Redis 一致性hash、hash槽
参考:redis系列之——一致性hash算法_诸葛小猿-CSDN博客_redis一致性hashRedis缓存问题(缓存穿透、缓存击穿、缓存雪崩、hash一致性问题及数据倾斜问题)_赵昕彧-CSDN博客1.Hash环:一致性Hash算法使用 “取模法”,且是对2^32次方取模,其可表示的范围为:0 ~ 2^32-1如何确定数据位于hash环上的位置?将数据key使用Hash函数计算出哈希值,并确定此
参考:
背景:
常用的hash算法虽然能建立数据和节点的映射关系,但每次在节点数量发生变化的时候,最坏情况下所有数据都需要迁移,因此不适用节点数量变化的分布式场景。为了减少迁移的数据量,就出现了一致性hash算法。
应用场景:分布式缓存系统
1.Hash环:
一致性hash是指将 “存储节点” 和 “数据” 都映射到一个首尾相连的hash环上。如果增删节点,仅影响该节点在hash环上顺时针相邻的后继节点,其他数据不会受到影响。
-
第一步:对存储节点进行哈希计算,也就是对存储节点做哈希映射,比如根据节点的 IP 地址进行哈希(用ip地址的哈希值对环上的节点个数取模,比如ip地址的哈希值为1234,节点个数N,那么可映射到第1234%N的位置上);
-
第二步:当对数据进行存储或访问时,对数据进行哈希映射;
一致性Hash算法使用 “取模法”,且是对 2^32 次方取模,其可表示的范围为:0 ~ 2^32-1
如何确定数据位于hash环上的位置?
将数据key使用Hash函数计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
比如:a、b、c三个key,经过哈希计算后,在环空间上的位置如下:key-a存储在node1,key-b存储在node2,key-c存储在node3。与普通的hash算法有何不同?
普通的hash算法是对节点数进行hash,而一致性hash是对固定值2^32进行取模
2.优点:
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
新增服务器节点/删除服务器节点:
在hash环中新增服务器,也是通过hash算法确认分布,只需要移动一小部分数据即可;移除也是同理(比如下图中想删除4节点,只需把原本1~4节点之间的数据移动到2节点上即可)。

3.易产生问题:数据倾斜
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
当在服务器节点数量太少的时候,容易出现分布不均而导致数据倾斜。
例如:系统中只有两台服务器,此时必然造成大量数据集中到Node 2上,而只有极少量会定位到Node 1上。其环分布如下:
4.数据倾斜解决方法:虚拟节点映射
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
映射关系:缓存数据 ➜ 虚拟节点 ➜ 真实节点
(1) 个人理解:针对节点:其实也就是通过对 真实节点 构造大量的 虚拟节点 映射,使得每个真实节点对应的虚拟节点都能更分散的分布在hash环的各处。针对数据:当向redis集群中添加k-v时,负责存储的虚拟节点也更多,这样数据分布也会更加分散,所有k-v穿插分散在不同虚拟节点上,也分别对应不同的真实节点!
在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
具体做法:可以在服务器IP或主机名的后面增加编号来实现,例如上面的情况,可以为每个服务节点增加三个虚拟节点,于是可以分为 RedisService1#1、 RedisService1#2、 RedisService1#3、 RedisService2#1、 RedisService2#2、 RedisService2#3
(2)对于hash环来说,节点越多,数据分布越平稳。所以采用虚拟节点的方式,将一个节点虚拟成多个节点,保证环上有1000~2000个节点最佳。
一般10个Redis服务器的集群,每个节点可以虚拟100-200个节点,保证环上有1000-2000个节点;
一般5个Redis集群,则每个节点虚拟200-400个节点,保证节点数是1000-2000之间,这样才能保证数据分布均衡。
引入虚拟节点后,会提高节点的均衡度,还会提高系统的稳定性(当节点变化时,会有不同的节点共同分担系统的变化)。
而且,有了虚拟节点后,还可以为硬件配置更好的节点增加权重,比如对权重更高的节点增加更多的虚拟节点即可。
因此,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
5.总结:
一致性Hash算法,主要是考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来的情况。如何保证当系统的节点数目发生变化的时候(新增/删减),我们的系统仍然能够对外提供良好的服务(不用停掉所有redis服务),这是值得考虑的!
