【Kafka持久化机制】
Kafka持久化机制
Kafka持久化机制
一、Kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统。
常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
架构图
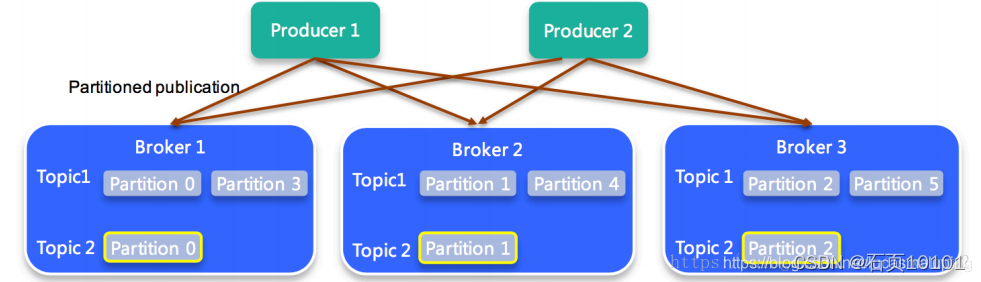
部分名词解释
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成,下面会详细说明。
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
二、Topic中Partition分布
Topic与Partition的关系
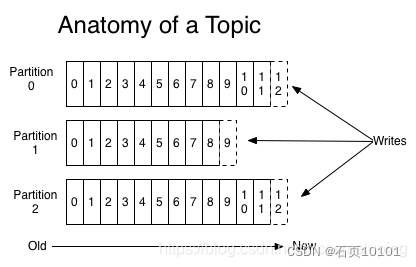
实机操作
当前笔者本机为例,server.properties部分配置如下
PS:笔者电脑为Mac单机brew部署
详见链接:Mac安装Kafka
# kafka持久化的路径
log.dirs=/usr/local/var/lib/kafka-logs
# segment file最大值,手动设置为50kb(默认为1G)
log.segment.bytes=51200
1、 创建一个新的Topic,名为ods_base_log_test,定义3个分区
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic ods_base_log_test
