Clickhouse实时消费Kafka
Clickhouse一、背景介绍二、操作流程三、一些概念四、一些问题一、背景介绍这么做的好处有:二、操作流程三、一些概念四、一些问题1、StorageKafka (queue): Can’t get assignment. It can be caused by some issue with consumer group (not enough partitions?). Will keep t
一、背景介绍

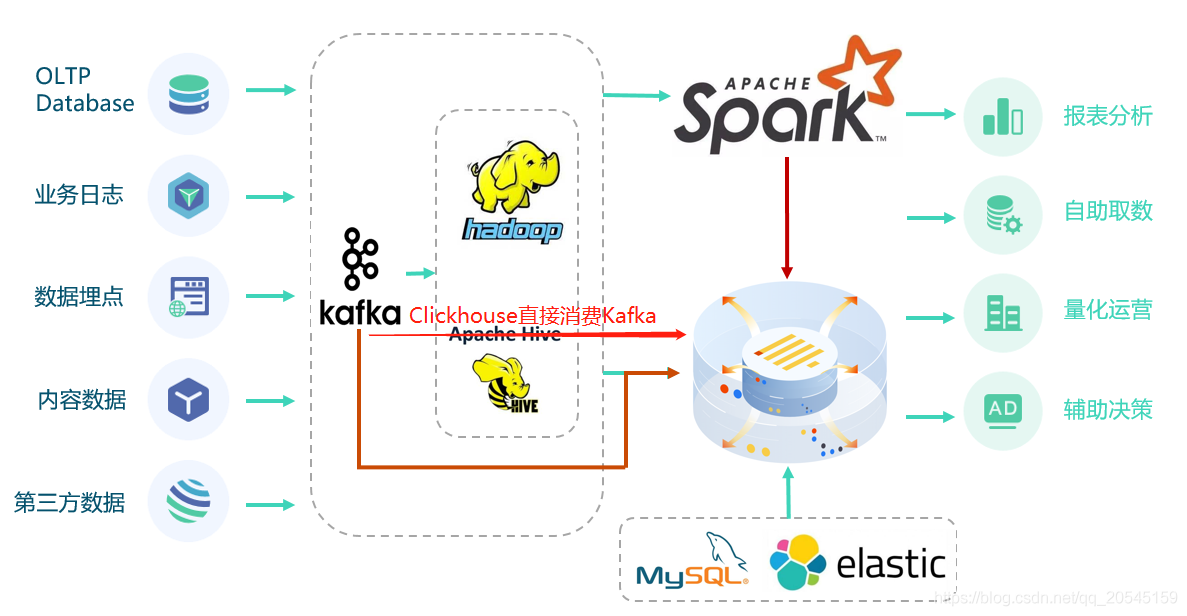
本文主要介绍通过Clickhouse自带的Kafka集成引擎,及时消费同步Kafka数据,减少数据同步链路,加快数据同步流程(如上图所示,理论上可以消除离线层)。同时利用Clickhouse快速聚合能力,加速上层数据查询分析能力。
Kafka作为消息引擎在大数据领域有着重要的作用,它通常用来接收下游产生的各种数据;ClickHouse是一个开源的用于联机分析(OLAP)的列式数据库管理系统,在大数据领域扮演越来越重要的作用,近几年在国内各大厂商应用得比较广泛。(对Clickhouse的详细介绍可参考我另外篇文章ClickHouse技术分享)两者强强联合,结合kafka的数据吞吐能力和clickhouse的数据分析能力,加速数据实时分析。当然,在我们真实环境中受到Clickhouse大量小文件合并的影响,数据可能在几秒后才会合并写入完成,但在大数据OLAP引擎中,这个延时也挺低的了,对实际应用场景影响不大。
二、操作流程

