Elasticsearch:对搜索结果排序 - Sort
我们知道在默认的情况下,搜索的结果是按照相关性来进行排序的。分数最高的排在前面,而分数低的向后依次排序。在绝大多数的情况下,这种排序是非常有效的,而且也适用我们的很多用例。即便针对分数,我们也可以对搜索的结果进行定制。关于这个分数是如何及算出来的,你可以参考我之前的文章 “Elasticsearch:使用 Elasticsearch 提高网站搜索查询的相关性”。我们也可以使用一下方法来定制我们的
我们知道在默认的情况下,搜索的结果是按照相关性来进行排序的。分数最高的排在前面,而分数低的向后依次排序。在绝大多数的情况下,这种排序是非常有效的,而且也适用我们的很多用例。即便针对分数,我们也可以对搜索的结果进行定制。关于这个分数是如何及算出来的,你可以参考我之前的文章 “Elasticsearch:使用 Elasticsearch 提高网站搜索查询的相关性”。我们也可以使用一下方法来定制我们的分数。你可以阅读如下的文章:
然而,有时,我们并不想按照默认的分数进行排序。比如我们想按照姓氏的顺序来排序,或者按照价格的高低来排序,或者按照距离的远近来进行排序。Elasticsearch 允许你使用 sort 来使你在特定字段上添加一种或多种排序。 每种排序也可以颠倒。 排序是在每个字段级别上定义的,_score 的特殊字段名称按分数排序,_doc 按索引顺序排序。
在今天的文章中,我来详述如何使用 sort 来进行排序。
准备数据
我们先在 Kibana 中使用如下的命令来创建一个叫做 mybooks 的索引:
PUT mybooks
{
"mappings": {
"properties": {
"date": {
"type": "date"
},
"description": {
"type": "text"
},
"offer": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"price": {
"type": "long"
}
}
},
"position": {
"type": "long"
},
"price": {
"type": "long"
},
"publisher": {
"type": "keyword"
},
"quantity": {
"type": "long"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"uuid": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}在上面的索引中,我有意识地设置了整型类,date,geo_point,text,keyword 及 nested 各个类型的数据。接着我们使用如下的命令来写入数据到索引中:
POST _bulk/
{"index":{"_index":"mybooks", "_id":"1"}}
{"uuid":"11111","position":1, "title":"Joe Bates", "description":"Joe Testere nice guy", "date":"2015-10-22","price":[1, 2, 3], "quantity":50, "publisher": "RELX", "offer": [{"name":"book1", "price": 5}], "location":{"lat":"39.718256","lon":"116.367910"}}
{"index":{"_index":"mybooks", "_id":"2"}}
{"uuid":"22222","position":2, "title":"Joe Tester","description":"Joe Testere nice guy", "date":"2015-10-22", "price":[4, 5, 6], "quantity":50, "publisher": "RELX", "offer": [{"name":"book2", "price": 5}], "location":{"lat":"39.718256","lon":"116.367910"}}
{"index":{"_index":"mybooks", "_id":"3"}}
{"uuid":"33333", "position":3, "title":"Bill Baloney","description":"Bill Testere nice guy","date":"2016-06-12","price":[7, 8, 9], "quantity":34, "publisher": "Thomson Reuters", "offer": [{"name":"book3", "price": 10}], "location":{"lat":"40.718256","lon":"117.367910"}}
{"index":{"_index":"mybooks", "_id":"4"}}
{"uuid":"44444", "position":4, "title":"Bill Klingon","description":"Bill is not a nice guy", "date":"2017-09-21","price":[1, 5, 8], "quantity":33, "offer": [{"name":"book4", "price": 20}],"location":{"lat":"41.718256", "lon":"118.367910"}}在上面,我们使用了4个文档数据。数据不必太多,只要能说明问题即可。其中第一个文档和第二个文档的日期是一样的。
使用日期来进行排序
我们对搜索的结果按照日期进行排序:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"date": {
"order": "desc"
}
}
],
"_source": false,
"fields": [
"date"
]
