Mongodb实战:豆瓣电影排行榜分析及结果展示设计
一、研究背景1二、豆瓣电影功能设计2三、豆瓣电影功能实现3一、研究背景1.1 背景随着云计算和大数据时代的到来,每时每刻都会产生海量的数据,数据量成指数型增长,这些趋势使得科学技术发展日新月异。面对大量的数据,进行有效的整合分析,就可以提供有价值的数据分析。Mongodb作为一个可扩展、开源、表结构自由、用C++语言编写且面向文档的数据库,不仅可以作为一个实时的可操作的大数据存储系统,也可以在离线
课程大作业
一、研究背景 1
二、豆瓣电影功能设计 2
三、豆瓣电影功能实现 3
一、研究背景
1.1 背景
省略了
二、豆瓣电影功能设计
2.1
一:收集信息功能设计
(1)获取数据
用python爬取豆瓣排行榜250的影片信息,包括影片排行名次、影片名字、影片导演、影片主演、影片上映年份、影片所属地区、影片类型、影片评分、影片评价人数、影片短评。爬取每部影片对应图片,并命名为影片名字。
(2)将数据存入mongodb
将影片信息命名为“豆瓣Top250.csv”,将CSV文件导入mongodb,运用第十章第一节数据的导入导出知识点。
(3)数据展示
查询数据是否存入mongodb数据库中,运用第二章查询语言系统知识点。
二:信息管理功能设计
(1)python连接mongodb数据库。
(2)对数据进行增删查改操作,运用第四章增改删操作知识点。
(3)对数据进行分析,分析用户喜欢的电影和电影评分等信息,运用第六章聚集分析知识点。
(4)对分析所得数据进行复制集操作,运用第七章复制集知识点。
(5)文件上传与下载,运用第九章分布式文件存储系统知识点。
(6)对数据库进行备份,运用第十章管理与监控知识点。
三:信息展示功能设计
(1)网页搭建
使用Adobe Dreamweaver CS5写html文件
html文件包括:
index.html:网站主页
Grid.html:网站主体部分,显示排名较前的电影信息
Single-post.html:网站影片分析结果展示
About.html:网站其他内容,关于影片的一些信息,比如排行榜的由来、联系电话、电影其他信息。
网站中有按钮,让用户点击可以跳转到其他页面,用于界面切换。
(2)用户查看电影信息,分析结果展示
用户点开网址,即可看到网站信息。主界面为排名前几的影片及影片信息,包括影片名字和影片短评。
主界面中有个按钮,可以跳转到其他页面。当用户想要跳转界面了解其他信息时,可以点击此按钮。跳转界面包括主页,全部内容,关于我们和影片分析。其中主页为用户打开页面呈现内容,全部内容为排行榜前四十的影片内容,关于我们为与影片相关内容,影片分析为运用python和mongodb对数据进行分析结果的展示页面。
若用户想要联系网站,有个按钮,用户点击按钮跳出发送邮件界面,用户输入用户名和用户邮件地址和邮件内容,点击下方按钮即可发送邮件给网站。
三、豆瓣电影功能实现
3.1 运行环境
Python3 、mongodb 、windows10、Adobe Dreamweaver CS5
3.2 具体实现
一、收集信息功能实现
(1)python爬取数据主要代码,代码文件为“爬虫豆瓣Top250.py”
for li in lis:
name = li.xpath(".//a/span[@class='title'][1]/text()")[0]
director_actor="".join(li.xpath(".//div[@class='bd']/p/text()[1]")[0].replace(' ','').replace('\n','').replace('/','').split())
