2、Elasticsearch分词器简介与使用(一)
介绍说明ES内置的几种分词器,以及第三方的中文分词器,以及如何使用它们。
一、分词器的概念
1、Analysis Phase
在文档(Document)被添加到反向索引(inverted index)之前,Elasticsearch 对文档正文执行的过程称为分析阶段(Analysis Phase)。如下图所示,可以很形象的说明一个文档被 Ingest Node 接入时需要经历的步骤:
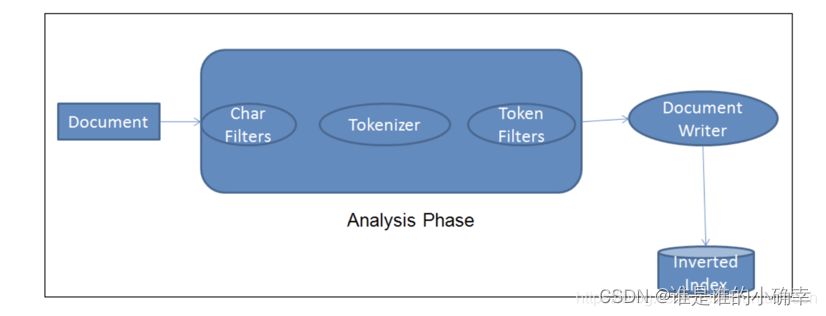
分析阶段的这部分就是分析器 Analyzer,通常是由 Char Filters、Tokenizer、Token Filter 组成的,它们的功能和特点如下:
- Char Filters:字符过滤器执行的是过滤和转换特定字符的工作,比如,过滤标点符号、过滤数字、过滤HTML标签、将 & 转换成 and 等;
- Tokenizer:分词器,它是整个 Analyzer 的核心部分,可以基于任何规则完成文本的拆分,拆分之后的词项称为术语(分词 token);
- Token Filter:token 一旦被创建,则会传递给分词过滤器,由分词过滤器进行规范化处理,例如新增 token、修改 token 或者 删除 token。
请注意,一个 Analyzer 只能有一个 Tokenizer ,但可以有0或多个Char Filters,有0或多个Token Filter。例如,ES 默认的缺省分析器是 standard 分析器,它没有 Char Filters,分词器为 standard Tokenizer,通过 Token Filter 会将英文单词大写转小写,会去除停用词(如 of,the 这些单词)等。
2、Analysis API
Analyzer 将文本字符分解为 token 的过程,通常会发生在以下两种场景:一是索引建立的时候,二是进行文本搜索的时候。Analyzer 也提供了一套常用 API 给开发者使用,通过这些 API 可以测试如何解析输入的文本字符串,了解一下:
GET /_analyze
POST /_analyze
GET /<index>/_analyze
POST /<index>/_analyze接下来,使用这些 API 来学习和使用内置分词器和第三方的分词器。
二、ES 内置分词器
ES 本身提供了比较丰富的开箱即用的 Analyzer,例如:standard、simple、whitespace、stop、keyword、pattern、language、fingerprint 等内置分词器,其中 standard 是 ES 索引默认的分词器,更多更详细的介绍说明可以参考官方文档:
Built-in analyzer reference | Elasticsearch Guide [7.17] | Elastic
接下来,一起看下这些分词器的特点以及如何使用的?