}在上面,我们把搜索的结果按照 date 进行降序排序。我们可以看到如下的结果:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"fields" : {
"date" : [
"2017-09-21T00:00:00.000Z"
]
},
"sort" : [
1505952000000
]
},
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"fields" : {
"date" : [
"2016-06-12T00:00:00.000Z"
]
},
"sort" : [
1465689600000
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"date" : [
"2015-10-22T00:00:00.000Z"
]
},
"sort" : [
1445472000000
]
},
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"date" : [
"2015-10-22T00:00:00.000Z"
]
},
"sort" : [
1445472000000
]
}
]
}
}首先,我们可以看到 _score 的值为 null。当我一旦使用 sort 时,那么原来的 _score 就没有任何的意义了。上面的结果显示它是按照 date 的降序进行返回的。在很多的时候,我们甚至可以对多个字段来进行排序,比如:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match": {
"title": "joe"
}
},
"sort": [
{
"date": {
"order": "desc"
}
},
{
"title.keyword": {
"order": "desc"
}
}
],
"_source": false,
"fields": [
"date",
"title"
]
}在上面,我们搜索 title 里含有 joe 的文档,并按照 date 降序排列。如果两个 date 的时间是一致的,那么再按照 title.keyword 来进行降序排序。请注意我们必须使用 title.keyword 而不是 title,这是因为我们不可以针对 text 字段来进行排序的。上面命令的结果为:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"date" : [
"2015-10-22T00:00:00.000Z"
],
"title" : [
"Joe Tester"
]
},
"sort" : [
1445472000000,
"Joe Tester"
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"date" : [
"2015-10-22T00:00:00.000Z"
],
"title" : [
"Joe Bates"
]
},
"sort" : [
1445472000000,
"Joe Bates"
]
}
]
}
}如果我们把 title.keyword 按照升序排序的话,就是这样的命令:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match": {
"title": "joe"
}
},
"sort": [
{
"date": {
"order": "desc"
}
},
{
"title.keyword": {
"order": "asc"
}
}
],
"_source": false,
"fields": [
"date",
"title"
]
}注意:_doc 除了是最有效的排序顺序之外没有真正的用例。 因此,如果你不关心文档返回的顺序,那么你应该按 _doc 排序。 这在 scrolling 时特别有用。
Sort mode 选项
Elasticsearch 支持按数组或多值字段排序。 mode 选项控制选择哪个数组值来对其所属的文档进行排序。 mode 选项可以具有以下值:
| min | 选择最低值。 |
| max | 选择最高值。 |
| sum | 使用所有值的总和作为排序值。 仅适用于基于数字的数组字段。 |
| avg | 使用所有值的平均值作为排序值。 仅适用于基于数字的数组字段。 |
| median | 使用所有值的中位数作为排序值。 仅适用于基于数字的数组字段。 |
升序排序中的默认排序模式是 min — 选取最小值。 默认的降序排序模式是max — 取最高值。
针对我们的例子,我们有一个字段 price。它是一个多值的字段。我们现在来对它进行排序,比如:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc",
"mode": "avg"
}
}
],
"_source": false,
"fields": [
"price"
]
}在上面,我们针对 price 进行平均值排序:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"fields" : {
"price" : [
7,
8,
9
]
},
"sort" : [
8
]
},
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"price" : [
4,
5,
6
]
},
"sort" : [
5
]
},
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"fields" : {
"price" : [
1,
5,
8
]
},
"sort" : [
5
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"price" : [
1,
2,
3
]
},
"sort" : [
2
]
}
]
}
