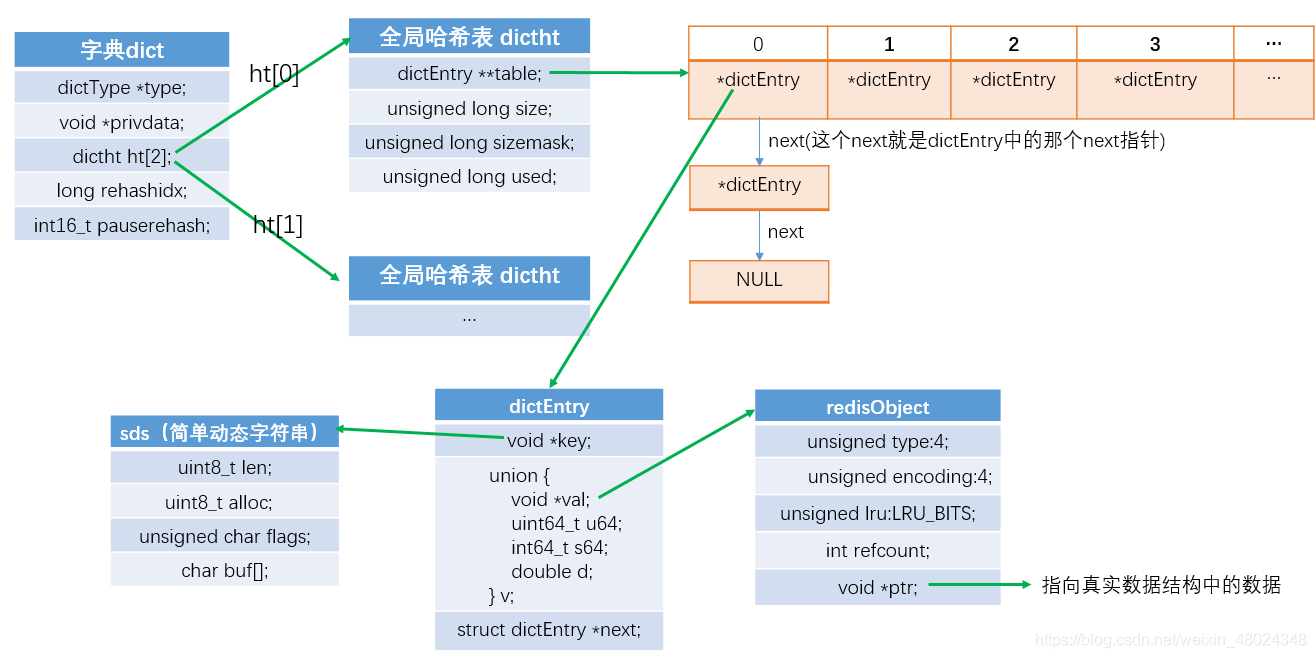
Redis底层是怎样保存一个key和value的?
在了解这个之前,首先要了解一下redis中定义的几种数据结构。sds(简单动态字符串)SDS以Redis中定义的一种用于存储字符串的数据结构。redis中保存的key都是以sds的形式存储的。sds在redis源码中的定义如下:typedef char *sds;//sdshdr5 is never usedstruct __attribute__ ((__packed__)) sdshdr5 {
在了解这个之前,首先要了解一下redis中定义的几种数据结构。
sds(简单动态字符串)
SDS以Redis中定义的一种用于存储字符串的数据结构。redis中保存的key都是以sds的形式存储的。
sds在redis源码中的定义如下:
typedef char *sds;
//sdshdr5 is never used
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 当前字符数组长度
uint8_t alloc; //当前字符数组总共分配的内存大小
unsigned char flags; //当前字符数组的属性。用来标识到底是sdshdr8 还是sdshdr16 等
char buf[]; //字符串真正的值
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
sdshdr和sds是一一对应的关系,一个sds一定会有一个sdshdr用来记录sds的信息。在redis3.2分支出现之前sdshdr只有一个类型,而在3.2之后,引入了五种sdshdr类型。其中sdshdr5 只是定义,并不会被使用。
在创建一个sds时根据sds的实际长度判断应该选择什么类型的sdshdr,不同类型的sdshdr占用的内存空间不同。这样细分一下可以省去很多不必要的内存开销。
redis中的key都是以这种数据结构来保存的。redis中字符串类型的value也会使用sds来保存。这个之后会详细说到。
其实sds本身也是使用char类型数组来实现的,我们知道c语言中的字符串用char类型数组来表示,那么既然redis是基于c的,为什么不直接使用c语言字符串呢?
