB文件
backgroundSaveDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else if (pid == server.aof_child_pid) {
//成功执行 AOF,替换现有的 AOF文件
backgroundRewriteDoneHandler(exitcode,bysignal);
if (!bysignal && exitcode == 0) receiveChildInfo();
} else {
//子进程成功,但返回的 pid 类型异常,无法匹配
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
}
//如果子进程未结束,不允许字典进行 rehash
updateDictResizePolicy();
closeChildInfoPipe();
}
} else{.......}
}
serverCron 每隔一百毫秒执行一次(可能后续的 redis 版本有所区别,本文基于 4.0),都会首先去判断 RDB 或 AOF 子进程是否成功完成,如果成功会进行旧文件替换覆盖操作等。我们继续看 else 部分。
int serverCron(....){
.....
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
..........
}
else{
//如果未有子进程做 RDB 文件生成
//遍历 saveparams 数组,取出我们配置文件中的 save 配置项
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
//根据我们之前介绍的 dirty 计数器判断 save 配置条件是否满足
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
//记录日志
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
//核心方法,进行 RDB 文件生成
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
//AOF 下篇我们在介绍,本篇看 RDB
if (server.aof_state == AOF_ON &&
server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
}
如果未有子进程进行 RDB 文件生成,那么遍历循环我们的 save 配置项是否满足,如果满足则调用 rdbSaveBackground 进行真正的 RDB 文件生成。我们继续看看这个核心方法:
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
long long start;
if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
openChildInfoPipe();
start = ustime();
if ((childpid = fork()) == 0) {
int retval;
closeListeningSockets(0);
redisSetProcTitle("redis-rdb-bgsave");
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(-1);
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(1024*1024));
}
server.child_info_data.cow_size = private_dirty;
sendChildInfo(CHILD_INFO_TYPE_RDB);
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
server.stat_fork_time = ustime()-start;
server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */
latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);
if (childpid == -1) {
closeChildInfoPipe();
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_pid = childpid;
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
updateDictResizePolicy();
return C_OK;
}
return C_OK;
}
rdbSaveBackground 核心的是 fork 函数和 rdbSave 函数的调用。fork 函数其实是一个系统调用,他会复制出一个子进程出来,子进程和父进程几乎一模一样的内存数据。
fork 函数是阻塞的,当子进程复制出来后,程序的后续代码段会由父子进程同时执行,也就是说,fork 之后,接下来的代码,父子进程会并发执行,但系统不保证执行顺序。
父进程中,fork 函数返回值等于子进程的进程 id,子进程中 fork 函数返回值等于零。
所以,rdbSaveBackground 函数的核心逻辑也就很清晰了,fork 成功之后,子进程调用 rdbSave 进行 RDB 文件写入,并产生一个“temp-%d.rdb”的临时文件,而父进程记录一些日志信息、子进程进程号,时间等信息。
至于 rdbSave 函数是怎么写入 RDB 文件的,这个也很简单,RDB 文件是有固定的协议规范的,程序只要按照协议写入数据即可,关于这个协议,我们等下详细说它。
总结一下,serverCron 这个定期执行的函数,会将配置文件中的 save 配置进行读取,并判断条件是否满足,如果条件满足则调用 rdbSaveBackground 函数 fork 出一个子进程完成 RDB 文件的写入,生成临时文件,并确保临时文件写入成功后,再替换旧 RDB 文件,最后退出子进程。
ps:fork 函数复制出来的子进程一定要记得退出,否则每一次主进程都会复制一个子进程,最终导致服务 OOM。
三、RDB 文件结构分析
任何格式的文件都会有自己的编码协议,Java 中的字节码也好、图片格式文件也好,我们这里的 RDB 文件也好,都是有自己的一套约定好的协议的,具体到每一个字节位置该放什么样的字段数据,这都是约定俗成的,编码的时候按协议写入二进制,读取的时候也按照协议读取字段字节。
RDB 协议规定整个文件包括如下几个字段:

其中,第一部分是固定的五个字节,redis 把它称为 Magic Number,固定的五个字符 “R”,“E”,“D”,“I”,“S”。
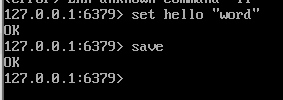
我们在 redis 的 0 号数据库中添加一个键值对,然后执行 save 命令生成 RDB 文件,接着打开这个二进制文件。
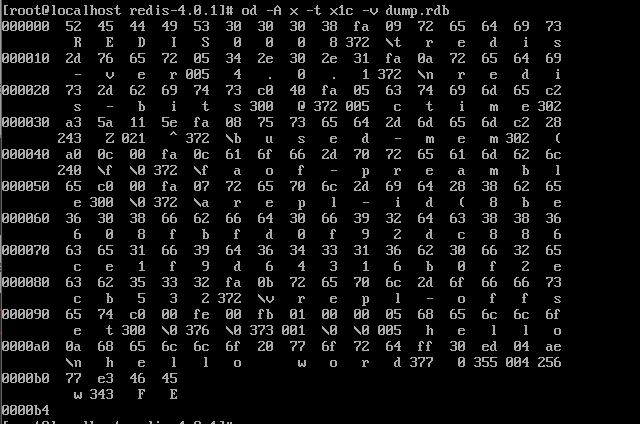
我们用 od 命令,并以 ASCII 码选项输出二进制文件,你会发现前五个字节是我们固定的 redis 这五个字符。
下一个字段 REDIS_VERSION 占四个字节,描述当前 RDB 的版本,以上述为例,redis-4.0 版本对应的 RDB 文件版本就是 0008。
下一个字段是 Aux Fields,官方称辅助字段,是 RDB 7 以后加入的,主要包含以下这些字段信息:
- redis-ver:版本号
- redis-bits:OS Arch
- ctime:RDB文件创建时间
- used-mem:使用内存大小
- repl-stream-db:在server.master客户端中选择的数据库
- repl-id:当前实例 replication ID
- repl-offset:当前实例复制的偏移量
接着就是 DATABASE 部分,这部分会存储的我们字典中的真实数据,redis 中多个数据库,生成 RDB 文件的时候只会对有数据的数据库进行写入,而这部分的格式如下:
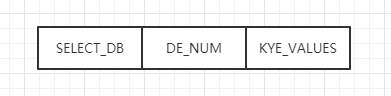
对应到我们上述例子中,就是这一部分:

我们的 rdb.h 文件头中有这么一些常量的定义:
#define RDB_OPCODE_AUX 250
#define RDB_OPCODE_RESIZEDB 251
#define RDB_OPCODE_EXPIRETIME_MS 252
#define RDB_OPCODE_EXPIRETIME 253
#define RDB_OPCODE_SELECTDB 254
#define RDB_OPCODE_EOF 255
十六进制 fe 转换成十进制就是 254,对应的就是 RDB_OPCODE_SELECTDB,标识即将打开某数据库,所以其后跟着的就是即将要打开的数据库编号,我们这里是零号数据库。
十六进制 fb 转换成十进制就是 251,对应的就是 RDB_OPCODE_RESIZEDB,标识当前数据库容量,即有多少个键,我们这里只有一个键。
紧接着就是存我们的键值对,这部分的格式如下:
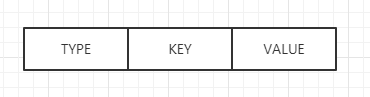
type 占一个字节标识当前键值对的类型,即对象类型,有如下可选类型:
#define RDB_TYPE_STRING 0
#define RDB_TYPE_LIST 1
#define RDB_TYPE_SET 2
#define RDB_TYPE_ZSET 3
#define RDB_TYPE_HASH 4
#define RDB_TYPE_ZSET_2 5
#define RDB_TYPE_MODULE 6
#define RDB_TYPE_MODULE_2 7
/* Object types for encoded objects. */
#define RDB_TYPE_HASH_ZIPMAP 9
#define RDB_TYPE_LIST_ZIPLIST 10
#define RDB_TYPE_SET_INTSET 11
#define RDB_TYPE_ZSET_ZIPLIST 12
#define RDB_TYPE_HASH_ZIPLIST 13
#define RDB_TYPE_LIST_QUICKLIST 14
key 始终是字符串,由字符串长度前缀加上自身内容构成,后跟 value 的内容。
- EOF 字段标识 RDB 文件的结尾,占一个字节,并固定值等于 255 也就是十六进制 ff,这是能从 rdb.h 文件头中找到的。
- CHECK_SUM 字段存储的是 RDB 文件的校验和,占八个字节,用于校验 RDB 文件是否损坏。
以上,我们就简单介绍了 RDB 文件的构成,其实也只是点到为止啊,每一种类型的对象进行编码的时候都是不一样的,还要一些压缩对象的手法等等,我们这里也不可能全部详尽。
总的来说,对 RDB 文件构成有个基本了解就行,实际上也很少有人没事去分析 RDB 文件里的数据的,即便是有也是通过工具进行分析的,比如 rdb-tools 等,人工分析也太炸裂了。
好了,关于 RDB 我们就简单介绍到这,下一篇我们研究研究 AOF 这种持久化策略,再见!
原文地址:https://www.cnblogs.com/yangming1996/p/12152090.html

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)