Docker+EFK 快速搭建日志收集系统(包含具体细节和操作使用说明)
Docker+EFK 快速搭建日志收集系统(包含具体细节和操作使用说明)
1、为什么需要日志系统?
首先咱们会想到分布式日志管理系统 ELK。
分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
今天说的是EFK F是FileBeat,隶属于Beats,是个搜集文件数据。
FileBeat对比Logstash :
LogStash出现的时间相对Beats较早,使用java写的,相关插件使用jruby写的,对于机器消耗的资源会比Beats消耗很多,Beats(Beats包括的子产品有FileBeat,MetricBeat等,FileBeat用于采集日志)是用go语言写的在性能上更胜一筹,而且非常轻量级占用的系统资源更少,但是Beats相对于LogStash的插件更少,对于快速搭建日志系统已经够用了,后续也会给出在日志量增加的情况下怎么升级日志系统。
2.开始搭建 docker+EFK
先说一下注意事项
- 只是简单的方案,目前存在日志收集完,日志散乱
- 多服务日志配置比较繁琐,需要更熟悉filebeat。(多服务日志建议挂载一个目录下)
- EFK镜像版本一定要一致
- 使用Filebeat既可能产生数据重复(至今不会解决哈哈哈)
- Es配置合理的内存
首先拉取镜像(如何搭建docker环境本文就不赘述了,baidu或者google很多教程),这里用的版本都是最新的7.7.1版本,具体版本可以根据自己的需要选取,建议最少6.7版本以上,因为每升一个版本都会增加一些新的东西,也会优化很多东西。
2.1 首先使用docker拉取镜像(一定要6.7版本以上的): 当前是7.7.1
docker pull elasticsearch:7.7.1等待拉取镜像即可(这里拉取可能会很慢,因为镜像在dockerHub上,可以去配置国内的镜像加速器,这里推荐两个一个是阿里云的镜像加速,一个是DAOCloud的镜像加速 都不错,读者可以根据自己的网络情况都试一下,在配置文件中配置registry-mirrors"即可。
2.2 拉取镜像之后查看自己的镜像列表