info="".join(li.xpath(".//div[@class='bd']/p/text()[2]")[0].replace(' ','').replace('\n','').split())
rating_score=li.xpath(".//span[@class='rating_num']/text()")[0]
rating_num=li.xpath(".//div[@class='star']/span[4]/text()")[0]
introduce = li.xpath(".//p[@class='quote']/span/text()")
if introduce:
movie = {'name': name, 'director_actor': director_actor, 'info': info, 'rating_score': rating_score, 'rating_num': rating_num, 'introduce': introduce[0]
else:
movie = {'name': name, 'director_actor': director_actor, 'info': info, 'rating_score': rating_score,'rating_num': rating_num, 'introduce': None}
imgurl = li.xpath(".//img/@src")[0]
movies.append(movie)
imgurls.append(imgurl)
(2)导入数据库

(3)数据展示
使用查询语句,查看数据库中数据是否导入成功,例如查找影片名为“肖申克的救赎”。

二:信息管理功能实现
(1)将python与mongodb连接,让python操作mongodb数据库。运用第九章分布式文件存储系统知识点中的连接数据库知识点。
from pymongo import MongoClient
#1.连接本地数据库服务
myclient=MongoClient('mongodb://localhost:27017/')
#2.连接本地数据库
db=myclient.test
#3.创建集合
collection=db.douban
(2)对数据进行增删查改操作,运用第二章查询知识点和第四章增改删操作知识点。
1.删除语句操作:csv文件导入到数据库时,第一行的无效数据导入了数据库中,将无效数据进行删除。
result = collection.delete_one({‘name’:‘name’ })
print(result)
将数据删除后查询无效数据是否存在,若不存在则删除成功。由图可知,无效数据已被成功删除。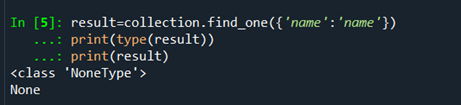
2.插入语句操作:插入新的影片信息“天气之子”,包括影片名字、影片导演、影片主演、影片上映年份、影片所属地区、影片类型、影片评分、影片评价人数、影片短评。
douban = {
'_id': 250,
'name': '天气之子',
'director_actor': '导演:新海诚 主演:醍醐虎汰朗',
'info':'2019/爱情/动画/奇幻',
'rating_score':7.1,
'rating_num':'191148人评价',
'introduce': '拥有改变天气的其妙能力'
}
