Kafka生产与消费--简单示例
下面用java给出一个kafka生产与消费的简单示例:运行环境:java:java version "1.8.0_291"kafka:<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.11</artifactId><version>2.1.0&
·
下面用java给出一个kafka生产与消费的简单示例:
运行环境:
java:java version "1.8.0_291"
kafka:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.1.0</version>
</dependency>
与消费者相关的3个重要概念:
- 分组:任何消费者Consumer都是处于一个分组内的,而分组是跟offset紧密关联的。
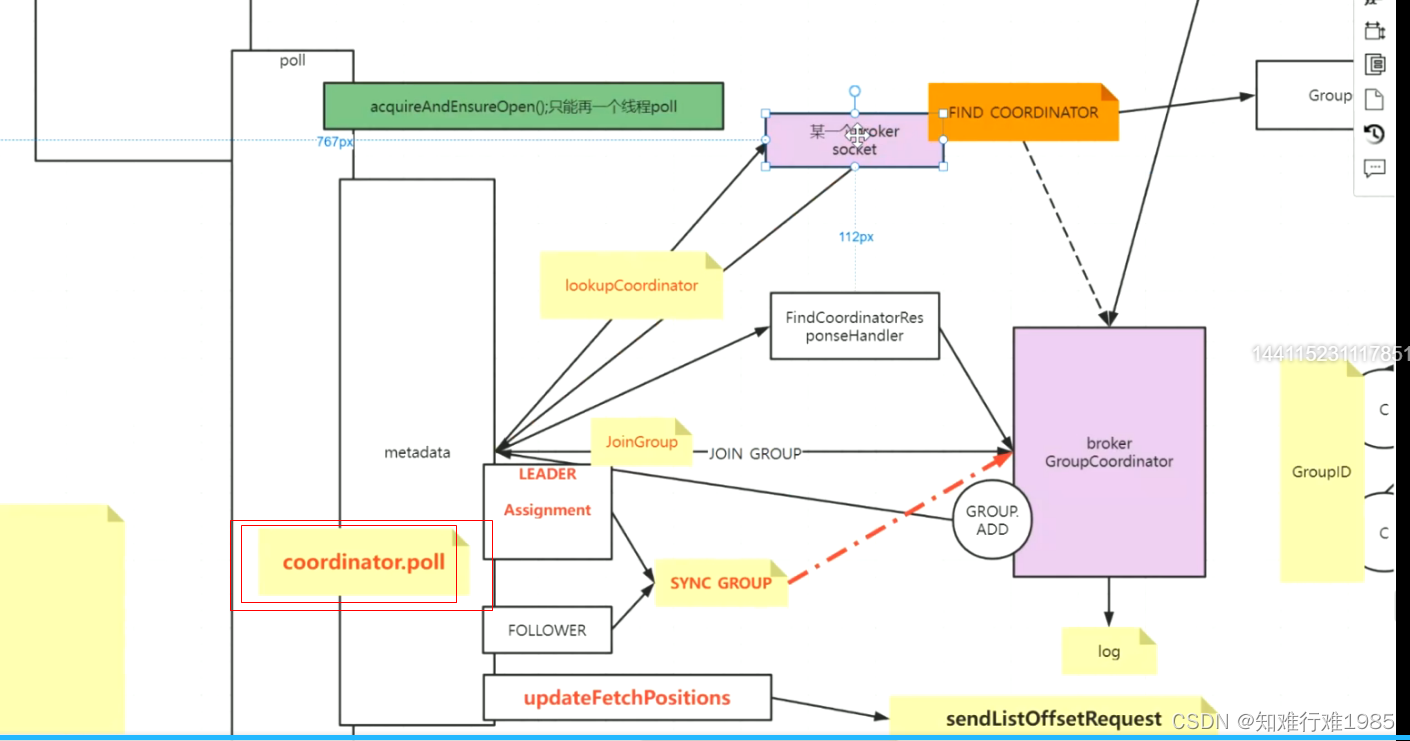
- GroupCoordinator: 分组协调器,位置在broker中,每个分组对应一个GroupCoordinator,并且通过groupId的哈希取模算法,跟consumer offset topic的一个分区一一对应,该分组内所有consumer的offset都存储在这个分区。当然了GroupCoordinator还有别的作用,在这里不一一赘述。每个broker中仅有一个GroupCoordinator,可以管理多个分组。
- ConsumerCoordinator :消费者协调器,位于消费者这一端,每个消费者对应一个ConsumerCoordinator,消费者消费完消息,持久化offset的时候,要用到它。当然了,它还有别的作用,在这里不再赘述。
- ConsumerCoordinator发送出去的offset信息,被broker中的GroupCoordinator持久化到对应的consumer offset topic 分区。
在这里面,offset的维护是非常重要的一点:
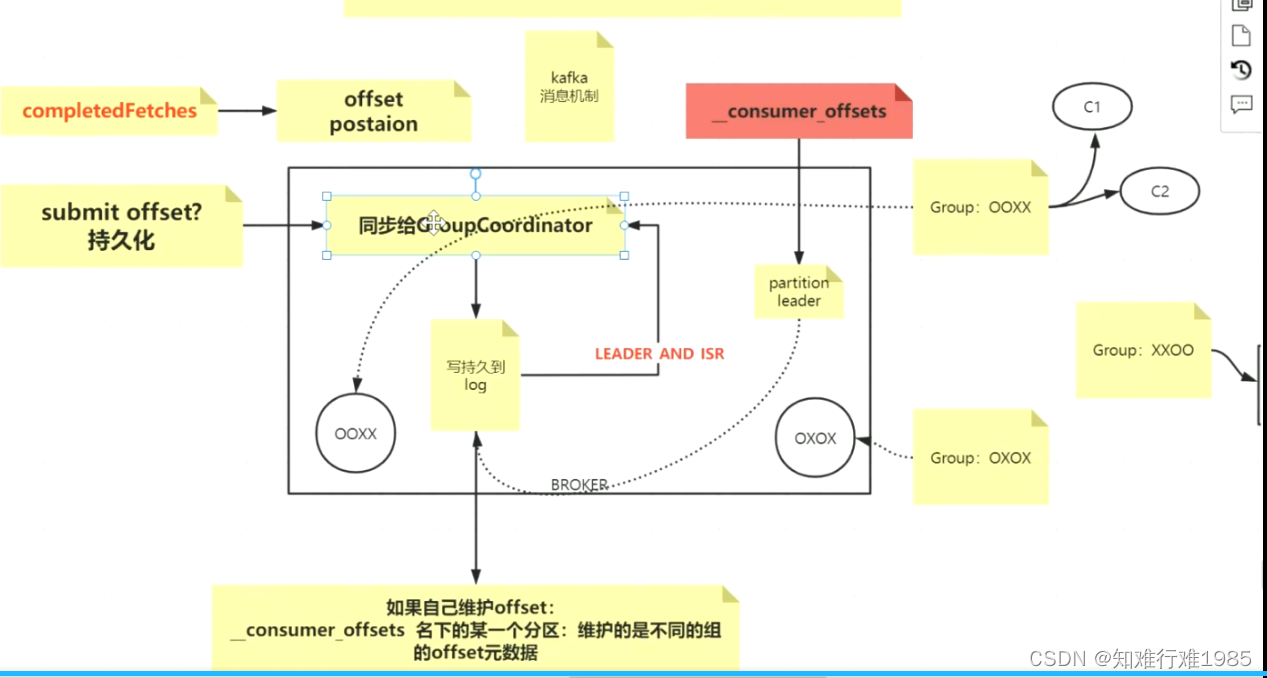
Consumer工作流程:
package com.mashibing.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import java.nio.channels.FileChannel;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* @author: 马士兵教育
* @create: 2020-12-13 20:14
*/
public class Lesson01 {
/*
创建TOPIC
kafka-topics.sh --zookeeper node03:2181/kafka --create --topic msb-items --partitions
2 --replication-factor 2