理由如下:
-
可以常数复杂度获取字符串长度
通过len属性直接获取字符串实际长度,不包括结尾的’\0’. 时间复杂度O(1)
-
防止缓冲区溢出
strcat()函数不能保证目的内存是足够的。
-
减少修改字符串导致内存重分配的次数
空间预分配策略,Redis可以减少连续执行字符串增长所需的内存重分配次数。
-
二进制安全
C语言中的字符串以’\0’结尾,而Redis由于使用len记录数据长度,而不是使用空字符判断字符串是否结束,所以简单动态字符串可以存储包含空字符的数据.
redisObject
redisObject 是 Redis 类型系统的核心, 数据库中的每个键、值, 以及 Redis 本身处理的参数, 都表示为这种数据类型。比如list,set, hash等redis支持的数据类型,在底层都会以redisObject的方式来存储。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
type: 4位,表示具体的数据类型,比如String, Hash, List, Set, Sorted Set等。
encoding: 表示该值具体的编码方式或使用的数据结构,比如sds,压缩列表, hash表等
lru:最近一次被访问的时间。用于通过LRU算法进行内存淘汰的时候使用
refcount: 对象引用计数
ptr: 指向真正数据的指针,在我们通过key获取value时,其实最终就是通过这个ptr指针找到真正的数据。
注:type对应的取值有以下几种:
/*
* 对象类型
*/
#define REDIS_STRING 0 // 字符串
#define REDIS_LIST 1 // 列表
#define REDIS_SET 2 // 集合
#define REDIS_ZSET 3 // 有序集
#define REDIS_HASH 4 // 哈希
dictEntry
dictEntry是redis中key和value的结合。我们向redis保存的key和value最后会被封装为一个dictEntry。
这里需要注意:key和value分别是一个redisObject。其实dictEntry本身也可看做是一个redisObject。
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
key:顾名思义,保存了key的值
*val:保存了value的值。这个值可以是一个指向真正值的指针,也可以是一个uint64_t u64或int64_t s64的整数,又或者是一个double类型的数。
*next:指向下一个dictEntry的指针。dictEntry最终是保存在一个hash表中,那么在产生hash冲突的时候,就会以链表的方式来连接。这个时候就需要用到这个指针了。
至于这个hash表,就是dictht。
dictht
dictht 定义了一个hash表的结构,表中保存的是指向dictEntry的指针。
我们向redis中存取数据的时候,都要通过这个hash表来进行寻找。类似java中hashMap底层的hash表,而dictEntry就相当于hashmap中的entry或node节点。
如果产生了hash冲突,这些dictEntry会采用链表的方式使用next指针来连接。
但dictht和hashmap底层的hash表并不完全相同,这样类比只是方便理解。
