分库分表:如何解决数据量大读写缓慢
一、 引言一个系统,目前订单数据量已达上亿,并且每日以百万级别的速度增长,甚至之后还可能是千万级。面对如此庞大的数据量,那么一旦数据量疯狂增长,必然造成读写缓慢。那么,为了使系统能够抗住千万级数据量的压力,都有哪些解决方案呢?二、 分表分库当数据库表读写缓慢的时候,我们第一时间考虑到的是优化程序读写模块,调整软件架构;不过,对于单库单表而言,一旦数据量疯狂增长,无论是IO还是会CPU都会扛不住,单
一、 引言
一个系统,目前订单数据量已达上亿,并且每日以百万级别的速度增长,甚至之后还可能是千万级。
面对如此庞大的数据量,那么一旦数据量疯狂增长,必然造成读写缓慢。
那么,为了使系统能够抗住千万级数据量的压力,都有哪些解决方案呢?
二、 分表分库
当数据库表读写缓慢的时候,我们第一时间考虑到的是优化程序读写模块,调整软件架构;不过,对于单库单表而言,一旦数据量疯狂增长,无论是IO还是会CPU都会扛不住,单单从软件上来解决优化效果有限。
我们这里要介绍的解决方案是:分表分库,即先将表进行拆分,再进行分布存储。
三、 拆分储存的技术选型
拆分存储常用的解决方案有4种,包括:MySQL分区技术、NoSQL、NewSQL、基于MySQL的分表分库。
3.1 MySQL分区技术
我们先来看下MySQL官方文档的MySQL架构图
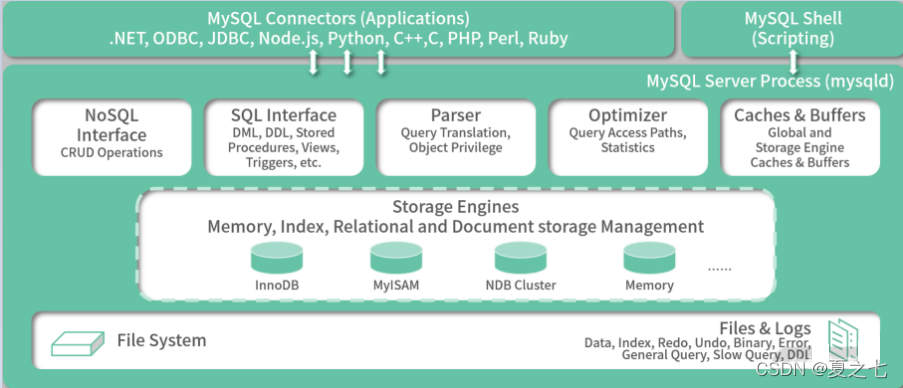
从上面的MySQL架构图,不难发现MySQL的分区主要在文件存储层做文章,它可以将一张表的不同行存放在不同存储文件中。实际应用中,不建议使用MySQL分区技术,主要原因有三个:
- MySQL实例只有一个,它仅仅分摊了存储,无法分摊请求负载。
- MySQL的分区对用户透明,因此用户在实际操作的时候往往给不太注意,使得跨分区操作严重影响系统性能。
- MySQL存在其他一些限制,比如不支持query cache、位操作表达式等。
3.2 NoSQL
比较典型的NoSQL就是MongoDB。
MongoDB的分片功能从并发性和数据这2个角度已经能满足一般大量数据的需求。
不过还是需要注意以下3大要点:
- 约束考量:MongoDB不是关系型数据库,而是文档型数据库。它的每一行记录都是一个结构灵活可变的Json,比如存储非常重要的订单时,就不能使用MongoDB,因为订单数据必须使用强约束的关系型数据库存储。
- 业务功能考量:事务、锁、SQL、表达式等操作都在MySQL验证过,MySQL能满足所有的业务需求。MongoDB却不能。
- 稳定性考量:MySQL在实践考验过,NoSQL待验证。
3.3 NewSQL
NewSQL 技术还比较新,但从稳定性和功能扩展性两方面考量后,最终没有使用,具体原因与 MongoDB 类似。
3.4 基于MySQL的分表分库
什么是分表分库?