}如上所示,我们在 sort 字段里,我们可以看到 price 的平均值。搜索的结果是按照平均值降序进行排列的。
对数字字段进行排序
对于数字字段,也可以使用 numeric_type 选项将值从一种类型转换为另一种类型。 此选项接受以下值:["double", "long", "date", "date_nanos"] 并可用于跨多个数据流或索引的搜索,其中排序字段映射不同。
例如考虑这两个索引:
PUT /index_double
{
"mappings": {
"properties": {
"field": { "type": "double" }
}
}
}
PUT /index_long
{
"mappings": {
"properties": {
"field": { "type": "long" }
}
}
}由于 field 在第一个索引中被映射为双精度(double),在第二个索引中被映射为长型数(long),因此默认情况下无法使用此字段对查询两个索引的请求进行排序。 但是,你可以使用 numeric_type 选项将类型强制为一种或另一种,以便为所有索引强制使用特定类型:
POST /index_long,index_double/_search
{
"sort" : [
{
"field" : {
"numeric_type" : "double"
}
}
]
}在上面的示例中,index_long 索引的值被强制转换为双精度,以便与 index_double 索引生成的值兼容。 也可以将浮点字段转换为 long 但请注意,在这种情况下,浮点被替换为小于或等于参数的最大值(如果值为负,则大于或等于)并且等于 为一个数学整数。
此选项还可用于将使用毫秒分辨率的日期字段转换为具有纳秒分辨率的 date_nanos 字段。 例如考虑这两个索引:
PUT /index_double
{
"mappings": {
"properties": {
"field": { "type": "date" }
}
}
}
PUT /index_long
{
"mappings": {
"properties": {
"field": { "type": "date_nanos" }
}
}
}这些索引中的值以不同的分辨率存储,因此对这些字段进行排序将始终将 date 排序在 date_nanos 之前(升序)。 使用 numeric_type 类型选项,可以为排序设置单个分辨率,设置为 date 会将 date_nanos 转换为毫秒分辨率,而 date_nanos 会将 date 字段中的值转换为纳秒分辨率:
POST /index_long,index_double/_search
{
"sort" : [
{
"field" : {
"numeric_type" : "date_nanos"
}
}
]
}警告:为避免溢出,转换为 date_nanos 不能应用于 1970 年之前和 2262 年之后的日期,因为纳秒表示为 long。
在嵌套对象中排序
Elasticsearch 还支持按一个或多个嵌套(nested)对象内的字段进行排序。 嵌套字段支持的排序具有 nested 排序选项,具有以下属性:
| path | 定义要排序的嵌套对象。 实际的排序字段必须是此嵌套对象内的直接字段。 按嵌套字段排序时,此字段为必填项。 |
| filter | 嵌套路径内的内部对象应匹配的过滤器,以便通过排序考虑其字段值。 常见的情况是在嵌套过滤器或查询中重复查询/过滤器。 默认情况下,没有 filter 处于活动状态。 |
| max_children | 选择排序值时要考虑的每个根文档的最大子项数。 默认为无限制。 |
| nested | 与顶级嵌套相同,但适用于当前嵌套对象中的另一个嵌套路径。 |
注意:如果在没有嵌套上下文的排序中定义了嵌套字段,Elasticsearch 将抛出错误。
嵌套排序示例
在下面的示例中,offer 是一个 nested 类型的字段。 需要指定嵌套 path; 否则,Elasticsearch 不知道需要捕获哪些嵌套级别的排序值。
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"offer.price": {
"mode": "avg",
"order": "desc",
"nested": {
"path": "offer",
"filter": {
"term": {
"offer.name": "book3"
}
}
}
}
}
]
}在上面,我们是以 offer.price 来进行降序排列。我们针对 offer.name 为 book3 得到排序的优先级。上面的排序结果为:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"_source" : {
"uuid" : "33333",
"position" : 3,
"title" : "Bill Baloney",
"description" : "Bill Testere nice guy",
"date" : "2016-06-12",
"price" : [
7,
8,
9
],
"quantity" : 34,
"publisher" : "Thomson Reuters",
"offer" : [
{
"name" : "book3",
"price" : 10
}
],
"location" : {
"lat" : "40.718256",
"lon" : "117.367910"
}
},
"sort" : [
10
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"_source" : {
"uuid" : "11111",
"position" : 1,
"title" : "Joe Bates",
"description" : "Joe Testere nice guy",
"date" : "2015-10-22",
"price" : [
1,
2,
3
],
"quantity" : 50,
"publisher" : "RELX",