docker images
2.3 运行镜像
docker run -d -e ES_JAVA_POTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" -p 9200:9200 -p 9300:9300 --name es7.7.1 830a894845e3
这里以单节点的方式启动,指定堆内存为512m(因为不指定的话Es的初始内存很高,你的机器内存不够的话就OOM了,根据自己具体环境配置更改大小),指定单节点方式启动(如果以集群方式启动的话更改模式即可,这里以单节点方式演示 -e "discovery.type=single-node"),暴露映射 9200端口和9300端口。--name es7.7.1 830a894845e3 指定镜像名称和image id
2.4 启动 es 后 查看es 是否已启动(包括运行失败的)
docker ps -a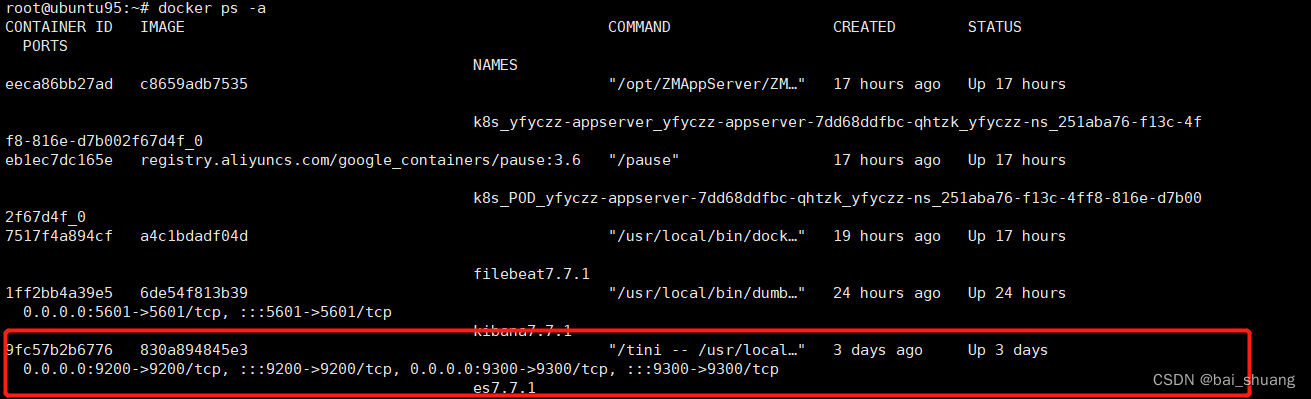
查看运行日志(应为我上面定义的 镜像名称为:es7.7.1,所以下面命令如下:如命名不一样请修改为自己的名称)
docker logs -f es7.7.1如果启动失败的话可以查看日志,找出具体原因
查看es 是否已启动
curl "127.0.0.1:9200" 显示这个说明你安装启动成功了
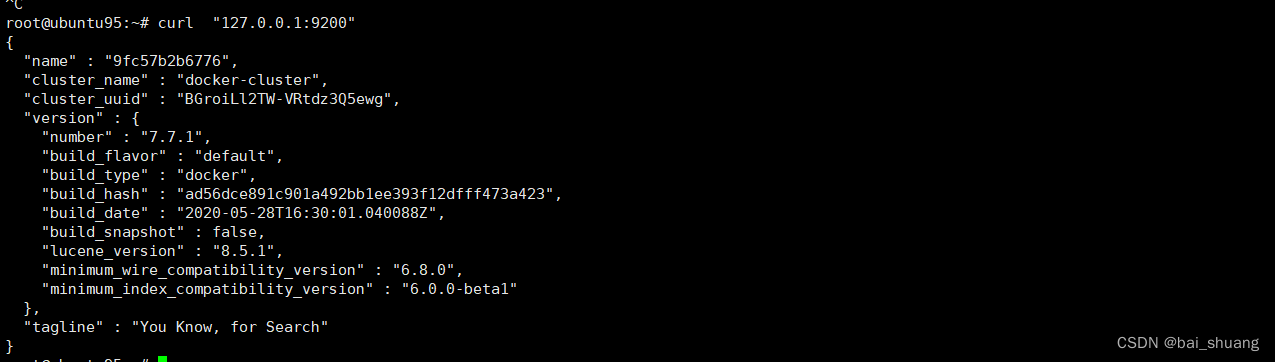
es 搭建完毕,相对solr 简单很多!!!
3.kibanna 安装及配置
3.1同样拉取 Kibana 镜像
docker pull kibana:7.7.1 3.2启动kibana镜像(应为我上面定义的 镜像名称为:es7.7.1,所以下面命令如下:如命名不一样请修改为自己的名称)
docker run --link es7.7.1:elasticsearch -p 5601:5601 -v /usr/java/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml -d --name kibana7.7.1 6de54f813b39-v /usr/java/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml 这里 -v 就是挂在目录的意思就是将自己本地的目录挂载到容器当中,需要在自己本地的目录/usr/java/kibana/kibana.yml(可以是自己定义位置)创建自己的配置文件,内容如下:
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"这里主要添加了一个es的地址,http://elasticsearch:9200,elasticsearch就是刚刚link起的别名(--link es7.7.1:elasticsearch),另外就是‘i18n.locale’语言配置,kibana默认是英文界面,修改外为zh-CN就可以汉化。
3.3重启kibana容器(如:提前建立好配置文件可以不用),名称是上面定义的
docker restart kibana7.7.1访问 http://localhost:5601/ 如果成功进入界面,就说明启动成功了。
如果访问失败,同样的通过docker logs kibana7.7.1 查看失败原因。
4. 搭建FileBeat
4.1先search 一下 (我在这里被坑了,docker pull filebeat:7.7.1这个无法下载)
docker search filebeat使用如下版本
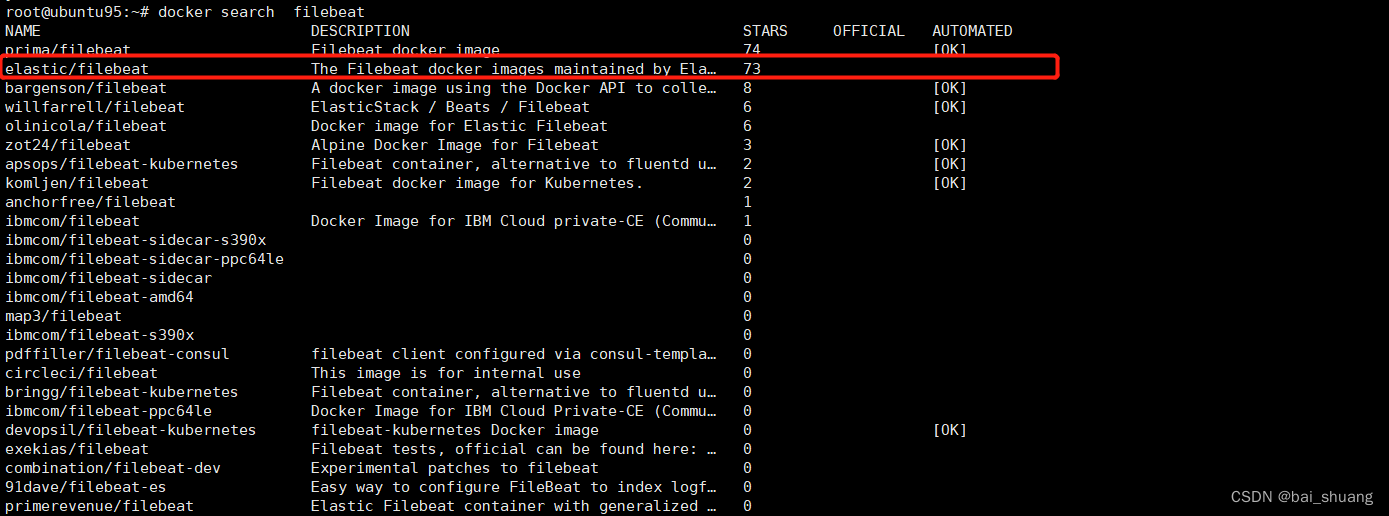
4.2同样拉取 FileBeat 镜像
docker pull elastic/filebeat:7.7.1拉取完成之后,先不着急启动,在启动之前需要完成先建立一份映射的配置文filebeat.docker.yml,选择目录创建filebeat.docker.yml
#=========================== Filebeat inputs ==============
filebeat.inputs:
- type: log
enabled: true
##配置你要收集的日志目录,可以配置多个目录
paths:
- /usr/share/filebeat/logs/testlog/*.log