分表是将一份大的表数据拆分存放到多个结构一样的拆分表;
分库是将一个大的数据库拆分成多个结构一样的小库。
分库分表对第三方依赖比较少,业务逻辑灵活可控,本身不需要非常复杂的底层原理,也不需要重新做数据库,只是根据不同的逻辑使用不同的SQL语句和数据源而已。
四、 分库分表技术通用需求
如果使用分库分表,有3个技术通用需求需要实现:
1)SQL组合:因为关联的表明是动态的,因此需要根据逻辑组装动态的SQL;
2)数据库路由:因为数据库名也是动态的,因此需要通过不同的逻辑使用不同的数据库;
3)执行结果合并:有些需求需要通过多个分库执行, 再合并归集起来。
目前市面上能解决上面问题的中间件分为2类:Proxy模式和Client模式。
4.1 Proxy 模式
借用ShardingSphere官方文档里的图进行说明,重点看Sharding-Proxy层

该模式把SQL组合、数据库路由、执行结果合并等功能全部存放在一个代理服务中,而与分表分库相关的处理逻辑全部存放在另外服务中。这种模式的优点是:对业务代码无入侵,业务值需要关注自身的业务逻辑即可。
4.2 Client 模式
借用ShardingSphere官方文档的图进行说明
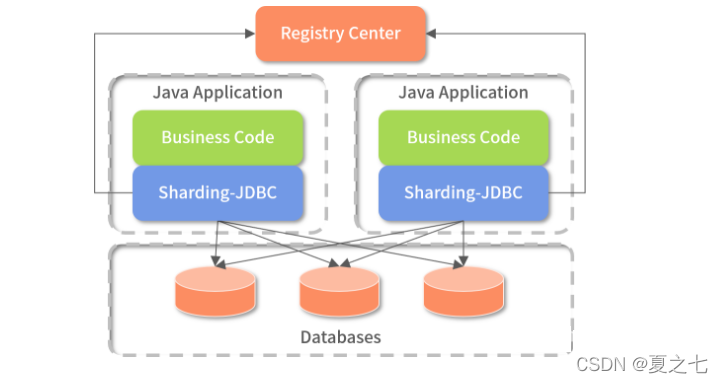
该模式把分表分库相关逻辑放在客户端,一般客户端的而应用会引用一个jar,然后再jar中处理SQL组合、数据库路由、执行结果合并等相关功能。
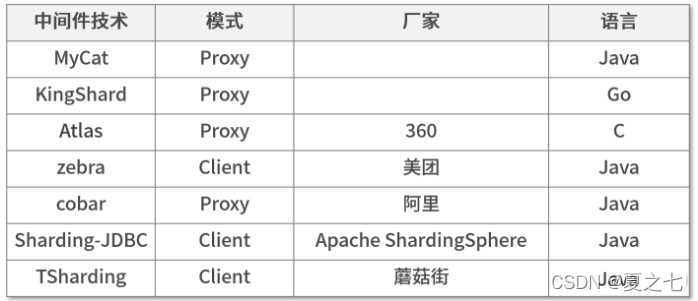
市面上,上面两种的模式中间件有:
Proxy和Client模式优缺点比较:
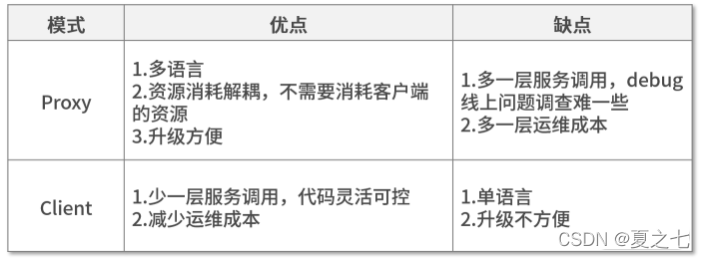
在实际应用中,我们可以根据自己的需求选择适合自己的模式。
五、 分库分表实现思路
5.1、 使用什么字段作为分片键
我们以下面订单表,选择使用Client模式为例进行说明。