*/
@Test
public void producer() throws ExecutionException, InterruptedException {
String topic = "msb-items";
Properties p = new Properties();
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092");
//kafka 持久化数据的MQ 数据-> byte[],不会对数据进行干预,双方要约定编解码
//kafka是一个app::使用零拷贝 sendfile 系统调用实现快速数据消费
p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//1,0,-1 三个值,设置为-1表示每次发送消息到broker,消息不光要到达leader partition,还要同步到其follower partition。
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p);
//现在的producer就是一个提供者,面向的其实是broker,虽然在使用的时候我们期望把数据打入topic
/*
msb-items
2partition
三种商品,每种商品有线性的3个ID
相同的商品最好去到一个分区里
*/
while(true){
for (int i = 0; i < 3; i++) {
for (int j = 0; j <3; j++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item"+j,"val" + i);
Future<RecordMetadata> send = producer
.send(record);
//虽然producer.send(...)是一个异步的方法,但是调用send.get()后,又会同步阻塞等待。
RecordMetadata rm = send.get();
int partition = rm.partition(); //消息被存到哪个分区了
long offset = rm.offset(); //消息在分区的offset
System.out.println("key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset);
}
}
}
}
public static void main(String[] args) {
System.out.println(System.currentTimeMillis()-1*1000);
}
@Test
public void consumer(){
/*
kafka-consumer-groups.sh --bootstrap-server node02:9092 --list
*/
//基础配置