6.hash槽
基本概念:
槽可以理解为分区,数据都是存放在分区中的,然后分区与机器进行动态绑定。
redis-cluster把所有的“物理节点”映射到[0-16383]槽上(不一定是平均分配),cluster 负责维护node<->slot<->value。
产生原因:
如果Redis只用复制功能做主从,那么当数据量巨大的情况下,单机情况下可能已经承受不下一份数据,更不用说是主从都要各自保存一份完整数据。在这种情况下,数据分片是一个非常好的解决办法。
因此可以借助hash槽自动对数据分片,并落到各个节点上分散存储。通过为每个节点指派不同数量的槽,可以控制不同节点负责的数据量和请求数。
hash方式:
一个redis集群包含 16384 个哈希槽,数据库中的每个数据都属于这16384个哈希槽中的一个。redis集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。
一个redis节点包含N个槽,数据通过hash算法哈希到固定的槽里,所以槽只是决定了数据的存放位置,当多个数据hash出来的结果相同时,他们就被分配到相同的槽里,即也会映射到相同的服务节点上。
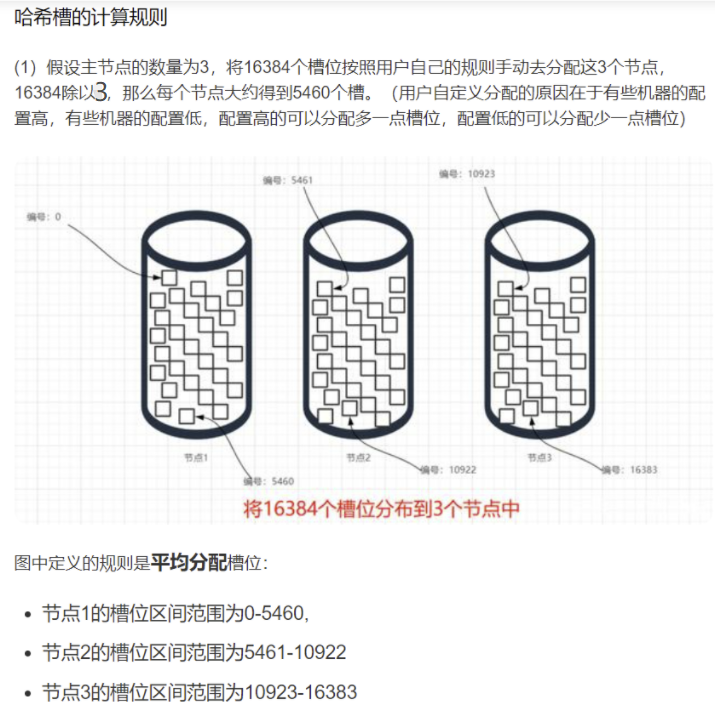
为什么redis集群采用“hash槽”来解决数据分配问题,而不采用“一致性hash”算法呢?
- 一致性哈希的节点分布基于圆环,无法很好的手动控制数据分布,比如有些节点的硬件差,希望少存一点数据,这种很难操作(还得通过虚拟节点映射,总之较繁琐)。
- 而redis集群的槽位空间是可以用户手动自定义分配的,类似于 windows 盘分区的概念,可以手动控制大小。
- 其实,无论是 “一致性哈希” 还是 “hash槽” 的方式,在增减节点的时候,都会对一部分数据产生影响,都需要我们迁移数据。当然,redis集群也提供了相关手动迁移槽数据的命令。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)