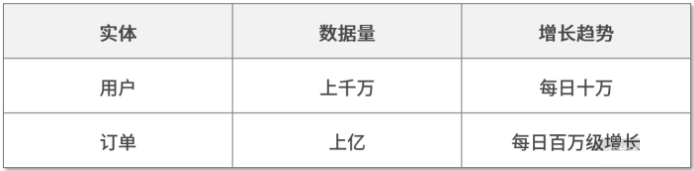
把上表中的数据拆分成了一个订单表,表中主要的数据结构如下:
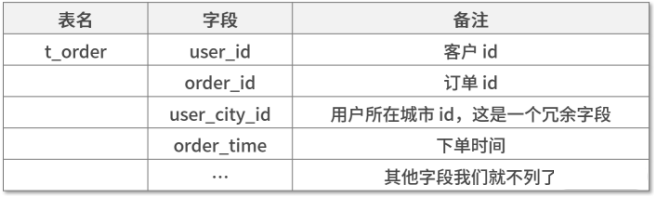
选择字段作为分片键时,需要考虑3点要求:
1)数据尽量均匀分布在不同表或库;
2)跨库查询尽量减少;
3)这个字段值不会变。
上表中,我们使用user_id作为分片主键,为什么这么分呢?主要是依据业务需求。
如一些常见的业务需求:
- 用户需要查询所有订单,订单数据中肯定包含不同的order_time;
- 后台需要根据城市查询当地的订单;
- 后台需要统计每个时间段的订单趋势。
根据上面的需求,判断优先级,用户操作就是第一个需求必须优先满足。
这时如果使用user_id作为订单的分片字段,就能保证每次用户查询数据时在一个分库的一个分表里即可获取数据。
使用user_id作为分片主键,在分表分库查询时,首先会把user_id作为参数传过来。
5.2、 分片的策略是什么
通用的分片策略分为:根据范围分片、根据hash值分片、根据hash值及范围分片。
1)根据范围分片
如果用户id是自增型数字,我们把用户id按照没100w份分为一个库,每10w份分为一个表的形式进行分片:
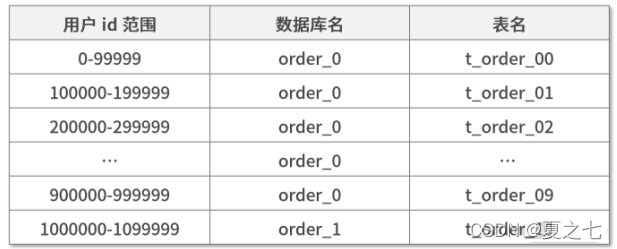
2)根据hash值分片
指的是根据用户id的hash值mod一个特定的数进行分片(为了扩展,一般时2的几次方)。
3)根据hash值及范围分片
先按照范围分片,再根据hash值取模分片。
如:表名=order_#user_id%10#_#hash(user_id)%8,即被分成了 10*8=80 个表。为了方便你理解,我们画个图说明下,如下图所示:
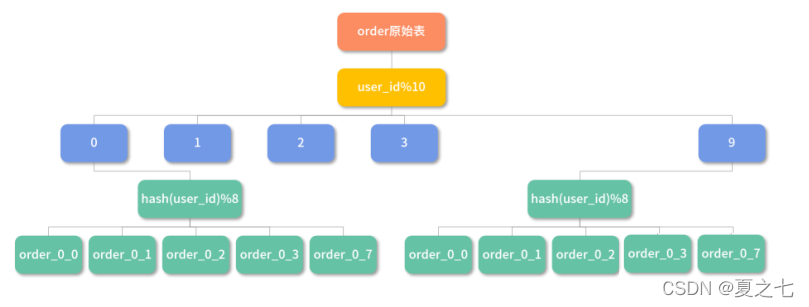
如何选择分片策略?