Properties p = new Properties();
p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092");
p.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//消费的细节
//需要配置消费者所在的group,如果不显式配置,则会自动为其分配一个
p.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"OOXX");
//KAKFA IS MQ IS STORAGE
p.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");//第一次启动,米有offset,设置其从最开始的offset开始
/**
* "What to do when there is no initial offset in Kafka or if the current offset
* does not exist any more on the server
* (e.g. because that data has been deleted):
* <ul>
* <li>earliest: automatically reset the offset to the earliest offset
* <li>latest: automatically reset the offset to the latest offset</li>
* <li>none: throw exception to the consumer if no previous offset is found for the consumer's group</li><li>anything else: throw exception to the consumer.</li>
* </ul>";
*/
p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");//自动提交时异步提交,这种方式可能->丢数据&&重复数据
//一个运行的consumer ,那么自己会维护自己消费进度
//一旦你自动提交,但是是异步的,可能出现下面的问题
//1,还没到时间,挂了,没提交(但是业务已经执行完毕),重起一个consuemr,参照offset的时候,会重复消费
//2,一个批次的数据还没写数据库成功,但是这个批次的offset背异步提交了,挂了,重起一个consuemr,参照offset的时候,会丢失消费
// p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");//5秒
// p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,""); // POLL 拉取数据,弹性,按需,拉取多少?
