高并发下Redis可能存在的问题及解决方案
下面所有问题都存在于当给Key设置有效时间的情况下,且在高并发访问下。当时如果Redis中所有数据都是用于随着应用程序的运行,会导致内存不足问题。
目录
6.Redis 缓存淘汰策略/当内存不足时如何回收数据/保证Redis中数据不出现内存溢出情况(面试题)
下面所有问题都存在于当给Key设置有效时间的情况下,且在高并发访问下。
当时如果Redis中所有数据都是用于随着应用程序的运行,会导致内存不足问题。
1.缓存穿透(面试问题)
在实际开发中,添加缓存工具的目的,较少对数据库的访问次数,增加访问效率。
肯定会存在Redis中不存在的缓存数据。例如:访问id= -1的数据 。可能出现绕过redis依然频繁访问数据库的情况,称为缓存穿透,多出现在数据库查询为null时的情况不被缓存时。
解决办法:
如果查询出来为null的数据,把null数据依然放入到redis缓存中,同时设置这个key的有效时间比正常有效时间更短一些。
| if(list==null){ // key value 有效时间 时间单位 redisTemplate.opsForValue().set(navKey,null,10, TimeUnit.MINUTES); }else{ redisTemplate.opsForValue().set(navKey,result,7,TimeUnit.DAYS); } |
2.缓存击穿(面试问题)
实际开发中,考虑redis所在服务器中内存压力,都会设置key的有效时间。一定会出现键值对过期的情况。如果正好key过期了,此时出现大量并发访问,这些访问都会去访问数据库,这种情况成为缓存击穿。
解决办法:
永久数据(设置热点数据永远不过期)
加锁。防止出现数据库的并发访问
2.1 ReentrantLock(重入锁)
JDK 对于并发访问处理的内容都放入了java.until.concurrent中
ReentrantLock性能和synchronized没有区别的,但是API使用起来更加方便。
@SpringBootTest
public class MyTest {
@Test
public void test(){
new Thread(){
@Override
public void run() {
test2("第一个线程111111");
}
}.start();
new Thread(){
@Override
public void run() {
test2("第二个线程222222");
}
}.start();
try {
Thread.sleep(20000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
ReentrantLock lock = new ReentrantLock();
public void test2(String who){
lock.lock();
if(lock.isLocked()) {
System.out.println("开始执行:" + who);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("执行完:" + who);
lock.unlock();
}
}
}
2.2 解决缓存击穿实例代码
只有在第一次访问时和key过期时才会访问数据库。对于性能来说没有过大影响,因为平时都是直接访问redis
private ReentrantLock lock = new ReentrantLock();
@Override
public Item selectByid(Integer id) {
String key = "item:"+id;
if(redisTemplate.hasKey(key)){
return (Item) redisTemplate.opsForValue().get(key);
}
lock.lock();
if(lock.isLocked()) {
Item item = itemDubboService.selectById(id);
// 由于设置了有效时间,就可能出现缓存击穿问题
redisTemplate.opsForValue().set(key, item, 7, TimeUnit.DAYS);
lock.unlock();
return item;
}
// 如果加锁失败,为了保护数据库,直接返回null
return null;
}
3 缓存雪崩(面试问题)
在一段时间内容,出现大量缓存数据失效,这段时间内容数据库的访问频率骤增,这种情况称之为缓存雪崩,与缓存击穿不同的是,缓存击穿是指并发查同一条数据,缓存雪崩是不同的数据都过期了,很多数据都查不到从而查数据库。
解决办法:
| int seconds = random.nextInt(10000); redisTemplate.opsForValue().set(key, item, 100+ seconds, TimeUnit.SECONDS); |
- 缓存数据的过期时间设置成随机,防止同一时间大量数据过期的现象产生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中
- 设置热点数据永远不过期
4.边路缓存
cache aside pattern 边路缓存的问题。其实是一种指导思想,思想中包含:
1.查询的时候应该先查询缓存,如果缓存不存在,再查询数据库。
2.修改缓存数据时,应该先修改数据库,再修改缓存。
5.Redis脑裂
Redis脑裂主要是指因为一些网络原因导致Redis Master和Redis Slave和Sentinel集群处于不同的网络分区。sentinel连接不上Master就会重新选择Master,此时就会出现两个不同的Master,好像大脑分裂成两个一样。
Redis集群中不同的节点存储不同的数据,脑裂会导致大量数据丢失。
解决Redis脑裂只需要在Redis配置文件中配置两个参数
| min-slaves-to-write 3 //连接到master的最小slave数量 min-slaves-max-lag 10 //slave连接到master的最大延迟时间 |
6.Redis 缓存淘汰策略/当内存不足时如何回收数据/保证Redis中数据不出现内存溢出情况(面试题)
Redis中数据都放入到内存中。如果没有淘汰策略将会导致内存中数据越来越多,最终导致内存溢出。在Redis5内置了缓存淘汰策略。在配置文件中有如下配置
| # maxmemory-policy noeviction 默认策略noevication # maxmemory <bytes> 缓存最大阈值 # volatile-lru -> 在设置过期key集中选择使用数最小的。 # allkeys-lru -> 在所有key中选择使用最小的。 # volatile-lfu -> 在设置过期时间key集中采用lfu算法。 # allkeys-lfu -> 在所有key中采用lfu算法。 # volatile-random -> 在设置过期key集中随机删除。 # allkeys-random -> 在所有key中随机删除。 # volatile-ttl -> 在设置了过期时间key中删除最早过期时间的。 # noeviction -> 不删除key,超过时报错。 |
6.1 Lru和lfu算法
6.1.1 LRU
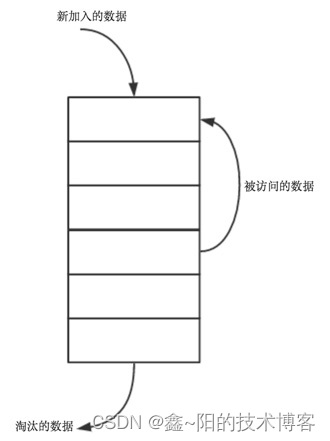
LRU(least recently used) 最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高。LRU算法实现简单,运行时性能也良好,被广泛的使用在缓存/内存淘汰中。

- 新插入的数据到链表的头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
6.1.2 LFU
Least Frequently Used(最近最不经常使用)如果一个数据在最近一段时间很少被访问到, 那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
6.1.3 LRU 和LFU的区别
LRU淘汰时淘汰的是链表最尾部的数据。而LFU是一段时间内访问次数最少的
6.2 何时淘汰数据
1.消极方法(passive way):在读取数据时先判断是否过期,如果过期删除他,例如:get、hget、hmget等
2.积极算法(active way)周期性判断是否有失效内容,如果有就删除。
3.主动删除:当超过阈值时会删除。
在Redis中每次新增数据都会判断是否超过阈值。如果超过了,就会按照淘汰策略删除一些key。
6.3 每次删除多少
淘汰数据量和新增数量进行判断。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)