
flume+kafka+SparkStreaming实时日志分析+结果存储到MySQL
目录一.说明二.flume三.kafka四.MySQL五.IDEA写程序六.运行一.说明1.1使用工具:IDEA,spark-2.1.0-bin-hadoop2.7,kafka_2.11-2.3.1,zookeeper-3.4.5,apache-flume-1.9.0-bin,jdk1.8.0_171Scala版本:2.12.15相关工具的安装请关注我的博客!1.2日志可以到这里下载:testlo
目录
一.说明
1.1使用工具:IDEA,spark-2.1.0-bin-hadoop2.7,kafka_2.11-2.3.1,zookeeper-3.4.5,apache-flume-1.9.0-bin,jdk1.8.0_171
Scala版本:2.12.15

相关工具的安装请关注我的博客!
1.2日志可以到这里下载:testlog7.log-spark文档类资源-CSDN下载
也可以用代码生成:Scala模拟日志生成_一个人的牛牛的博客-CSDN博客
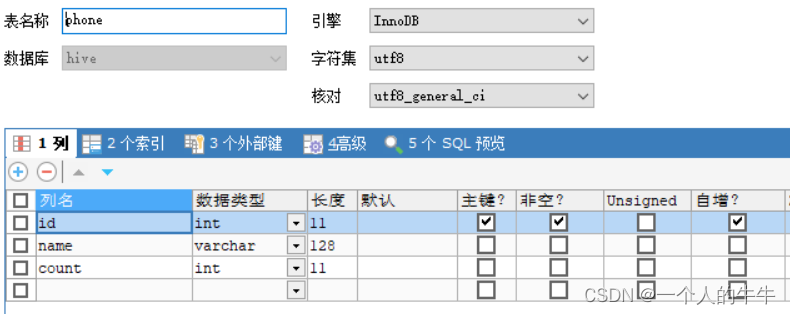
1.3一定要在数据库中建表!!!!!
二.flume
2.1在flume的conf下写flume-kafka.conf
a5.channels=c5
a5.sources=s5
a5.sinks=k5
a5.sources.s5.type=spooldir
#/root/testdata/f-k是flume监控的文件夹
a5.sources.s5.spoolDir=/root/testdata/f-k
a5.sources.s5.interceptors=head_filter
#正则拦截器
a5.sources.s5.interceptors.head_filter.type=regex_filter
a5.sources.s5.interceptors.head_filter.regex=^event_id.*
a5.sources.s5.interceptors.head_filter.excludeEvents=true
#用来关联kafka
a5.sinks.k5.type=org.apache.flume.sink.kafka.KafkaSink
#连接kafka,hadoop01是我的虚拟机主机名
a5.sinks.k5.kafka.bootstrap.servers=hadoop01:9092
#topic的主题名要一致fktest
a5.sinks.k5.kafka.topic=fktest
a5.channels.c5.type=memory
a5.channels.c5.capacity=10000
a5.channels.c5.transactionCapacity=10000
a5.sinks.k5.channel=c5
a5.sources.s5.channels=c5
2.2建/root/testdata/f-k文件夹
2.3启动flume的flume-kafka.conf(在flume的目录下)
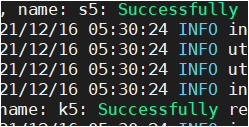
bin/flume-ng agent -f conf/flume-kafka.conf -n a5 -Dflume.root.logger=INFO,console看到k5,c5,s5到成功启动了(有Successfully)就是正常
三.kafka
3.1开启kafka(在kafka的目录下)(一定要先开启zookeeper)
bin/kafka-server-start.sh -daemon config/server.properties3.2建topic在kafka的目录下
bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic fktest查看topic
bin/kafka-topics.sh --zookeeper hadoop01:2181 --list3.3打开kafka的消费者(在kafka的目录下)(hadoop01是我的主机名)
bin/kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic fktest --from-beginning四.MySQL
4.1建表
五.IDEA写程序
5.1导入依赖(我的依赖)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>14.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.artifact.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- 使用scala2.11.8进行编译和打包 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.12</artifactId>
<version>2.4.8</version>
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.9.0</version>