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p);
//kafka 的consumer会动态负载均衡,如果只有一个consumer,其会处理topic下所有的分区的消息
consumer.subscribe(Arrays.asList("msb-items"), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("---onPartitionsRevoked:");
Iterator<TopicPartition> iter = partitions.iterator();
while(iter.hasNext()){
System.out.println(iter.next().partition());
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("---onPartitionsAssigned:");
Iterator<TopicPartition> iter = partitions.iterator();
while(iter.hasNext()){
System.out.println(iter.next().partition());
}
}
});
/**
* 以下代码是你再未来开发的时候,向通过自定时间点的方式,自定义消费数据位置
* 也就是说,消费者想要消费某个时间之后的消息,就可以通过这种方式。
* 其实本质,核心知识是seek方法
*
* 举一反三:
* 1,通过时间换算出offset,再通过seek来自定义偏移
* 2,如果你自己维护offset持久化~!!!通过seek完成
*
*/
Map<TopicPartition, Long> tts =new HashMap<>();
//通过consumer取回自己分配的分区 as
Set<TopicPartition> as = consumer.assignment();
while(as.size()==0){
consumer.poll(Duration.ofMillis(100));
as = consumer.assignment();
}
//自己填充一个hashmap,为每个分区设置对应的时间戳
for (TopicPartition partition : as) {
// tts.put(partition,System.currentTimeMillis()-1*1000);
tts.put(partition,1610629127300L);
}
//通过consumer的api,取回timeindex的数据
Map<TopicPartition, OffsetAndTimestamp> offtime = consumer.offsetsForTimes(tts);
for (TopicPartition partition : as) {
//通过取回的offset数据,通过consumer的seek方法,修正自己的消费偏移
OffsetAndTimestamp offsetAndTimestamp = offtime.get(partition);
long offset = offsetAndTimestamp.offset(); //不是通过time 换 offset,如果是从mysql读取回来,其本质是一样的
System.out.println(offset);
consumer.seek(partition,offset);
}
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
while(true){
/**
* 常识:如果想多线程处理多分区
* 每poll一次,用一个语义:一个job启动
* 一次job用多线程并行处理分区
* 且,job应该被控制是串行的
* 以上的知识点,其实如果你学过大数据
*/
//微批的感觉
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));// 0~n
if(!records.isEmpty()){
//以下代码的优化很重要
System.out.println("-----------"+records.count()+"-------------");
Set<TopicPartition> partitions = records.partitions(); //每次poll的时候是取多个分区的数据
//且每个分区内的数据是有序的
/**
* 按照分区依次消费
* 如果手动提交offset
* 1,按消息进度同步提交
* 2,按分区粒度同步提交
* 3,按当前poll的批次同步提交
*
* 思考:如果在多个线程下
* 1,以上1,3的方式不用多线程