result = collection.insert_one(douban)
print(result)

- 修改语句操作:影片名为“肖申克的救赎”信息更新,评价人数由2040900变为2043207
condition = {'name': '肖申克的救赎'}
douban = collection.find_one(condition)
douban['rating_num'] = '2043207人评价'
result = collection.update_one(condition, {'$set':douban})
print(result)
由图可知信息更新完成

- 查询语句操作:查询排行榜前三名影片信息,分析排行高的原因。
results=collection.find({'_id':{'$lt':3}})
print(results)
for result in results:
print(result)
分析:
排行榜前三名影片为“肖申克的救赎”、“霸王别姬”、“阿甘正传”。这三部影片都是在九十年代产生,距今已经二十多年。这三部都属于经典影片,都是一个时代的缩影。这三部电影的演员在当时都是有名的影视演员,比如张国荣先生。可见观众比较喜欢的是经典影片,而不是比较当下比较有名的电影。
(3)对数据进行分析。运用第六章聚集分析知识点。
1.运用管道模式,将数据按照rating_score降序排列
cursor = db.douban.aggregate([{"$sort":{"rating_score":-1}}])
for document in cursor:
print(document)
分析:
将电影按照评分进行降序排序,可以发现评分排名和排行榜排名不一致,所以评分高的电影排行榜名次不一定高,排行榜名次高也不代表电影评分高,这两者没有必然的联系。
对所属国家分类,可以发现评分较高的前十部的影片中,其中美国占比最大,有五部电影分别为:肖申克的救赎、控方证人、阿甘正传、辛德勒的名单、忠犬八公的故事。剩下的影片中其他国家相差不大,都有一两部上榜。中国大陆有一部电影为霸王别姬,意大利有一部电影为美丽人生。日本有两部电影为人生果实和千与千寻。法国有一部电影为这个杀手不太冷。
通过对影片所属国家的分析,可以看出人们普遍喜欢看美国的电影,评分最高的是“肖申克的救赎”,这部电影的主题是“对希望和自由的向往”,当今时代不可缺少的就是对自由、希望的向往,此电影也代表了人类对自由的渴望。
2.运用管道模式,统计不同评分个数
for i in range(0,15,1):
j=0.1*i+8.3
k=round(j,1)
cursor=db.douban.aggregate(
[
{"$match":{"rating_score":k}}
]
)
count=0
for document in cursor:
#print(document)
count=count+1
print(k)
print(count)
分析:
通过结果可知8.3分1个,8.4分4个,8.5分14个,8.6分27个,8.7分41个,8.8分44个,8.9分30个,9.0分21个,9.1分20个,9.2分23个,9.3分13个,9.4分5个,9.6个2个,9.7分1个。通过数据可知影片评分类似服从正态分布,高分和低分影片数量较少,影片数量较多集中评分中间。
- 运用简单聚集函数,获取影片info信息
cursor=db.douban.distinct("info")
for document in cursor:
print(document)