"offer" : [
{
"name" : "book1",
"price" : 5
}
],
"location" : {
"lat" : "39.718256",
"lon" : "116.367910"
}
},
"sort" : [
-9223372036854775808
]
},
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"_source" : {
"uuid" : "22222",
"position" : 2,
"title" : "Joe Tester",
"description" : "Joe Testere nice guy",
"date" : "2015-10-22",
"price" : [
4,
5,
6
],
"quantity" : 50,
"publisher" : "RELX",
"offer" : [
{
"name" : "book2",
"price" : 5
}
],
"location" : {
"lat" : "39.718256",
"lon" : "116.367910"
}
},
"sort" : [
-9223372036854775808
]
},
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"_source" : {
"uuid" : "44444",
"position" : 4,
"title" : "Bill Klingon",
"description" : "Bill is not a nice guy",
"date" : "2017-09-21",
"price" : [
1,
5,
8
],
"quantity" : 33,
"offer" : [
{
"name" : "book4",
"price" : 20
}
],
"location" : {
"lat" : "41.718256",
"lon" : "118.367910"
}
},
"sort" : [
-9223372036854775808
]
}
]
}
}从上面的结果可以看出来,offer.name 为 book3 的文档排名最高。
在下面的示例中,parent 字段和 child 字段属于 nested 类型。 每一层都需要指定 nested.path; 否则,Elasticsearch 不知道需要捕获哪些嵌套级别的排序值。
POST /_search
{
"query": {
"nested": {
"path": "parent",
"query": {
"bool": {
"must": {"range": {"parent.age": {"gte": 21}}},
"filter": {
"nested": {
"path": "parent.child",
"query": {"match": {"parent.child.name": "matt"}}
}
}
}
}
}
},
"sort" : [
{
"parent.child.age" : {
"mode" : "min",
"order" : "asc",
"nested": {
"path": "parent",
"filter": {
"range": {"parent.age": {"gte": 21}}
},
"nested": {
"path": "parent.child",
"filter": {
"match": {"parent.child.name": "matt"}
}
}
}
}
}
]
}在按脚本排序和按地理距离排序时也支持嵌套排序。
缺失值
missing 参数指定应如何处理缺少排序字段的文档:缺失值可以设置为 _last、_first 或自定义值(将用于缺少文档作为排序值)。 默认值为 _last。
例如:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"publisher": {
"order": "desc",
"missing": "_first"
}
}
],
"_source": false,
"fields": [
"publisher"
]
}在上,我们在 sort 时,定义如果缺失 publisher 这个字段,那么就排到前面去。上面的搜索结果是:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"sort" : [
null
]
},
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"fields" : {
"publisher" : [
"Thomson Reuters"
]
},
"sort" : [
"Thomson Reuters"
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"publisher" : [
"RELX"
]
},
"sort" : [
"RELX"
]
},
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"publisher" : [
"RELX"
]
},
"sort" : [
"RELX"
]
}
]
}
}我们可以看到 _id 为 4 的文档排在第一位,而其它含有 publisher 的文档是按照降序进行排列的。
注意:如果嵌套的内部对象与nested.filter 不匹配,则使用缺失值。
忽略未映射的字段
默认情况下,如果没有与字段关联的映射,则搜索请求将失败。 unmapped_type 选项允许你忽略没有映射的字段并且不按它们排序。 此参数的值用于确定要发出的排序值。 这是如何使用它的示例。我们来创建一个如下另外一个索引:
PUT mybooks1
{
"mappings": {
"properties": {
"date": {
"type": "date"
},
"description": {
"type": "text"
},