* 2,以上2的方式最容易想到多线程方式处理,有没有问题?
*/
for (TopicPartition partition : partitions) {
List<ConsumerRecord<String, String>> pRecords = records.records(partition);
// pRecords.stream().sorted()
//在一个微批里,按分区获取poll回来的数据
//线性按分区处理,还可以并行按分区处理用多线程的方式
Iterator<ConsumerRecord<String, String>> piter = pRecords.iterator();
while(piter.hasNext()){
ConsumerRecord<String, String> next = piter.next();
int par = next.partition();
long offset = next.offset();
String key = next.key();
String value = next.value();
long timestamp = next.timestamp();
System.out.println("key: "+ key+" val: "+ value+ " partition: "+par + " offset: "+ offset+"time:: "+ timestamp);
TopicPartition sp = new TopicPartition("msb-items", par);
OffsetAndMetadata om = new OffsetAndMetadata(offset);
HashMap<TopicPartition, OffsetAndMetadata> map = new HashMap<>();
map.put(sp,om);
//持久化offset级别1
//手动提交offset:用Sync方式。每消费一条消息提交一次,会产生大量IO,降低系统性能
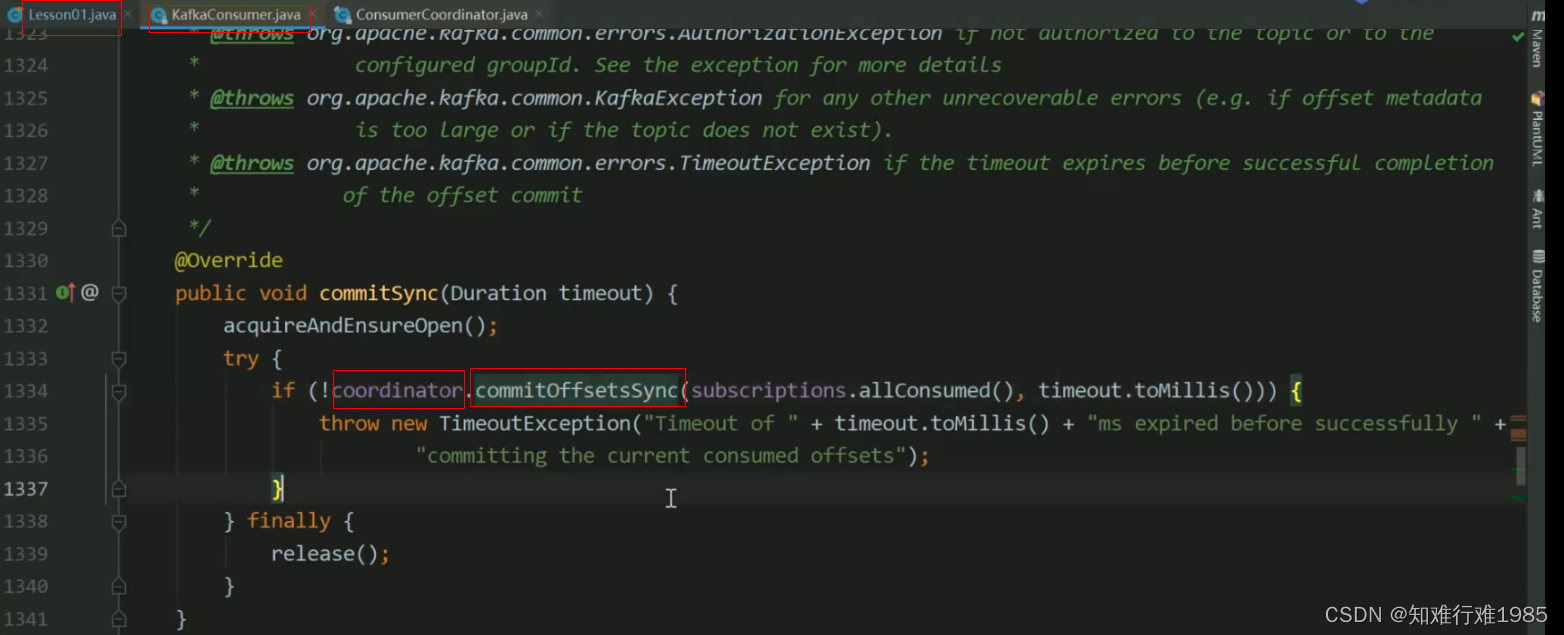
consumer.commitSync(map);//这个是最安全的,每条记录级的更新,第一点
//单线程,多线程,都可以
}
//持久化offset级别2
//手动提交offset:用Sync方式。每消费完一个分区,提交这个分区的offset,大大减少IO次数,提高系统性能
long poff = pRecords.get(pRecords.size() - 1).offset();//获取分区内最后一条消息的offset
OffsetAndMetadata pom = new OffsetAndMetadata(poff);
HashMap<TopicPartition, OffsetAndMetadata> map = new HashMap<>();
map.put(partition,pom);
consumer.commitSync( map );//这个是第二种,分区粒度提交offset
/**
* 因为你都分区了
* 拿到了分区的数据集
* 期望的是先对数据整体加工
* 小问题会出现? 你怎么知道最后一条小的offset?!!!!
* 感觉一定要有,kafka,很傻,你拿走了多少,我不关心,你告诉我你正确的最后一个小的offset
*/
}
//持久化offset级别3
//手动提交offset:用Sync方式。全部完事儿,再提交offset(持久化)
consumer.commitSync();//这个就是按poll的批次提交offset,第3点
// Iterator<ConsumerRecord<String, String>> iter = records.iterator();
// while(iter.hasNext()){
// //因为一个consuemr可以消费多个分区,但是一个分区只能给一个组里的一个consuemr消费
// ConsumerRecord<String, String> record = iter.next();
// int partition = record.partition();
// long offset = record.offset();
// String key = record.key();
// String value = record.value();
//
// System.out.println("key: "+ record.key()+" val: "+ record.value()+ " partition: "+partition + " offset: "+ offset);
// }
}
}
}
}

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)