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
**table:hash表数组
size: 哈希表大小,即哈希表数组大小
sizemask:哈希表大小掩码,总是等于size-1,主要用于计算索引
used: 已使用节点数,即已使用键值对数
dict(字典)
dict是一个用于维护key和value映射关系的数据结构,与Java中的Map类似。我们对数据的各种操作其实都是通过这个dict来实现的。
typedef struct dict {
dictType *type;
void *privdata; //私有数据指针(privdata)由调用者在创建dict的时候传进来,在dictType的某些操作被调用时会传回给调用者,
dictht ht[2]; //底层用来存数据的hash表 2个
long rehashidx; // rehash的索引。 渐进式rehash时用到
int16_t pauserehash; //暂停rehash的标志。 >0表示已暂停。 <0表示编码错误 =0表示正在rehash
} dict;
*type: 是一个dictType结构的指针,而这个dictType结构中定义了多个函数。这些函数多是对key和value相关的一些操作。
*privdata: 私有数据指针(privdata)由调用者在创建dict的时候传进来,在dictType的某些操作被调用时会传回给调用者
ht[2]:底层用来存数据的hash表 2个, dictht,这个在上面提到了。至于为什么是2个,主要涉及到hash表的扩容和缩容。参考: Redis中字典dict的rehash和渐进式rehash
dictType
上面提到在dict类型中定义了一个dictType类型的type。现在来看看他是干什么的。
dictType结构包含若干函数指针,用于dict的调用者对涉及key和value的各种操作进行自定义
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); //对key进行哈希值计算的哈希算法
void *(*keyDup)(void *privdata, const void *key); //对key的拷贝函数,用于在需要的时候对key进行深拷贝,而不仅仅是传递对象指针
void *(*valDup)(void *privdata, const void *obj); //对value的拷贝函数,用于在需要的时候对value进行深拷贝,而不仅仅是传递对象指针
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //定义两个key的比较操作,在根据key进行查找时会用到
void (*keyDestructor)(void *privdata, void *key); //对key的析构函数
void (*valDestructor)(void *privdata, void *obj); //对value的析构函数
int (*expandAllowed)(size_t moreMem, double usedRatio); //判断dict是否需要扩展
} dictType;
总结来说,dictType就是定义了涉及到底层hash表的一些关于key和value的操作。
比如:
-