1、standard 分词器
它是 ES 的缺省分词器,特点如下:无Char Filter,使用的是 standard tokonizer,会转小写,会过滤大多数的标点符号。
举例说明:
使用 _analyze 对文本进行分词测试:
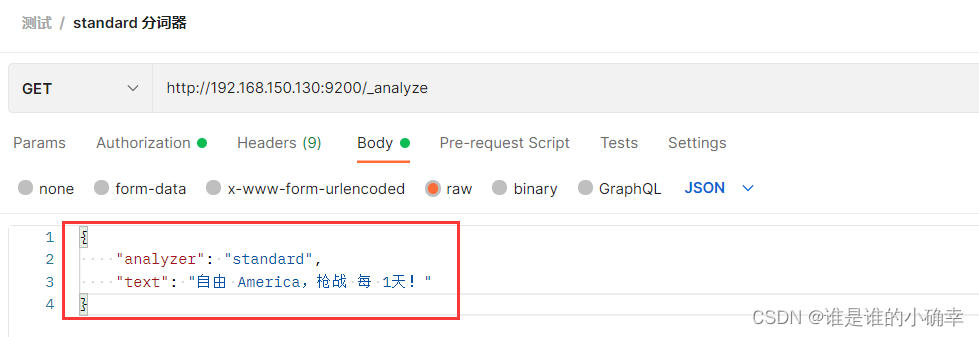
得到的结果如下:(结果显示,英文单词转成了小写,空白符和感叹号被过滤)
{
"tokens": [
{
"token": "自",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "由",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "america",
"start_offset": 3,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "枪",
"start_offset": 11,
"end_offset": 12,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "战",
"start_offset": 12,
"end_offset": 13,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "每",
"start_offset": 14,
"end_offset": 15,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "1",
"start_offset": 16,
"end_offset": 17,
"type": "<NUM>",
"position": 6
},
{
"token": "天",
"start_offset": 17,
"end_offset": 18,
"type": "<IDEOGRAPHIC>",
"position": 7
}
]
}2、simple 分词器
该分词器会按照非字母字符切分,会转小写,会过滤掉数字和标点符号,仍用上面的文本举例说明:
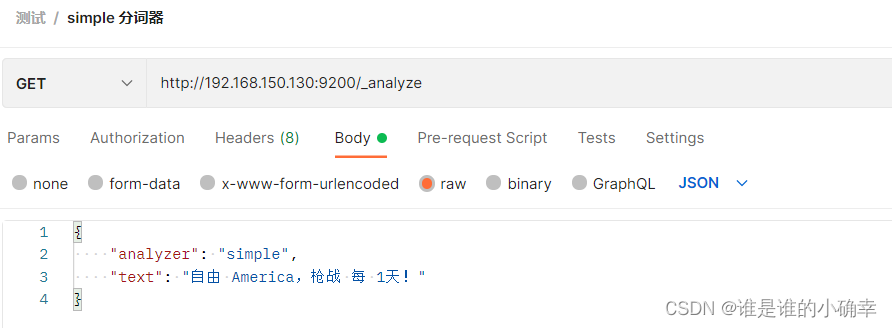
得到的结果如下:
{
"tokens": [
{
"token": "自由",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "america",
"start_offset": 3,
"end_offset": 10,
"type": "word",
"position": 1
},
{
"token": "枪战",
"start_offset": 11,
"end_offset": 13,
"type": "word",
"position": 2
},
{
"token": "每",
"start_offset": 14,
"end_offset": 15,
"type": "word",
"position": 3
},
{
"token": "天",
"start_offset": 17,
"end_offset": 18,
"type": "word",
"position": 4
}
]
}3、whitespace 分词器