"offer": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"price": {
"type": "long"
}
}
},
"position": {
"type": "long"
},
"publisher": {
"type": "keyword"
},
"quantity": {
"type": "long"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"uuid": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}在上面,我们创建了一个叫做 mybooks1 的索引。请注意它和之前的 mybooks 索引的区别就是它没有了之前的 price 字段。其它的字段都一样。我们使用如下命令来创建一个文档:
POST _bulk/
{"index":{"_index":"mybooks", "_id":"1"}}
{"uuid":"99999","position":1, "title":"Joe Bates", "description":"Joe Testere nice guy", "date":"2015-10-22", "quantity":50, "publisher": "RELX", "offer": [{"name":"book1", "price": 5}], "location":{"lat":"39.718256","lon":"116.367910"}}我们使用如下的搜索:
GET mybooks*/_search?filter_path=**.hits
{
"query": {
"match": {
"title": "joe"
}
},
"sort": [
{
"price": {
"order": "desc",
"mode": "avg"
}
}
]
}上面的命令返回的结果为:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"_source" : {
"uuid" : "22222",
"position" : 2,
"title" : "Joe Tester",
"description" : "Joe Testere nice guy",
"date" : "2015-10-22",
"price" : [
4,
5,
6
],
"quantity" : 50,
"publisher" : "RELX",
"offer" : [
{
"name" : "book2",
"price" : 5
}
],
"location" : {
"lat" : "39.718256",
"lon" : "116.367910"
}
},
"sort" : [
5
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"_source" : {
"uuid" : "99999",
"position" : 1,
"title" : "Joe Bates",
"description" : "Joe Testere nice guy",
"date" : "2015-10-22",
"quantity" : 50,
"publisher" : "RELX",
"offer" : [
{
"name" : "book1",
"price" : 5
}
],
"location" : {
"lat" : "39.718256",
"lon" : "116.367910"
}
},
"sort" : [
-9223372036854775808
]
}
]
}
}如果查询的索引文档中没有价格 price 字段,则 Elasticsearch 将这样处理它:就好像存在 price 为 long 类型的映射一样。排序的结果中不含有字段 price 的值。
地理距离排序
允许按 _geo_distance 排序。 这是一个示例,在我们的 mybooks 索引中 location 是一个 geo_point 的类型。我们可以做如下的查询:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 39.718256,
"lon": 116.367910
},
"order": "asc",
"unit": "km",
"mode": "min",
"distance_type": "arc",
"ignore_unmapped": true
}
}
],
"_source": false,
"fields": [
"location"
]
}在上面,我们以经纬度地点 [116.367910, 39.718256] 为中心,其它文档距离这个地点按照升序进行排列。上面命令搜索的结果为:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"location" : [
{
"coordinates" : [
116.36791,
39.718256
],
"type" : "Point"
}
]
},
"sort" : [
0.0
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"location" : [
{
"coordinates" : [
116.36791,
39.718256
],
"type" : "Point"
}
]
},
"sort" : [
0.0
]
},
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"fields" : {
"location" : [
{
"coordinates" : [
117.36791,
40.718256
],
"type" : "Point"
}
]
},
"sort" : [
139.9034456345085
]
},
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"fields" : {