分析:
影片类型中出现最多的是“犯罪/惊悚/悬疑”,可以发现观众比较喜欢看的电影类型是犯罪悬疑片,其次较多的是“爱情/喜剧”和“科幻/冒险”。一般犯罪悬疑片给人以紧张感,出现案件一步步进行破案,有时剧情还会不断反转,紧扣观众的视线有让观众看下去的欲望,所以犯罪悬疑片更得观众喜爱。
4.运用简单聚集函数,获取影片评分信息
cursor=db.douban.distinct("rating_score")
for document in cursor:
print(document)
分析:
影片评分集中分布在8.3到9.7之间,说明Top250榜中电影评分最低为8.3分,最高为9.7分。
5.运用简单聚集函数,获取影片短评。将影片短评信息保存在“豆瓣短评.pdf”文件中,用于文件上传下载。
cursor=db.douban.distinct("introduce")
for document in cursor:
print(document)
分析:
每部影片的短评都描述了电影的特征或者电影所获得的成就,例如“风华绝代”、“香港浪漫主义警匪动作片的巅峰之作”。影片短评是概述电影最重要的东西,看到短评大概就知道电影主要描写了什么,或者电影讲了什么故事,电影获得了哪些成就。一部电影的短评是浓缩了电影的精华而形成的,通过短评就可以看出电影的价值所在,
(4)对分析得出的数据进行复制集操作
1.创建复制集中每个节点存放数据的目录、每个节点的日志文件、每个节点启动时所需的配置文件,创建复制集添加节点。
2.将排名前三的影片信息插入到复制集中,查看数据是否同步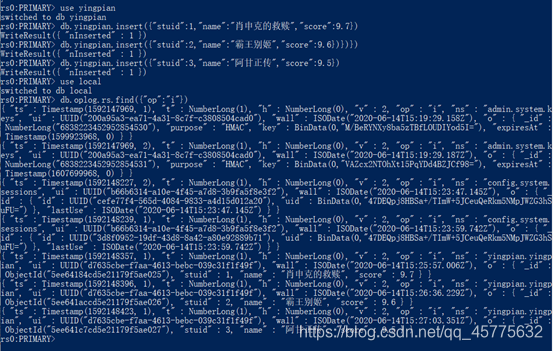
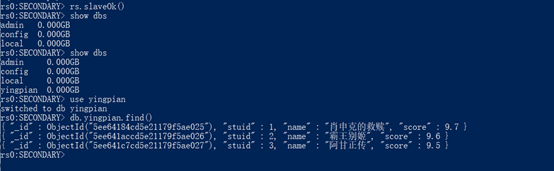
(5)文件上传与下载
将分析保存的“豆瓣短评.pdf”文件信息上传到数据库中。将数据库中的“豆瓣短评.pdf”文件下载到本地。代码为:”文件上传下载豆瓣短评.py”

(6)对数据进行备份
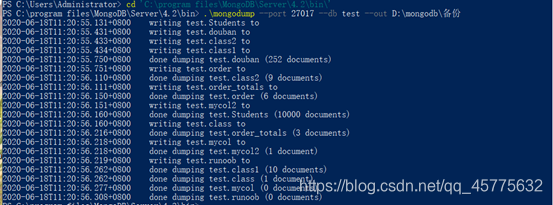
查看数据是否备份成功:
三:信息展示功能实现
(1)网站搭建实现
第一步:新建文件夹“网站搭建成果展示”,将数据放入文件夹中,主要包括html文件、影片图片信息、网站搭建所需的css、fonts、imge、js等文件信息。
第二步:编写html文件
1.Index.html主页面编写内容:
<h1>Welcome to <em>douban</em></h1>
<p>一部电影 一部人生</p>
<p>每一部电影都让我们好像经历了另一种不同的人生,这是一种安全的奇妙的感觉。</p>
- Grid.html页面:主要内容为排名前40的电影信息
例如:
<a href="imge/肖申克的救赎.jpg"
data-lightbox="image-1"><div class="hover-effect">
<div class="hover-content">
<h1>肖申克的 <em>救赎</em></h1>
<p>希望让人自由</p>
</div>
</div></a>
<div class="image">
<img src="imge/肖申克的救赎.jpg" width="70%" height="500">
- single-post.html页面:电影分析结果展示
主要代码展示:
<li><a href="#">> 美国(5)部</a></li>
<li><a href="#">> 日本(2)部</a></li>