顾名思义,它是按照空白字符进行切分的,不会小写转换,也不会过滤数字和标点符号等,继续用上面的文本举例说明:
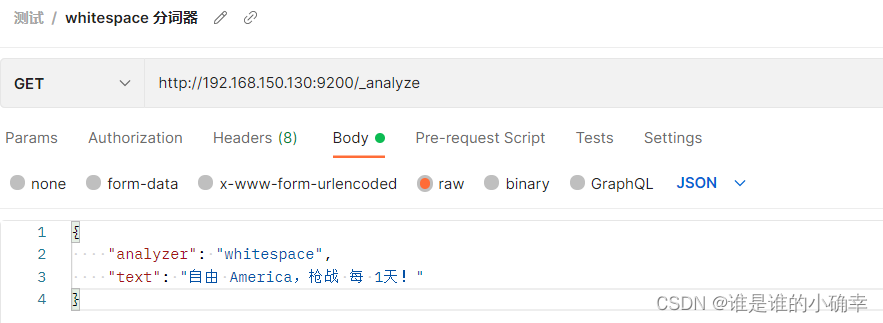
得到的结果如下:
{
"tokens": [
{
"token": "自由",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "America,枪战",
"start_offset": 3,
"end_offset": 13,
"type": "word",
"position": 1
},
{
"token": "每",
"start_offset": 14,
"end_offset": 15,
"type": "word",
"position": 2
},
{
"token": "1天!",
"start_offset": 16,
"end_offset": 19,
"type": "word",
"position": 3
}
]
}4、stop 分词器
该分词器会删除停用词(比如,of,is, a, the ....),会转小写,会过滤掉数字和标点符号,继续用上面的文本举例说明:
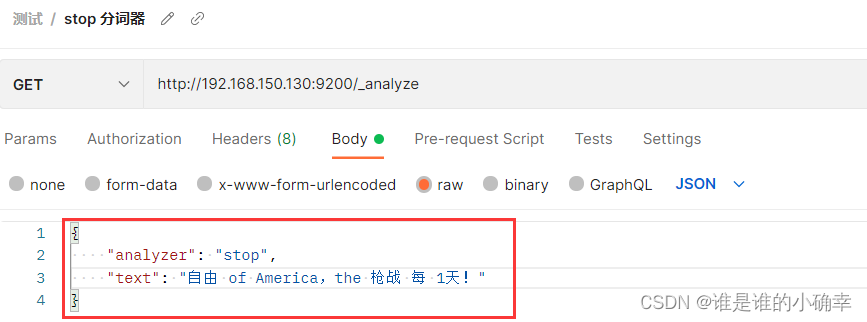
得到的结果如下:(与 simple 分词器比较像)
{
"tokens": [
{
"token": "自由",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "america",
"start_offset": 6,
"end_offset": 13,
"type": "word",
"position": 2
},
{
"token": "枪战",
"start_offset": 18,
"end_offset": 20,
"type": "word",
"position": 4
},
{
"token": "每",
"start_offset": 21,
"end_offset": 22,
"type": "word",
"position": 5
},
{
"token": "天",
"start_offset": 24,
"end_offset": 25,
"type": "word",
"position": 6
}
]
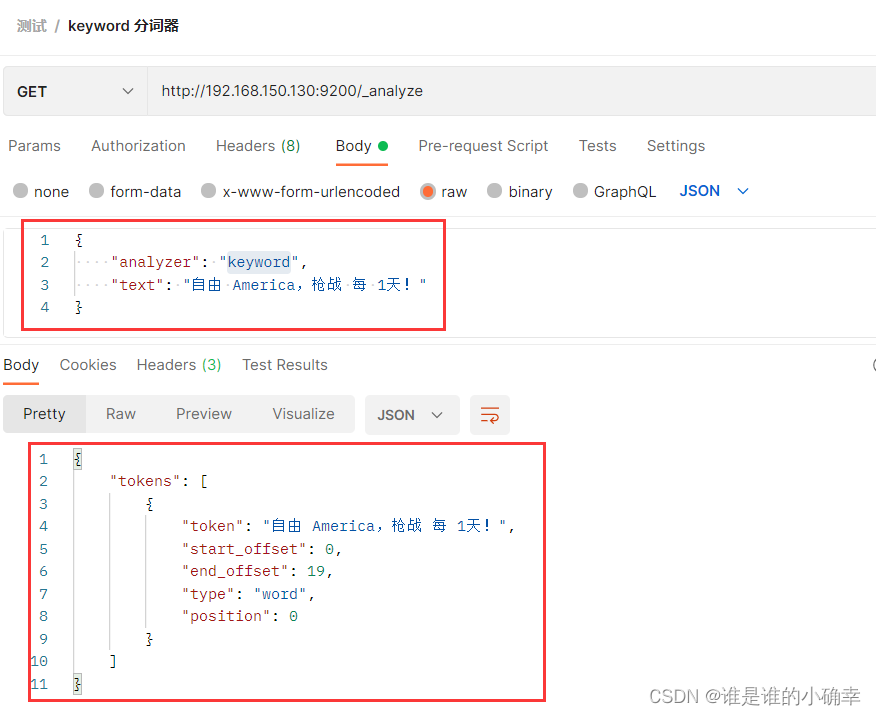
}5、keyword 分词器
该分词器根据输入文本进行输出,不做任何转换。注意,Analyzer 只作用于text 类型的字段,而对于 keyword 类型的字段,将不被分析和分词,keyword 字段更倾向于被用在精确匹配及聚合。
6、pattern 分词器
该分词器会按照给定的 Java 正则表达式切分,默认支持字符串转小写和使用停用词。该分词器的使用有一定的难度,前提需要熟悉正则表达式,实际中不太使用这种分词器。另外,如果需要自定义该分词器,可以参考官方文档给出的例子:
Pattern analyzer | Elasticsearch Guide [7.17] | Elastic
7、language 分词器
顾名思义,该分词器会按照给定的语言类型切分,支持很多的语言类型,有:

不同的语言类型对应了该语言的分词器,常用的有 english 分词器,french 分词器等,具体使用可以参考官方文档给出的例子:
Language analyzers | Elasticsearch Guide [7.17] | Elastic
language 分词器支持使用停止词,支持从词干(stem)排除单词,比如 english 分词器会按词干进行分词:
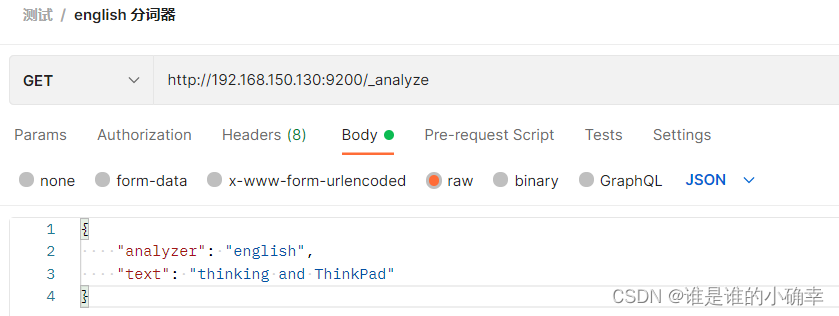
得到的结果如下:(可以看到,分词后的结果会有think,而think就是词干)
{
"tokens": [
{
"token": "think",
"start_offset": 0,
"end_offset": 8,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "thinkpad",
"start_offset": 13,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 2
}
]
}8、fingerprint 分词器
该分词器通过一种指纹算法,支持过滤扩展字符,支持排序,支持去重,通过配置还可以支持使用停止词。该分词器用法不再举例了,需要使用它时,可参考官方文档给出的例子:
Fingerprint analyzer | Elasticsearch Guide [7.17] | Elastic
三、中文分词器及使用
ES 内置的分词器并不能满足中文分词的需求,例如,文本内容为"阿富汗紧张局势",使用 standard 分词器和 english 分词器时,会切分每一个单词,其余的分词器则直接切分成"阿富汗紧张局势",这明显不符合中文分词需求。因此,我们需要额外安装中文分词器解决中文分词问题。目前比较流行的中文分词器有:ik中文分词器、hanlp中文分词器等,这里会重点说明 ik 中文分词器。
1、ik 中文分词器
ik 中文分词器实现了以词典分词为基础的正反向全切分(ik_smart),以及正反向最大匹配切分(ik_max_word)两种类型,ik_smart 是将文本做最粗粒度的拆分,而 ik_max_word 会做最细粒度的拆分。因为 ik 中文分词器是第三方插件,注意下载时需要对应当前的 Elasticsearch 版本,下载地址:
Releases · medcl/elasticsearch-analysis-ik · GitHub
我使用的是 6.8.6 版本,下载和解压的操作步骤,如下:
# 下载
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.6/elasticsearch-analysis-ik-6.8.6.zip
# 解压到 Elasticsearch 的 plugins目录下,在这之前自己新建一下ik目录
[myes@localhost elasticsearch-6.8.6]$ ls
bin config data lib LICENSE.txt logs modules NOTICE.txt plugins README.textile
