MySQL索引为什么不用跳表,Redis为什么不用B+树
B+树
MySQL索引为什么不用跳表,Redis为什么不用B+树
知识引入
在讲述问题之前,我相信来到这里的朋友一定都是事先了解过 B+ 树、跳表这两种数据结构了的。
所以下面介绍这两种数据结构的时候,只是整体描述一下,并不会细致地讲什么是 B+ 树,什么是跳表;毕竟咱们今天的主要内容并不是介绍数据结构。
什么是MySQL中的B+树?
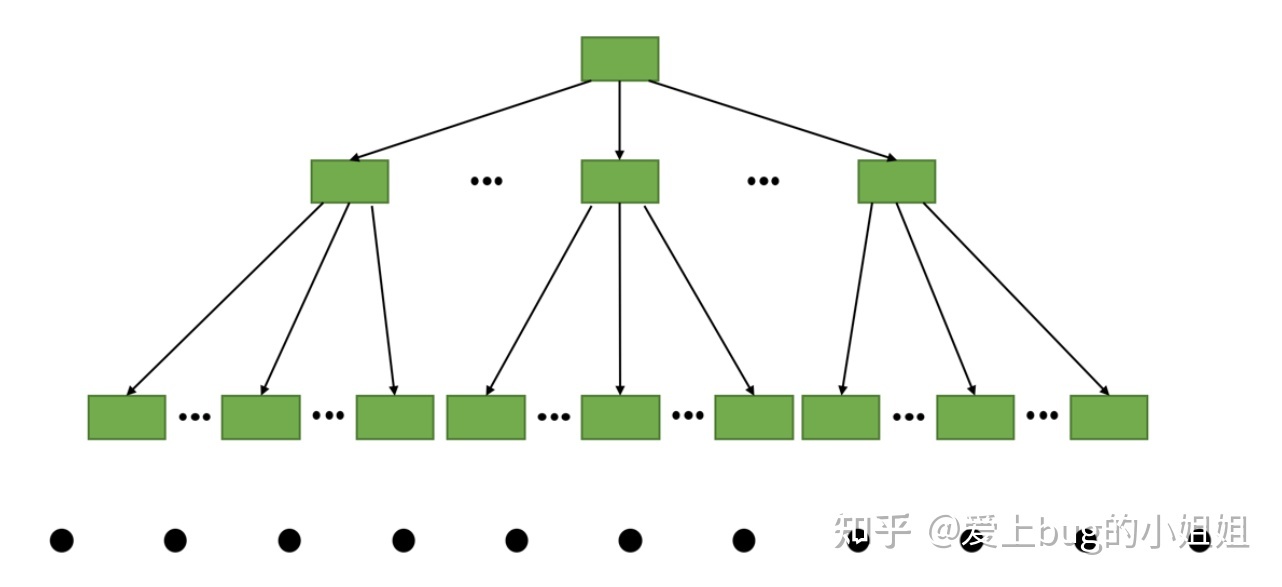
- B+树一般由多个页、多层级组成,在MySQL中每个页 16 kb。
- 主键索引的 B+ 树的叶子结点才是数据,非叶子结点存放的是索引信息
- 上下层的页通过单指针相连
- 同一层级的相邻的数据页通过双指针相邻
B+ 树的大致图像如下:

什么是跳表?
跳表的结构就像是由单链表结构衍生出来的,但是它的效率却比普通的单链表高上很多
跳表的最底层是单链表,但是跳表也是具有多层级的

在普通的单链表中,不管要寻找什么元素,都是需要从头结点开始不断往下找,一个个找,直到找到为止,效率是非常低的;而使用了跳表就不一样了,比如要寻找 6 ,跳表只需要 1, 5, 6就找到了,而单链表则需要 1, 2, 3, 4, 5, 6。
从这小小的例子中,我们也能感受到跳表的查询效率确实是比单链表上升了不少
跳表和B+树的异同点
相同点:
两种数据结构的查询效率都是杠杠的,而且都支持范围查询,不然MySQL就不用 B+树,Redis就不用跳表了。
不同点(新增数据方面):
B+ 树在新增数据的时候可能面临页分裂的问题,而且它还需要维护各种索引页;
跳表在添加数据的时候,并没有什么页分裂的说法,就算是索引分配也是非常的简单的,它只需要利用一个随机函数随机出新增数据需要出现的层级数就可以了,最低层级就是该数据不建立索引,只待在最底层的单链表处。
前面讲述了这么多铺垫,下面终于开始进入咱们今天的正题了。。。
出发!
MySQL为什么不用跳表建立索引?
MySQL选用 B+ 树构建索引,主要是因为 B+ 树是多叉结构,而且根据它结构组织数据页/索引页,存放2kw数据也只是需要 3 层左右就可以了,目前实践中,B+树索引几乎没有超过 4 层,换句话说,如果是 B+ 树索引的话,查找一次数据,一般最多也就 3 次磁盘 IO ;而在跳表中就不一样了,2kw的数据在跳表中存储,如果想要达到二分查找的效率的话,最起码也要2^24层级才能实现,而每个层级的数据都是分散在不同的数据页中的,所以在查找数据的过程中,跳表可能需要进行 24次磁盘IO。
我们都知道磁盘IO是非常消耗性能的,能够少磁盘IO就少磁盘IO的,所以单凭这个点跳表也不会被MySQL选做索引。
当然啦,以上的分析只是对于查询数据而言的,如果是就写数据而言的话,跳表会略胜一筹,因为在新增数据的时候,跳表不需要维护什么页,什么页的,它只需要一个随机数就可以了,显然高效。
既然MySQL都抛弃了跳表,为什么Redis中又要使用跳表呢??
Redis为什么要用跳表实现zset
相信各位学过Redis底层数据结构的都知道,Redis中的 Zset 底层是由跳表实现的!
为什么呢?
其实啊,主要是因为Redis是一个基于内存的数据库,它的数据几乎都在内存中,就算是使用跳表,就算 2kw数据会达到 2^24次方的层级,但是这些都不是问题,因为它们都是在内存中,不存在刚刚讨论的磁盘IO影响性能的问题。
而且Redis中使用跳表还不需要担心 B+树的页分裂之类的问题。
总结
问题一:MySQL为什么不用跳表?
跳表比B+树层级更高,需要更多的磁盘IO
问题二:Redis中为什么不用B+树?
Redis是基于内存的数据库,不用考虑磁盘IO问题,采用跳表,不用考虑B+树页分裂等问题

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)