在开始操作前我们来看下整个操作流程(这里假设你已经有了Kafka消息引擎):
1、在Clickhouse中创建Kafka外表引擎,如何创建以及参数如何设置下面会介绍,这里可以理解为消费Kafka的一个客户端
2、在Clickhouse中创建存储数据的表,用来存放从Kafka消费过来的数据,可以是本地表或者是分布式表
3、在Clickhouse中创建物化视图,物化视图相当于从Kafka和持久化表中间创建一座桥梁,不断的从Kafka消费数据并写入存储表
关于Clickhouse中的物化视图,它是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路,所以用得好的话,它可以避免对基础表的频繁查询并复用结果,从而显著提升查询的性能,详情请参考ClickHouse性能优化?试试物化视图
接下来,我们详细讲一下这3个步骤如何创建:
1、在Clickhouse中创建Kafka外表引擎
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol',]
[kafka_schema = '',]
[kafka_num_consumers = N,]
[kafka_max_block_size = 0,]
[kafka_skip_broken_messages = N,]
[kafka_commit_every_batch = 0,]
[kafka_thread_per_consumer = 0]
必要参数:
- kafka_broker_list — kafka brokers服务列表,多个用逗号隔开 (例如, localhost:9092).
- kafka_topic_list — kafka的topic名称
- kafka_group_name —消费者group的名称,如果你不希望集群中的消息被重复消费,不要随意改动group的名字
- kafka_format — 消息格式,使用相同的格式作为SQL格式化方法, 例如
JSONEachRow。 更多的信息,可以这里看Clickhouse支持的格式
可选参数:
- kafka_row_delimiter — 消息结束的分隔字符
- kafka_schema — 对于
kafka_format需要scheme定义得时候,其scheme由该参数定义 - kafka_num_consumers — 每个表的消费者数量,默认是1。如果一个消费者吞吐量不够,可以通过增加该参数增加吞吐量,但是消费者的总数不应该超过topic分区的总数,因为每个分区只可以指定一个消费者
- kafka_max_block_size — 最大批处理大小 (默认: max_block_size)
- kafka_skip_broken_messages — 每个block能够容忍Kafka消息异常得数目,默认是0。如果kafka_skip_broken_messages = N,该引擎就会忽略N条异常的消息(一条消息就是一行数据)
- kafka_commit_every_batch — 提交每个消费者和批处理,而不是单个提交后再写整个block(默认是0)
- kafka_thread_per_consumer — 为每个消费者者提供独立的线程(默认是0)。当启用后,每个消费者独立并行地刷新数据(否则,来自多个消费者的行将被压缩以形成一个块)
我们创建一张测试表:
CREATE TABLE engines.user_data_kafka
(
`name` String COMMENT '序列号ID',
`age` Int16 COMMENT '机型',
`create_date` DateTime COMMENT '创建时间'
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'ip:port,ip:port',
kafka_topic_list = 'topic_name',
kafka_group_name = 'group_name',
kafka_format = 'JSONEachRow',
kafka_max_block_size = 1048576,
kafka_num_consumers = 1
2、在Clickhouse中创建存储数据的表
CREATE TABLE engines.user_data_storage
(
`name` String COMMENT '序列号ID',
`age` Int16 COMMENT '机型',
`create_date` DateTime COMMENT '创建时间'
)
ENGINE = MergeTree ##这里可以是本地表或者是分布式表
ORDER BY create_date
SETTINGS index_granularity = 8192
3、在Clickhouse中创建物化视图
CREATE MATERIALIZED VIEW engines.user_data_view TO engines.user_data_storage
AS select * from engines.user_data_kafka
完成没问题后你如果在Kafka里有实时的消息,你就可以在日志里看到以下日志: StorageKafka (user_data_kafka): Polled batch of 550 messages. Offsets position:

当然,这里的sql你也可以加一些条件,比如你想过滤掉一些脏数据,过滤掉创建时间超出未来1个月的数据,你可以这么写:
CREATE MATERIALIZED VIEW engines.user_data_view TO engines.user_data_storage
AS select * from engines.user_data_kafka where create_date < addDays(today(), 30)
如果需要停止数据同步,你可以删除视图
drop table engines.user_data_view,也可以把该视图卸载detach table engines.user_data_view,卸载后,如果想要再次恢复,可以使用命令attach engines.user_data_view把该视图重新装载
三、一些问题
1、Too many partitions for single INSERT block (more than 100).
单次写入分区太多,默认是100,通过在users.xml修改max_partitions_per_insert_block参数解决,不过不建议这个参数调整得太大,短时间产生得文件太多影响服务得稳定性
<default>
<!-- Maximum memory usage for processing single query, in bytes. -->
<max_memory_usage>30000000000</max_memory_usage>
<max_memory_usage_for_user>30000000000</max_memory_usage_for_user>
<max_partitions_per_insert_block>2000</max_partitions_per_insert_block>
</default>
2、修改kafka的auto_offset_reset参数配置从最新的消息开始消费
<kafka>
<auto_offset_reset>latest</auto_offset_reset>
</kafka>
这其实是消费客户端的一个配置参数,默认是earliest,也就是从最早的数据开始消费,如果线上kafka存储的消息比较久的话建议改成latest,不然创建完物化视图后可能会产生大量的IO告警,别问我为什么,你懂的😭
四、其他说明
实际上,在上述流程中,一个Kafka的数据管道可以对应多个物化视图,将Kafka的消息写入到不同的表中,起到数据分流的作用,如下图所示:

当然,Clickhouse集成的外部表引擎不止是Kafka,它能支持的种类还是挺多的,像Mysql、JDBC、HDFS、RabbitMQ、PostgreSQL等,详细可参考官网;同时它还提供了集成的外部像Mysql数据库引擎,方便你在各种系统做数据迁移同步等操作,与调度任务如DolphinScheduler结合起来用的话你可以配置各种定时调度任务,不管是做离线的还是实时的它都能提供较好的支持。
关于Mysql与Clickhouse实时同步,Clickhouse提供了MaterializedMySQL的支持(目前仍是实验性的阶段),同阿里巴巴的canal一样,通过读取mysql的binlog来实现数据实时同步,在实际测试中发现它对于有大量的update的业务并不友好,Clickhouse的整体性能会被拉跨。这其实是已经预感得到了,但这里并不是说这种方式有什么问题,只能说Clickhouse这种存储结构并不适合这种业务场景,希望未来有其他解决方案。

参考文章:
Clickhouse官网 https://clickhouse.tech/docs/en/engines/table-engines/integrations/kafka/
https://zhuanlan.zhihu.com/p/362809994

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)