2、向ods_base_log_test打数据,可观察到Topic中Partition为一个目录
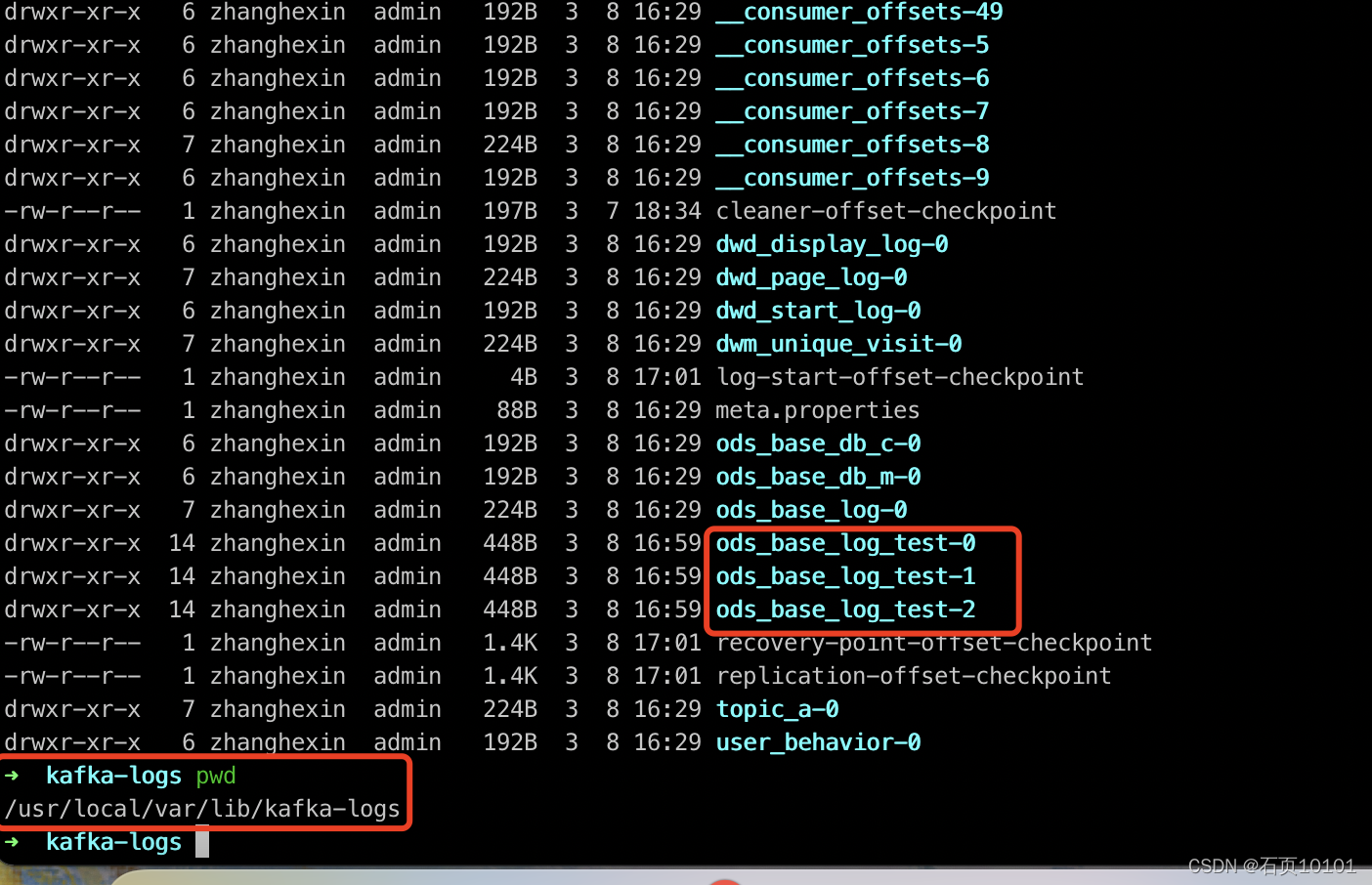
由上图可知:在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partition命名规则为topic名称+有序序号,第一个partition序号从0开始,序号最大值为partitions数量减1。
三、Partition中文件存储方式
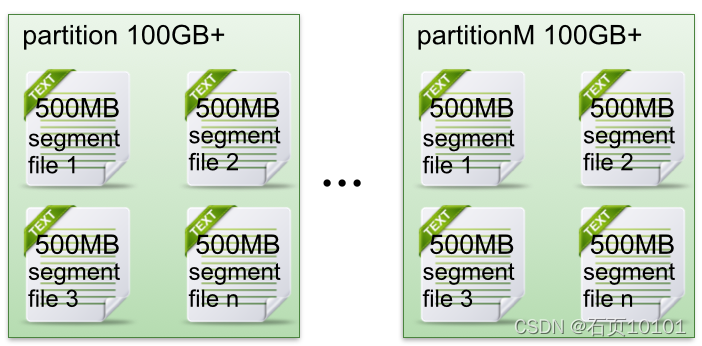
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。可快速删除无用文件,有效提高磁盘利用率。
总结:kafka 这种分片和分段策略,避免了数据量过大时,数据文件无限扩张带来的隐患,更有助于消息文件的维护以及被消费的消息的清理。
实机操作
1、目前配置文件中,为方便演示,将segment最大值设置为50KB
# segment file最大值,手动设置为50kb
log.segment.bytes=51200
2、基于前文场景,向Topic推入数据后,进入0号分区,可发现log文件是严格按照50KB进行划分的
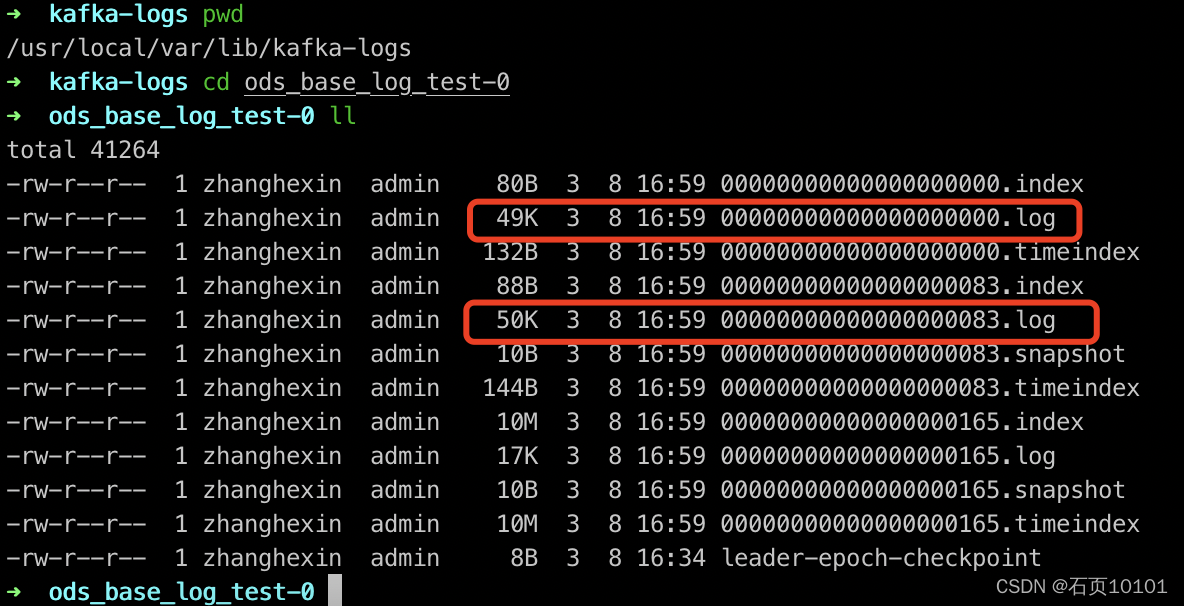
四、Partition中Segment文件存储结构
Segment结构:
segment file主要由两部分组成,分别是index file和data file,两部分数据成对出现,后缀".index/.timeindex"和".log"分别表示索引文件与数据文件。
segment 文件命名规则:partion 全局的第一个segment 从0开始,后续每个 segment文件名为上一个 segment文件最后一条消息的 offset值。数值最大为 64位 long大小,19位数字字符长度,没有数字用0填充。
以前文ods_base_log_test,0号分区为例,segment中index与datafile对应关系物理结构如下:
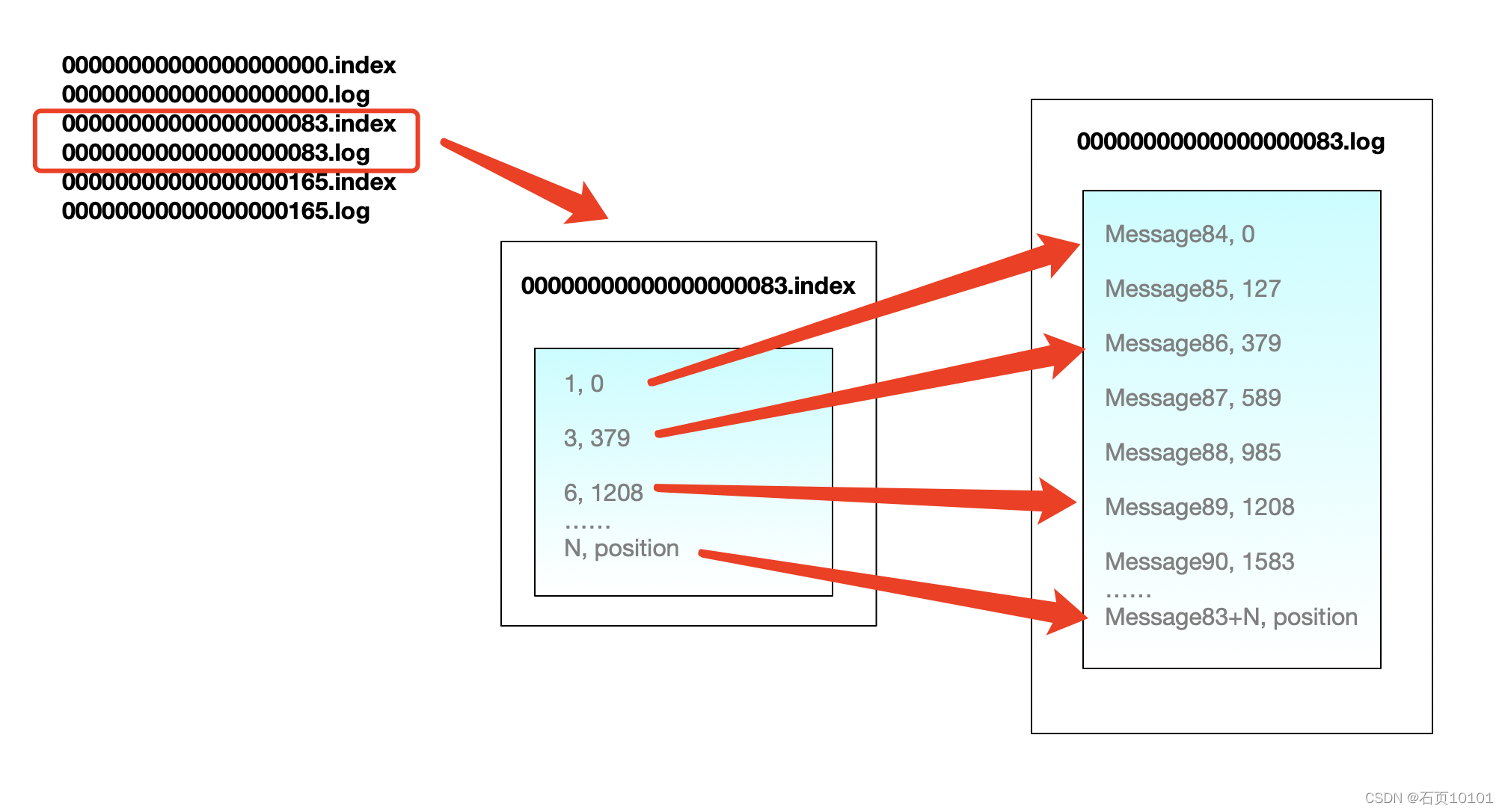
如上图可见索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
其中以索引文件中元数据3,379为例,依次在数据文件中表示第3个message(在全局partiton表示第86个message)、以及该消息的物理偏移地址为397。
Message结构

参数说明:
| 关键字 | 参数说明 |
|---|---|
| 8 byte offset | 在partition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在partition(分区)内的位置。即offset表示partition的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据 |
五、在Partition中如何通过offset查找Message
基于前文,例如需要读取0号分区,offset=87的message,通过下面2个步骤查找。
- 第一步查找segment file,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000000083.index的消息量起始偏移量为84 = 83 + 1.同样,第三个文件00000000000000000165.index的起始偏移量为166=165 + 1,其他后续文件依次类推。以起始偏移量命名并排序这些文件,只要根据offset二分查找文件列表,就可以快速定位到具体文件。 当offset=87时定位到00000000000000000083.index|log
- 第二步通过segment file查找message 通过第一步定位到segment file,当offset=87时,依次定位到00000000000000000083.index的元数据物理位置和00000000000000000083.log的物理偏移地址,然后再通过00000000000000000083.log顺序查找直到offset=87为止。
说明:segment index file稀疏索引,即不会给所有的消息都建立索引,只会将日志文件的部分记录存储在索引文件中,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
引用

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)