[myes@localhost elasticsearch-6.8.6]$ unzip elasticsearch-analysis-ik-6.8.6.zip -d ./plugins/ik/将 ik 分词器的压缩包解压后,重启 Elasticsearch 就可以使用了。如果 wget 命令无法下载,可访问上面的 Releases 插件地址,找到对应的ik插件版本下载到本地,然后再上传到服务器,需要将zip解压在 ./plugins/ik/位置。通过如下命令,检查 ik 插件是否安装成功:
[myes@localhost elasticsearch-6.8.6]$ ./bin/elasticsearch-plugin list
ik
[myes@localhost elasticsearch-6.8.6]$
接着,使用 ik_smart 做下测试,如下:
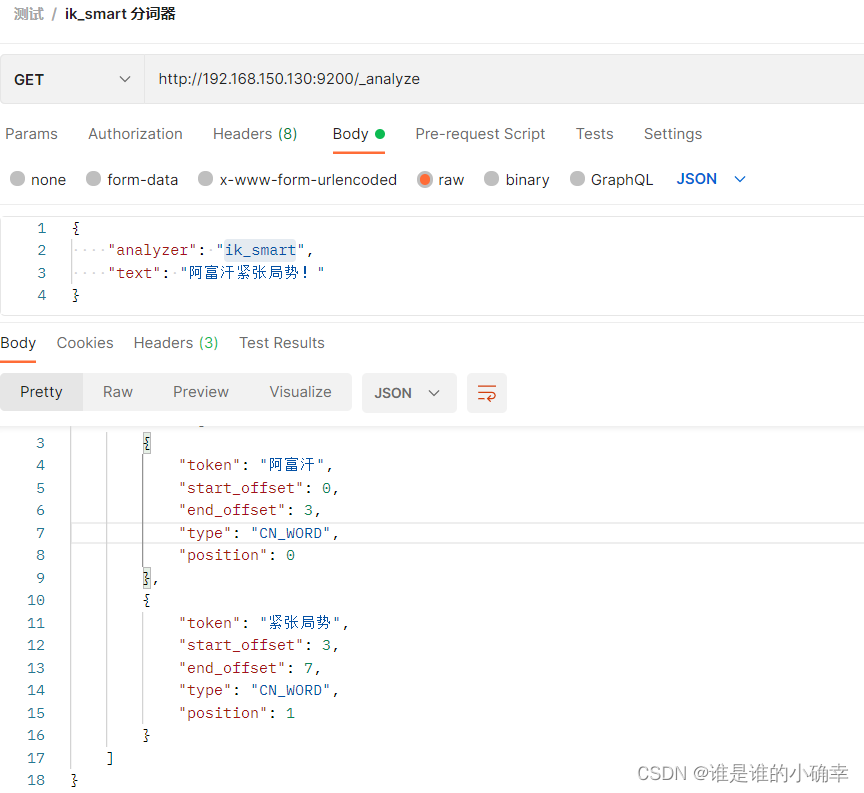
然后,使用 ik_max_word 做下测试,如下:
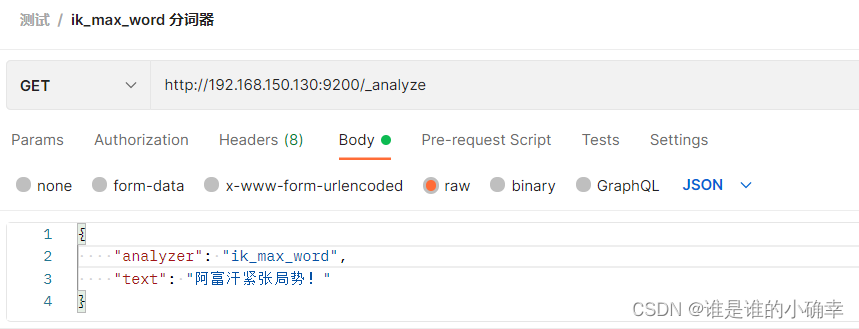
ik_max_word 得到的结果:(可以看到拆分词项的粒度更细)
{
"tokens": [
{
"token": "阿富汗",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "阿富",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "汗",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "紧张局势",
"start_offset": 3,
"end_offset": 7,
"type": "CN_WORD",
"position": 3
},
{
"token": "紧张",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "局势",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 5
}
]
}2、hanlp 中文分词器
该分词器是专门为 Elasticsearch 设计的一款开源的中文分词器,基于HanLP 提供了 HanLP 中大部分的分词方式。hanlp 中文分词器一直在跟随 Elasticsearch 的不同发行版而更新着,目前最新版本为7.10.2,源码地址如下:
GitHub - KennFalcon/elasticsearch-analysis-hanlp: HanLP Analyzer for Elasticsearch
从 GitHub 给出的文档来看,可通过以下两种方式进行下载安装 ES 对应 Plugin Release 版本:
方式一
a. 下载对应的 release 安装包,最新 release 包可从baidu盘下载(链接:百度网盘 请输入提取码 密码:i0o7)
b. 执行如下命令安装,其中 PATH 为插件包绝对路径:
./bin/elasticsearch-plugin install file://${PATH}方式二
a. 使用 elasticsearch 插件脚本安装命令如下:
./bin/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v6.5.4/elasticsearch-analysis-hanlp-6.5.4.zip请注意,release 包中存放的为 HanLP 源码中默认的分词数据,若要下载完整版数据包,可查看HanLP Release。数据包目录:ES_HOME/plugins/analysis-hanlp,因原版数据包自定义词典部分文件名为中文,这里的hanlp.properties中已修改为英文,使用时请对应修改文件名。