在我们向redis中保存或者获取值时,计算key的hash,好确定该键值对在底层hash表中的索引位置
-
在hash冲突时,比较两个key的值是否一样
-
在hash表扩容的时候, 需要拷贝ht[0]表中的key和value到ht[1]中去。
等等。
总结
到这里,我们大致可以总结出redis保存数据的方式:
- key会以sds的方式保存
- value会以redisObject的方式保存
- key和value会封装为一个dictEntry
- dictEntry会保存到一个dictht维护的hash表中(指针),做为hash表中的一个节点
- dictEntry在hash表中的保存位置由dict(字典)来进行计算。
- dict中维护了两个dictht(hash表),主要是用于扩容和缩容时,将数据迁移到另一个hash表中。
- 我们向redis中的存取操作,最终都是通过dict(字典)来操作的。
图示
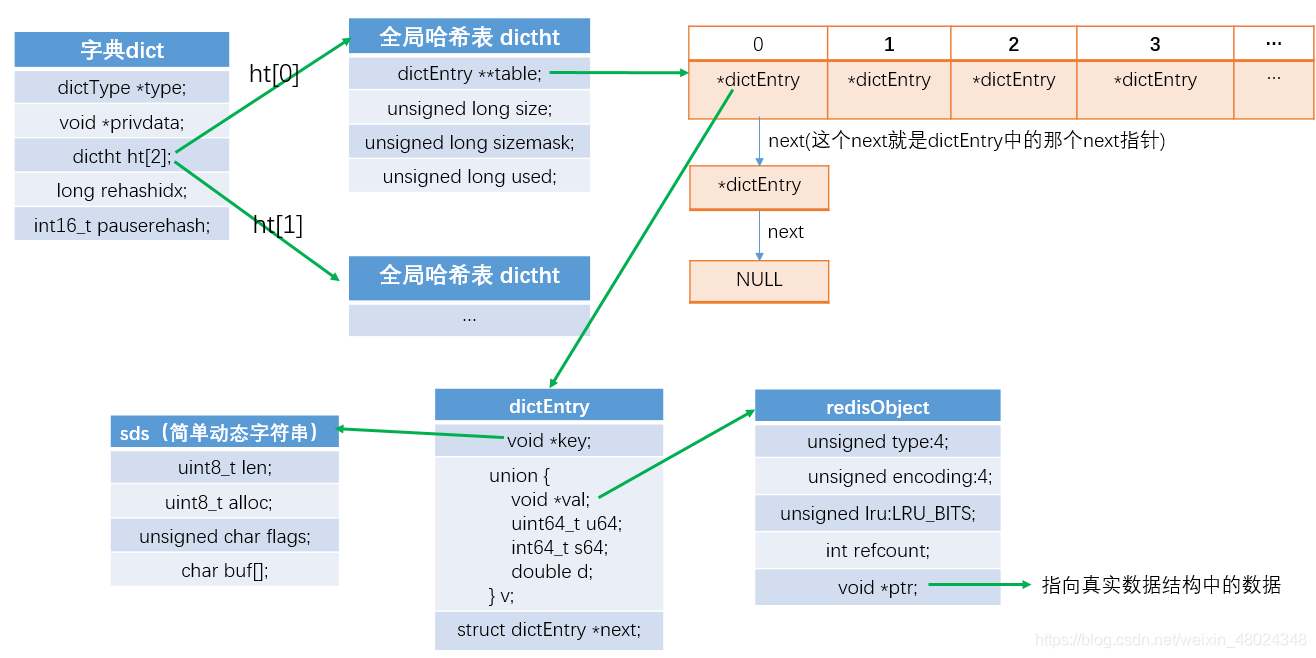
上面我们看到,redisObject中的*ptr指针,指向了我们保存的数据的真正位置。那么这个数据到底是以什么样的方式保存的呢?这里就要说以下redisObject中encoding了。
redisObject中的encoding
在介绍redisObject时,我们注意到在该类型中定义了一个encoding变量。这个变量代表该值对应的底层数据结构。
也就是说,虽然String,list,set,hash,sorted set 这5种类型,都使用redisObject来保存。
但是他们真正底层的保存方式和数据结构还是不同的。
到底是使用双端链表,还是压缩列表,还是hashtable,到底是用哪一种更节省内存空间?哪一种查询效率更高?
这要根据不同的数据类型和不同的情况来进行区分。
redis对redisObject的所有编码类型做了以下定义:
#define OBJ_ENCODING_RAW 0 /* 大于44个字节的字符串 */
#define OBJ_ENCODING_INT 1 /* 8个字节的长整型。 */
#define OBJ_ENCODING_HT 2 /* hash表 */
#define OBJ_ENCODING_ZIPMAP 3 /* 压缩map */
#define OBJ_ENCODING_LINKEDLIST 4 /* 双端链表, 已废弃 */
#define OBJ_ENCODING_ZIPLIST 5 /* 压缩列表 */
#define OBJ_ENCODING_INTSET 6 /* 整数集合 */
#define OBJ_ENCODING_SKIPLIST 7 /* 跳跃表 */
#define OBJ_ENCODING_EMBSTR 8 /* 小于等于44个字节的字符串 */
#define OBJ_ENCODING_QUICKLIST 9 /* quicklist (linkedlist + ziplist) */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
redis中5种数据类型对应的底层可能使用的编码方式为:
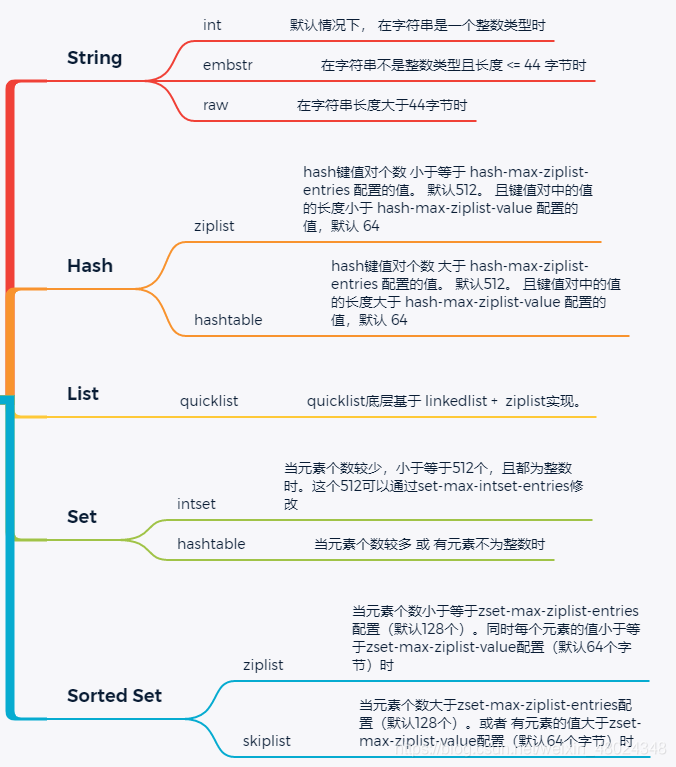
至于每种编码方式的具体实现方式,之后再谈。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)