上述3种不同点额分片策略,应该如何选择?
我们只需要考虑一点:假设数据量变大后,需要我们把表分得更细,此时保证迁移的数据尽量少即可。
因此根据hash值分片时一般建议拆分成2的N次方表,比如分成8张表,数据迁移时把原来的每张表拆一半出来组成新的表,这样数据迁移量就小了。
项目经验值:根据用户id的hash值取模32,把数据分成32个数据库,每个数据库再分成16张表。
可以做个简单的计算:
假设每天订单量1000万,每个库日增 1000万/32=31.25万,每个表日增1000万/32/16=1.95万。
如果每天订单量1000万,3年后每个表的数据量就是1.95x3x365=2135万,还在可控范围内。
如果业务增长特别快,并且运维还扛得住,为避免以后出现扩容问题,建议库分得越多越好。
5.3、 业务代码如何修改
修改业务代码部分与业务强关联,具体如何修改并不具备参考性。不需要需要注意以下几点:
- 微服务对于特定表的分表分库,影响面只在该表所在的服务中,如果是一个单体架构的应用做分表分库,就比较麻烦;
- 在互联网架构中,基本不适用外键约束;
- 随着查询分离的流行,后台系统中有很多操作需要跨库查询,导致系统性能差,此时分表分库一般会解耦查询分离一起操作:先将所有数据在ES索引一份,再使用ES在后台直接查询数据。如果订单数据量很大,还有一个常见的做法:先将ES中存储索引字段(作为查询条件的字段),再将详情数据放在HBase中。
5.4、 历史数据迁移
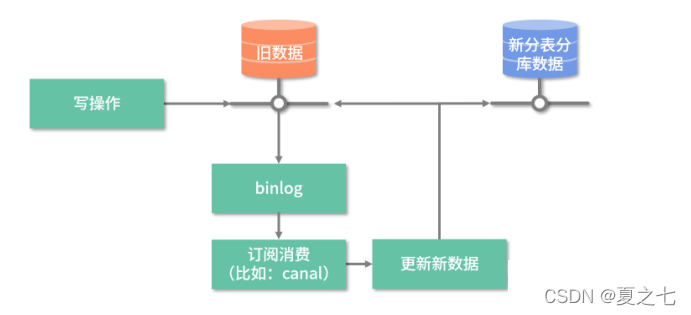
数据迁移基本思路:
存储数据直接迁移,增量数据监听binlog,然后通过canal通知迁移程序搬运数据,新的数据库拥有全量数据,且校验通过后逐步切换流量。
数据迁移解决方案详细步骤:
- 上线canal,通过canal触发增量数据的迁移;
- 迁移数据库脚本测试通过后,将老数据迁移到新的分表分库中;
- 注意迁移量数据与迁移老数据的时间差,确保全部数据都被迁移过去,无遗漏;
- 第2、3步都运行完成后,新的分表分库中已经拥有了全量数据了,这时我们可以运行数据验证的程序,确保所有数据都存放在新的数据库中;
- 到这步数据迁移就算完成了,之后就是新版本代码上线。至于是灰度上还是直接上,需要根据实际情况决定,回滚方案也是一样。
5.5、 未来的扩容方案是什么
随着业务的发展,如果原来的分片设计已经无法满足日益增长的数据需求,就要考虑扩容,扩容依赖下面2点:
- 分片策略是否可以让新表数据的迁移源只是1个旧表,而不是多个旧表,这就是前面建议使用2的N次方分表的原因;
- 数据迁移:需要把旧分片上的数据迁移到新的分片上,这个方案与上面提及的历史数据迁移一样。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)