在本版本中增加了词典热更新,修改步骤如下:(每个节点都需要做这种更改)
- 在ES_HOME/plugins/analysis-hanlp/data/dictionary/custom目录中新增自定义词典;
- 修改hanlp.properties,修改CustomDictionaryPath,增加自定义词典配置;
- 等待1分钟后,词典自动加载。
hanlp 中文分词器的分词方式有:
- hanlp: hanlp默认分词
- hanlp_standard: 标准分词
- hanlp_index: 索引分词
- hanlp_nlp: NLP分词
- hanlp_n_short: N-最短路分词
- hanlp_dijkstra: 最短路分词
- hanlp_crf: CRF分词(已有最新方式)
- hanlp_speed: 极速词典分词
举例说明:
GET http://192.168.150.130:9200/_analyze
{
"tokenizer": "hanlp",
"text": "四川汶川发生8.0级地震"
}得到结果如下:
{
"tokens" : [
{
"token" : "四川",
"start_offset" : 0,
"end_offset" : 2,
"type" : "nsf",
"position" : 0
},
{
"token" : "汶川",
"start_offset" : 0,
"end_offset" : 2,
"type" : "nsf",
"position" : 1
},
{
"token" : "发生",
"start_offset" : 0,
"end_offset" : 2,
"type" : "v",
"position" : 2
},
{
"token" : "8.0",
"start_offset" : 0,
"end_offset" : 3,
"type" : "m",
"position" : 3
},
{
"token" : "级",
"start_offset" : 0,
"end_offset" : 1,
"type" : "q",
"position" : 4
},
{
"token" : "地震",
"start_offset" : 0,
"end_offset" : 2,
"type" : "n",
"position" : 5
}
]
}如果需要更进一步了解远程词典配置、自定义分词配置等,请参考:GitHub - KennFalcon/elasticsearch-analysis-hanlp: HanLP Analyzer for Elasticsearch
最后
本篇重点介绍了 Elasticsearch 分词器的概念,内置分词器的类型及使用,以及第三方中文分词器的使用,掌握这些分词器的特点之后,在不同的查询场景中选择合适的分词器就会游刃有余了,当然,也可以定制满足项目需求的分词器,下篇再重点介绍如何定制分词器。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)