
Elasticsearch之中文分词器
讲解中文分词器IK的下载安装以及使用步骤,让我们的开发流程更加流畅、
📢📢📢📣📣📣
哈喽!大家好,我是【一心同学】,一位上进心十足的【Java领域博主】!😜😜😜
✨【一心同学】的写作风格:喜欢用【通俗易懂】的文笔去讲解每一个知识点,而不喜欢用【高大上】的官方陈述。
✨【一心同学】博客的领域是【面向后端技术】的学习,未来会持续更新更多的【后端技术】以及【学习心得】。
✨如果有对【后端技术】感兴趣的【小可爱】,欢迎关注【一心同学】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
目录
一、问题引入
我们在使用elasticsearch官方默认的分词插件时会发现,其对中文的分词效果不佳,我们对中文分词时会遇到很尴尬的问题——中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组。
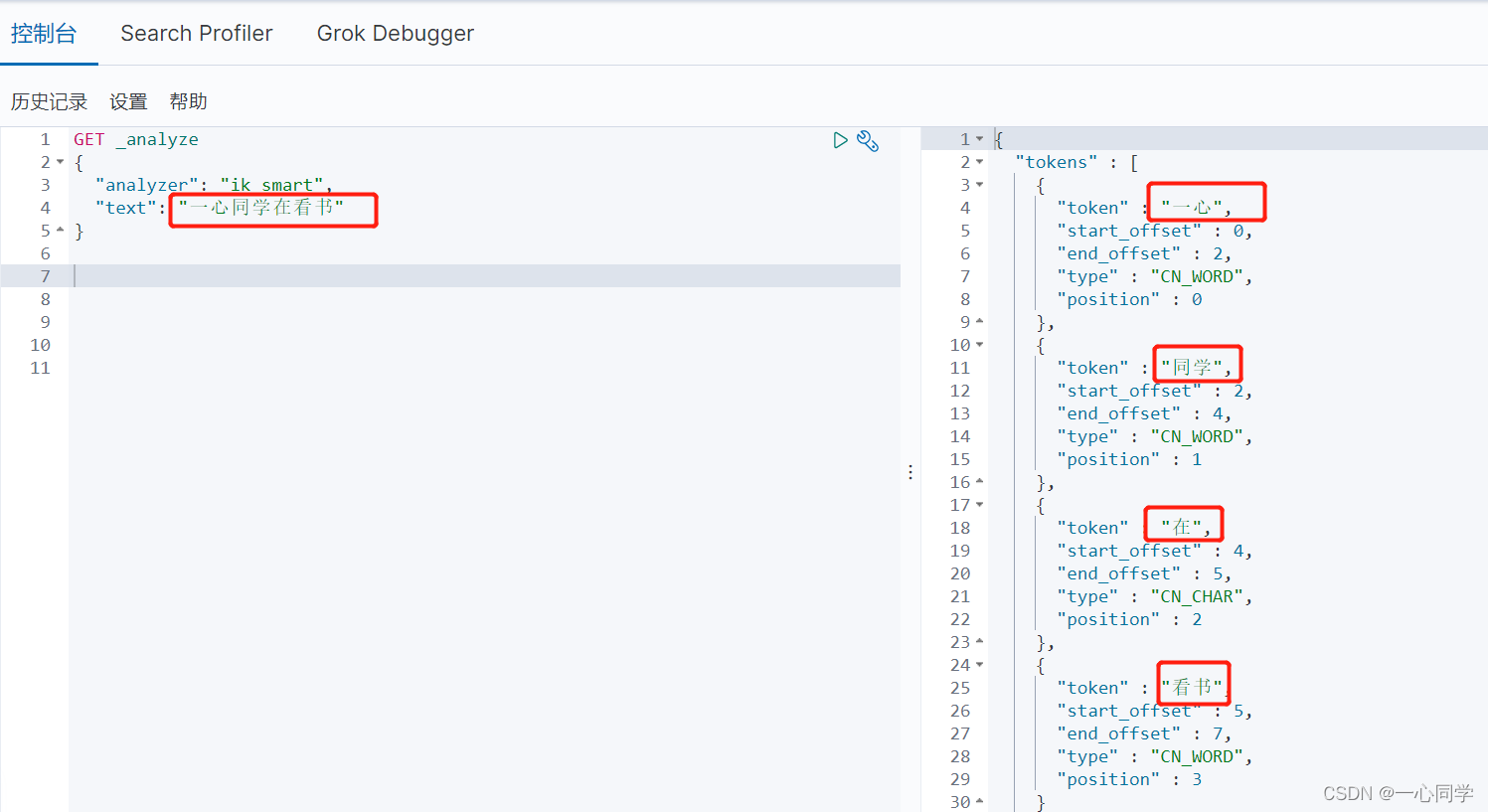
例如我们对“一心同学在看书”这句话进行分词,那么其会被分为:“一”,“心”,“同”,“学”,“在”,“看”,“书”,然而这并不是我们想要的,所以我们需要安装中文分词器ik来解决这个问题。
二、集成IK分词器
2.1 下载
注意:选择的版本要与ElasticSearch版本对应。
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2.2 安装
(1)进入 elasticsearch的plugins目录中,创建一个ik文件夹。
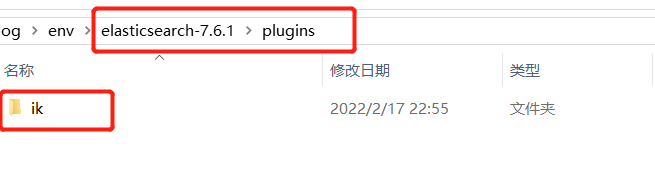
(2)将我们刚才下载的文件解压到ik文件夹里面 。

(3)重启ES即可
2.3 使用IK分词器
🌵 介绍
IK提供了两个分词算法:
ik_smart:最少切分。
ik_max_word:最细粒度划分。
🔥 使用ik_smart(最少切分)
我们这里使用kibana进行测试。
输入:
GET _analyze
{
"analyzer": "ik_smart",
"text": "一心同学在看书"
}结果:
🔥 使用ik_max_word(最细粒度划分)
输入:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "一心同学在看书"
}结果:

🚀分析:可以发现使用ik_max_word算法进行分词会比ik_smart算法分得更细,因为ik_max_word是以穷尽词库的可能来进行分词的。
三、自定义分词器
3.1 问题引入
我们在使用IK分词器时会发现其实有时候分词的效果也并不是我们所期待的,例如我们输入“一心同学在看书”,但是分词器会把“一心同学”进行拆开,分为“一心”和“同学”,但我们希望的是“一心同学”可以不被拆开。

3.2 解决方案
🚀 对于以上的问题,我们只需要将自己要保留的词,加到我们的分词器的字典中即可。
(1)进入elasticsearch目录/plugins/ik/config中,创建我们自己的字典文件yixin.dic,并添加内容:

(2)扩展字典
进入我们的elasticsearch目录 :/plugins/ik/config,打开IKAnalyzer.cfg.xml文件,进行如下配置:

(3)重启ElasticSearch,再次使用kibana测试

可以发现,现在我们的词汇“一心同学”就不会被拆开了,达到我们想要的效果了!也就是说如果我们需要自己配置分词就在自定义的dic文件进行配置即可。
小结
以上就是【一心同学】讲解的关于【IK分词器】的下载和配置使用,以及【自定义分词器】的使用,现在对我们的【中文词汇】已经可以进行我们期待中的分割了!
如果这篇【文章】有帮助到你,希望可以给【一心同学】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点,如果有对【后端技术】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【一心同学】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)