</dependency>5.2代码:
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
//写人MySQL表的表名和列名,string,int是数据格式
case class phone(
name: String,
count:Int
)
object KafkaDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KafkaTest")
val streamingContext = new StreamingContext(sparkConf, Seconds(20))
//20秒更新一次结果
//连接kafka导入数据,hadoop01是我的虚拟机主机名
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "hadoop01:9092",从broker消费数据
"key.deserializer" -> classOf[StringDeserializer],//发序列化的参数,因为写入kafka的数据经过序列化
"value.deserializer" -> classOf[StringDeserializer],//发序列化的参数,因为写入kafka的数据经过序列化
"group.id" -> "use_a_separate_group_id_for_each_stream",//指定group.id
"auto.offset.reset" -> "latest",//指定消费的offset从哪里开始:① earliest:从头开始 ;② latest从消费者启动之后开始
"enable.auto.commit" -> (false: java.lang.Boolean) //是否自动提交偏移量 offset 。默认值就是true【5秒钟更新一次】, "false" 不让kafka自动维护偏移量 手动维护偏移
)
//kafka的topic
val topics = Array("fktest", "test")
//订阅主题
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//转换格式
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
//分析处理出想要的数据
val resultRDD: DStream[(String, Int)] = mapDStream.map(lines=>{
val data = lines._2.split("_")
(data(1),1)}).reduceByKey(_+_)
//将DStream中的数据存储到mysql数据库中
resultRDD.foreachRDD(
rdd=>{
val url = "jdbc:mysql://192.168.17.128:3306/hive?useUnicode=true&characterEncoding=UTF-8"//192.168.17.140是我的主机IP地址,可以用localhost。hive是我的数据库名
val user = "root"//MySQL用户名
val password = "1234567"//MySQL密码
Class.forName("com.mysql.jdbc.Driver").newInstance()//驱动
rdd.foreach(
data=>{
var conn: Connection = DriverManager.getConnection(url,user,password)
val sql = "insert into phone(name,count) values(?,?)"
//第一个phone是表名,(name,count)是列名
var stmt : PreparedStatement = conn.prepareStatement(sql)
stmt.setString(1,data._1.toString)
stmt.setString(2,data._2.toString)
stmt.executeUpdate()
conn.close()
}
)
}
)
//输出结果到控制台
resultRDD.print()
// 启动
streamingContext.start()
// 等待计算结束
streamingContext.awaitTermination()
}
}4.3运行程序
六.运行
6.1在/root/testdata/f-k文件夹里面添加数据,直接拖入xxx.log。
flume处理后是这样的。

6.2拖入后kafka消费者会显示内容。
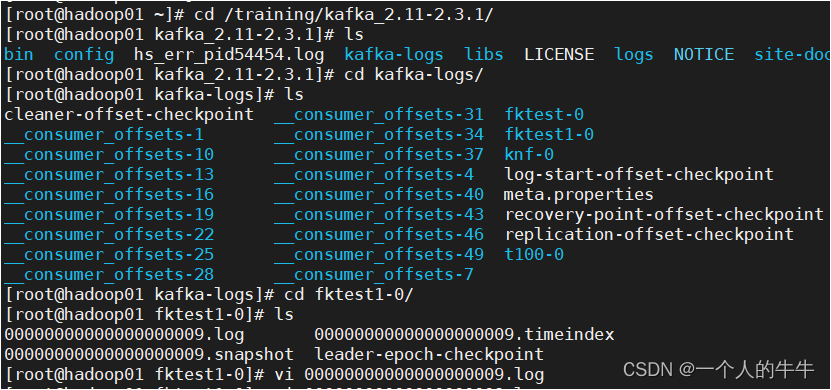
6.3没有开消费者的话可以到kafka设置的日志文件夹下查看。
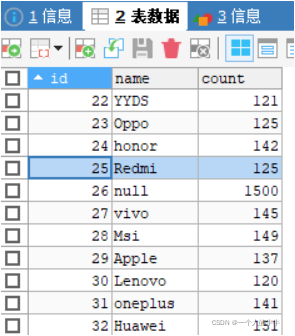
6.4MySQL的显示
谢谢!!!!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)