<li><a href="#">> 中国(1)部</a></li>
<li><a href="#">> 法国(1)部</a></li>
<li><a href="#">> 意大利(1)部</a></li>
<br>
阿甘正传</p>
<p>阿甘(汤姆·汉克斯 饰)于二战结束后不久出生在美国南方阿拉巴马州一个闭塞的小镇,他先天弱智,智商只有75,然而他的妈妈是一个性格坚强的女性,她常常鼓励阿甘“傻人有傻福”,要他自强不息。 <br>
阿甘像普通孩子一样上学,并且认识了一生的朋友和至爱珍妮(罗宾·莱特·潘 饰),在珍妮和妈妈的爱护下,阿甘凭着上帝赐予的“飞毛腿”开始了一生不停的奔跑。 <br>
阿甘成为橄榄球巨星、越战英雄、乒乓球外交使者、亿万富翁,但是,他始终忘不了珍妮,几次匆匆的相聚和离别,更是加深了阿甘的思念。 <br>
有一天,阿甘收到珍妮的信,他们终于又要见面……<br>
<br>
- About.html页面:关于电影的一些其他信息
主要代码:
<div class="more-about-us">
<div class="container">
<div class="col-md-5 col-md-offset-7">
<div class="content">
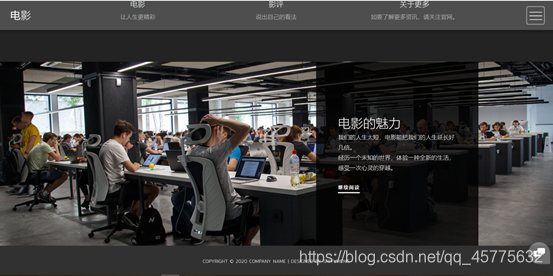
<h2>电影的魅力</h2>
<p>我们的人生太短,电影能把我们的人生延长好几倍。<br>
经历一个未知的世界,体验一种全新的生活,感受一次心灵的穿越。</p>
(2)网站分析结果展示
1.single-post.html页面:电影分析结果展示
进入网站点击右上角按钮,找到“影片分析”选项,点击进入。用户即可看到前十排行榜国家比例、排行榜前三名信息

用户向下滑动,可以看到豆瓣Top250榜单前三电影剧情简介、热门短评以及评分个数统计等信息。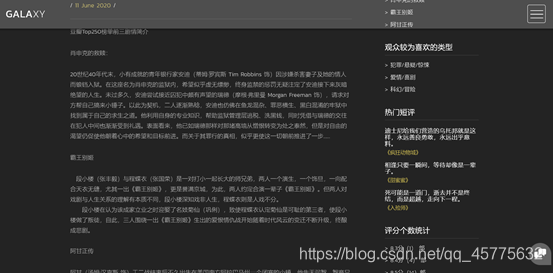
用户对网站若有意见,可以发送邮件,点击网站右下角信息图标,即可出现“Say hello to yourshelf”界面,用户可以通过此界面向网站写邮件。
- Index.html主页面展示
用户打开网址界面呈现: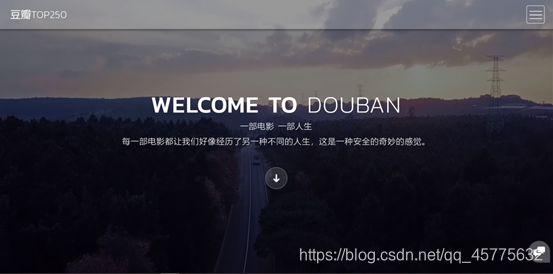
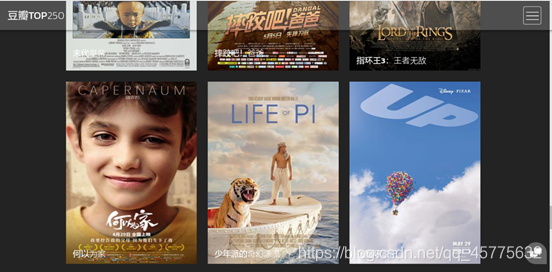
用户向下滑动,查看排名前九的影片信息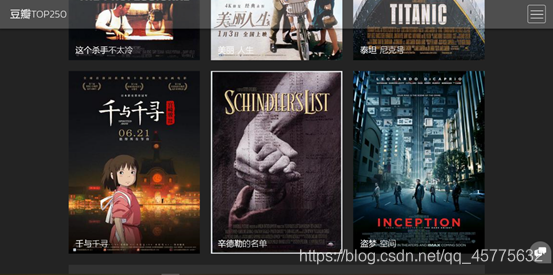
当用户用鼠标触碰到影片时,出现影片短评。例如触碰“千与千寻”,出现影评“最好的宫崎骏,最好的久石让”。
当用户点击影片信息时,弹出影片图片,图片左右有按钮,点击按钮可以左右切换查询图片。
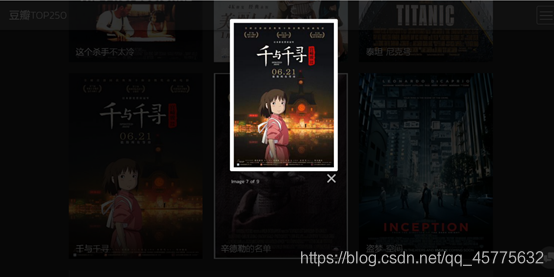
- grid.html页面展示:
此页面通index.html页面相似,不同于index.html页面有九部影片信息,而grid.html页面有40部影片信息,此页面影片信息较为全面。
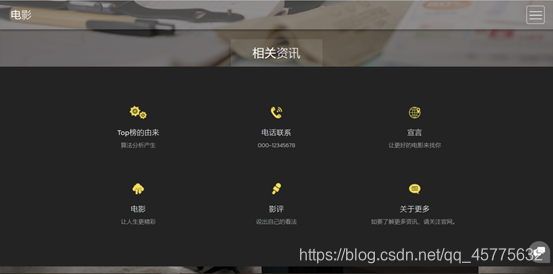
- about.html页面展示
点击页面右上角按钮,找到“关于我们”按钮,点击进入。主页标题为相关咨询,下方分为六个小标题,可让用户查看相关资讯。
用户向下滑动,可以看到大标题“电影的魅力”。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)