"location" : [
{
"coordinates" : [
118.36791,
41.718256
],
"type" : "Point"
}
]
},
"sort" : [
279.0300719062577
]
}
]
}
}我们可以看到有两个文档的距离是 0,而另外的两个文档的距离是 139.9034456345085 及 279.0300719062577 公里。
上面的参数描述如下:
| distance_type | 如何计算距离。 可以是圆弧(默认),也可以是平面(速度更快,但在长距离和靠近极点时不准确)。 |
| mode | 如果一个字段有多个地理点,该怎么办。 默认情况下,升序排序时考虑最短距离,降序排序时考虑最长距离。 支持的值为最小值、最大值、中值和平均值。 |
| unit | 计算排序值时使用的单位。 默认值为 m(米)。 |
| ignore_unmapped | 指示是否应将未映射的字段视为缺失值。 将其设置为 true 等效于在字段排序中指定 unmapped_type。 默认值为 false(未映射的字段会导致搜索失败)。 |
注意:地理距离排序不支持可配置的缺失值:当文档没有用于距离计算的字段的值时,距离将始终被视为等于 Infinity。
上面的搜索也支持如下的格式的坐标表示:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": [
116.36791,
39.718256
],
"order": "asc",
"unit": "km",
"mode": "min",
"distance_type": "arc",
"ignore_unmapped": true
}
}
],
"_source": false,
"fields": [
"location"
]
}更多关于地理位置坐标的描述,可以阅读另外一篇文章 “Elasticsearch:理解 Elastic Maps 中的 geohash 及其聚合”。
我们也可以使用 WKT 字符串:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": "POINT(116.36791 39.718256)",
"order": "asc",
"unit": "km",
"mode": "min",
"distance_type": "arc",
"ignore_unmapped": true
}
}
],
"_source": false,
"fields": [
"location"
]
}我们甚至可以使用 Geohash 代码。请参考我之前的文章 “Elasticsearch:理解 Elastic Maps 中的 geohash 及其聚合”。在该文章中,找那个把经纬度转为 geohash 的网站。经过转换 (116.36791 39.718256) 可以转换为 wx4cbn2x8gd:
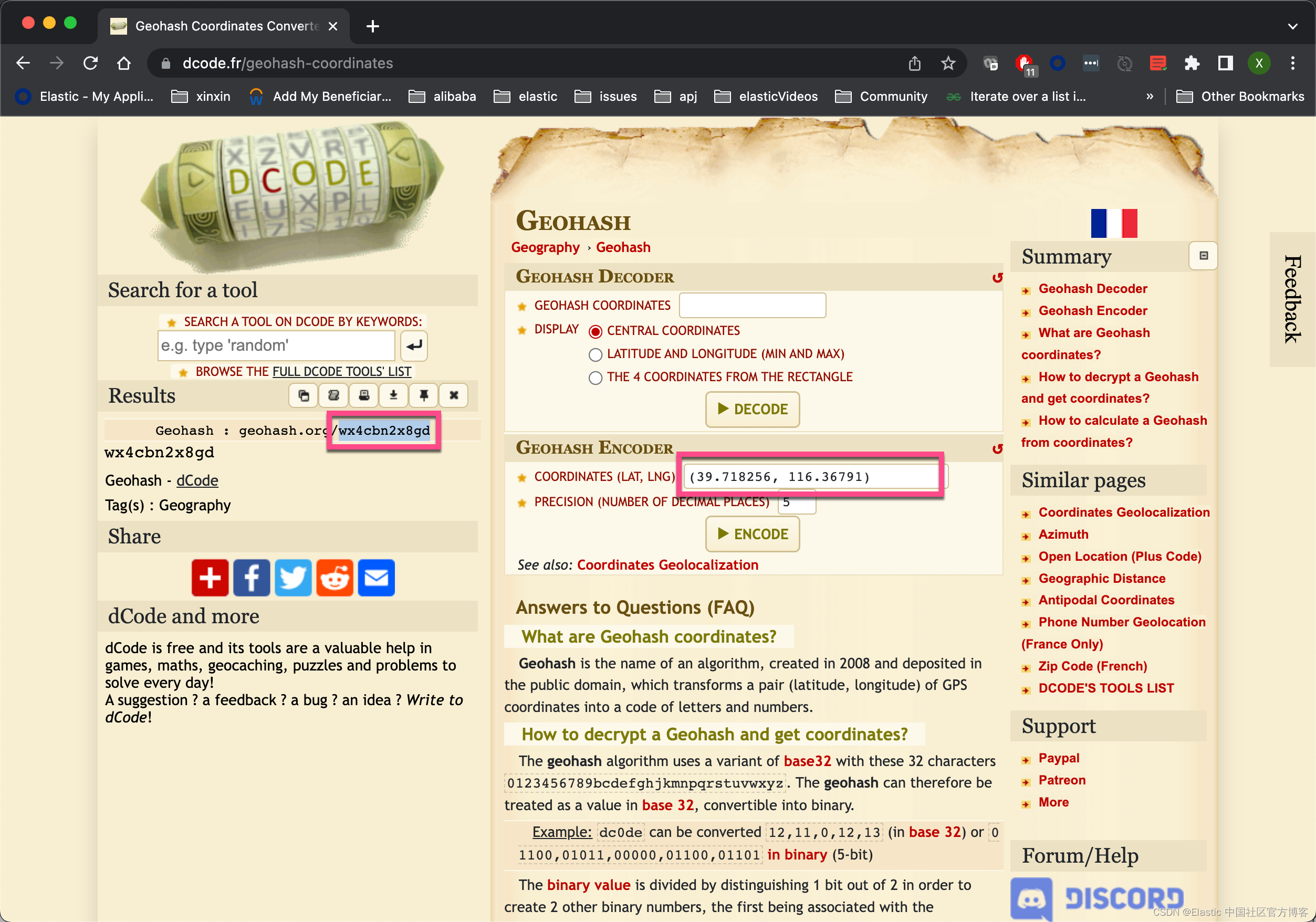
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": "wx4cbn2x8gd",
"order": "asc",
"unit": "km",
"mode": "min",
"distance_type": "arc",
"ignore_unmapped": true
}
}
],
"_source": false,
"fields": [
"location"
]
}显然这个取决于 geohash 的精度。在上面的搜索中,在前两个的搜索结果中,sort 里的值不再是 0 了。说明它还是有一点误差的:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"location" : [
{
"coordinates" : [
116.36791,
39.718256
],
"type" : "Point"
}
]
},
"sort" : [
7.30239509326306E-5
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"location" : [
{
"coordinates" : [
116.36791,
39.718256
],
"type" : "Point"
}
]
},
"sort" : [
7.30239509326306E-5
]
},多个参考点
多个地理点可以作为包含任何 geo_point 格式的数组传递,例如
GET /_search
{
"sort": [
{
"_geo_distance": {
"pin.location": [ [ -70, 40 ], [ -71, 42 ] ],
"order": "asc",
"unit": "km"
}
}
],
"query": {
"term": { "user": "kimchy" }
}
}文档的最终距离将是文档中包含的所有点到排序请求中给定的所有点的最小/最大/平均(通过模式定义)距离。
基于脚本的排序
允许根据自定义脚本进行排序,这是一个示例。
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_script": {
"type": "number",
"order": "desc",
"script": {
"lang": "painless",
"source": """
doc['quantity'].value * params.factor
""",
"params": {
"factor": 2
}
}
}
}
],
"_source": false,
"fields": [
"quantity"
]
}在上面,我们想知道 quantity 乘以 2 的结果来进行排序:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"quantity" : [
50
]
},
"sort" : [
100.0
]
},
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"quantity" : [
50
]
},
"sort" : [
100.0
]
},
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"fields" : {
"quantity" : [
34
]
},
"sort" : [
68.0
]
},
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"fields" : {
"quantity" : [
33
]
},
"sort" : [
66.0
]
}
]
}
}我们可以使用如下的查询来查看到底哪本书压货的钱最多。在下面,我们取没本书的平均价格:
GET mybooks/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_script": {
"type": "number",
"order": "desc",
"script": {
"lang": "painless",
"source": """
double total = 0.0;
for (int i = 0; i < doc['price'].length; ++i) {
total += (double)doc['price'][i];
}
total = total/3;
return total*doc['quantity'].value
"""
}
}
}
],
"_source": false,
"fields": [
"quantity"
]
}上面的查询返回的结果为:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "3",
"_score" : null,
"fields" : {
"quantity" : [
34
]
},
"sort" : [
272.0
]
},
{
"_index" : "mybooks",
"_id" : "2",
"_score" : null,
"fields" : {
"quantity" : [
50
]
},
"sort" : [
250.0
]
},
{
"_index" : "mybooks",
"_id" : "4",
"_score" : null,
"fields" : {
"quantity" : [
33
]
},
"sort" : [
154.0
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : null,
"fields" : {
"quantity" : [
50
]
},
"sort" : [
100.0
]
}
]
}
}从上面,我们可以看出来 _id 为 3 的书压货的钱是最多的。
跟踪分数
对字段进行排序时,不计算分数。 通过将 track_scores 设置为 true,仍然会计算和跟踪分数。
GET mybooks/_search?filter_path=**.hits
{
"track_scores": true,
"query": {
"match": {
"title": "joe"
}
},
"sort": [
{
"date": {
"order": "desc"
},
"title.keyword": {
"order": "desc"
},
"quantity": {
"order": "desc"
}
}
]
}上面的命令返回的结果为:
{
"hits" : {
"hits" : [
{
"_index" : "mybooks",
"_id" : "2",
"_score" : 0.6931471,
"_source" : {
"uuid" : "22222",
"position" : 2,
"title" : "Joe Tester",
"description" : "Joe Testere nice guy",
"date" : "2015-10-22",
"price" : [
4,
5,
6
],
"quantity" : 50,
"publisher" : "RELX",
"offer" : [
{
"name" : "book2",
"price" : 5
}
],
"location" : {
"lat" : "39.718256",
"lon" : "116.367910"
}
},
"sort" : [
1445472000000,
"Joe Tester",
50
]
},
{
"_index" : "mybooks",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"uuid" : "11111",
"position" : 1,
"title" : "Joe Bates",
"description" : "Joe Testere nice guy",
"date" : "2015-10-22",
"price" : [
1,
2,
3
],
"quantity" : 50,
"publisher" : "RELX",
"offer" : [
{
"name" : "book1",
"price" : 5
}
],
"location" : {
"lat" : "39.718256",
"lon" : "116.367910"
}
},
"sort" : [
1445472000000,
"Joe Bates",
50
]
}
]
}
}内存考虑
排序时,相关的排序字段值被加载到内存中。 这意味着每个分片应该有足够的内存来容纳它们。 对于基于字符串的类型,排序的字段不应被分析/标记化。 对于数字类型,如果可能,建议将类型显式设置为更窄的类型(如 short、integer 和 float)。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 8
8 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)