- /usr/share/filebeat/logs/md-sys/*.log
#-------------------------- Elasticsearch output ---------
output.elasticsearch:
hosts: ["http://elasticsearch:9200"]为什么不直接去filbeat容器里面去改配置文件呢?因为filebeat容器的配置文件是只读的不可更改,所以只能通过映射配置文件的方式修改。
4.3建立好配置文件之后,启动filebeat容器
docker run --user=root -d -v /usr/java/filebeat/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml -v /home/logs:/usr/share/filebeat/logs --link es7.7.1:elasticsearch --link kibana7.7.1:kibana --name filebeat7.7.1 a4c1bdadf04d这里 -v 就是挂在目录的意思就是将自己本地的目录挂载到容器当中,第一个挂载映射的是配置文件,第二个是要收集的日志目录,如果不挂载日志目录的话,filebeat是不会收集日志的,因为在容器里面根本找不到要收集的路径。--user=root 指定启动用户,因为读取文件可能没有权限,link起的别名等信息同上。
4.4启动之后通过docker logs filebeat7.7.1 查看日志
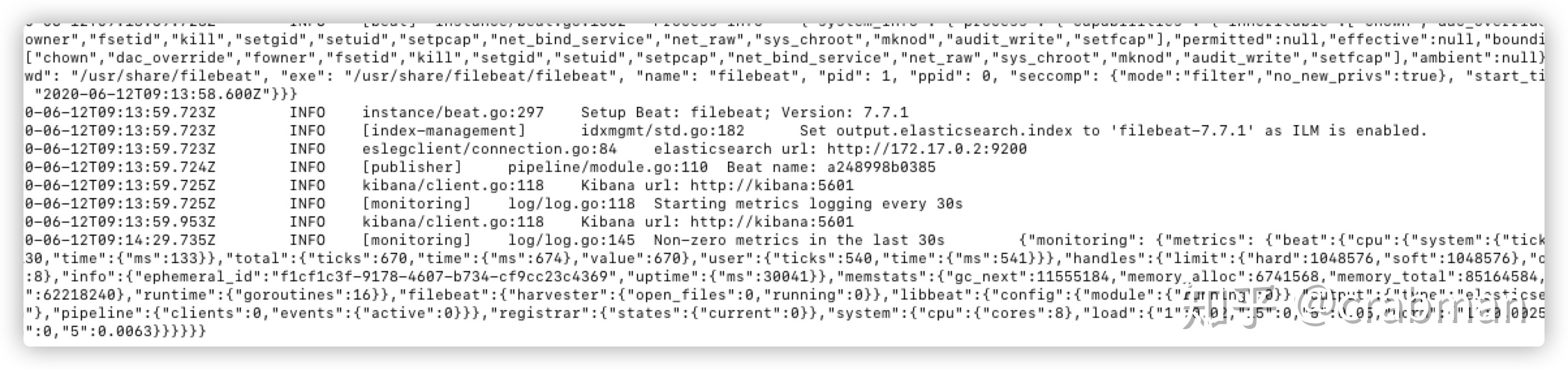
可以看到filebeat已经成功启动了,如果启动失败的话可以看filebeat的配置文件es和kibana的host是否正确。
在收集日志的目录下面添加日志文件,或者更新日志,然后去kibana查看是否有filebeat的索引生成(必须是添加或者更新日志,原有的数据不会同步)。
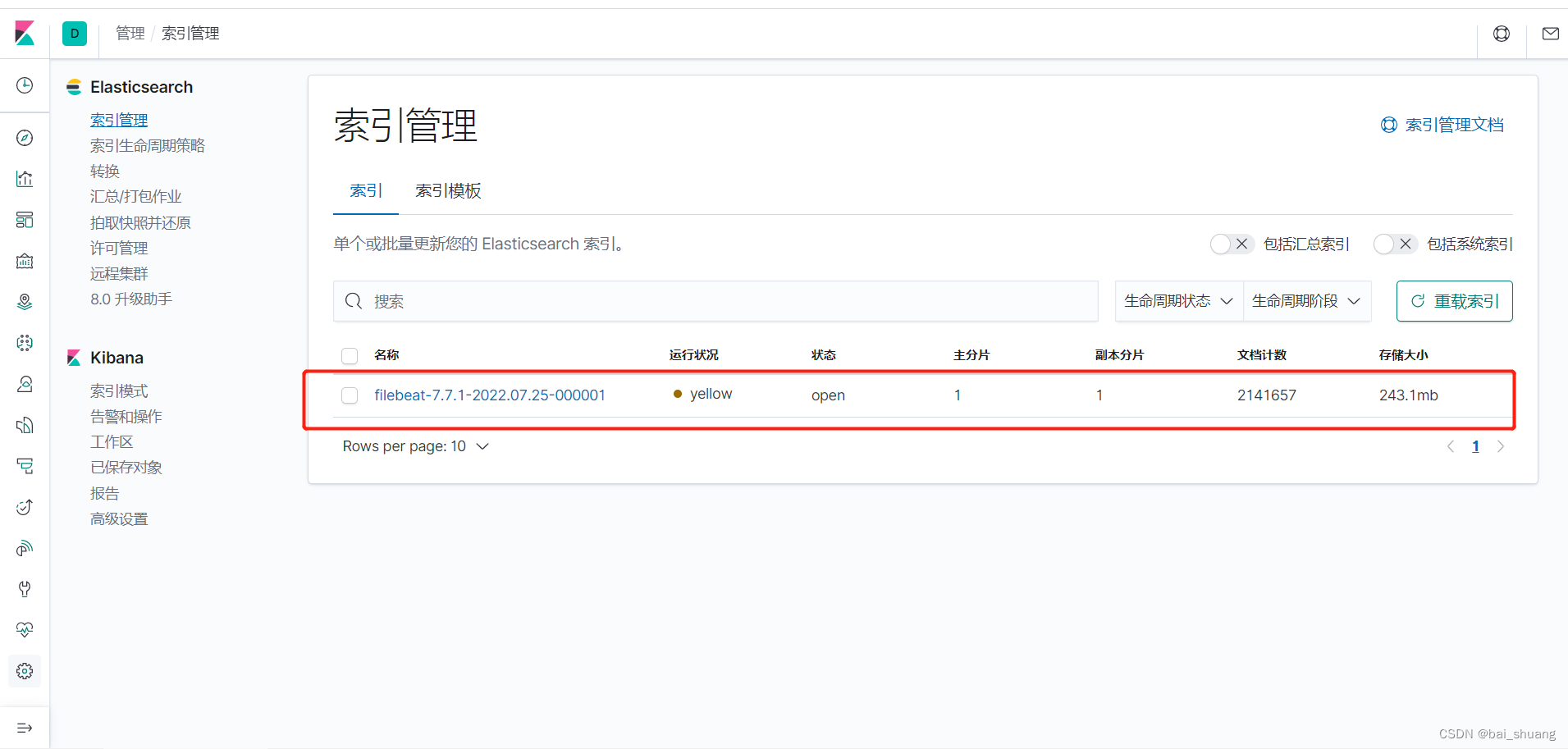
可以看到已经有生成了索引并且有数据了,在Discover查看具体数据
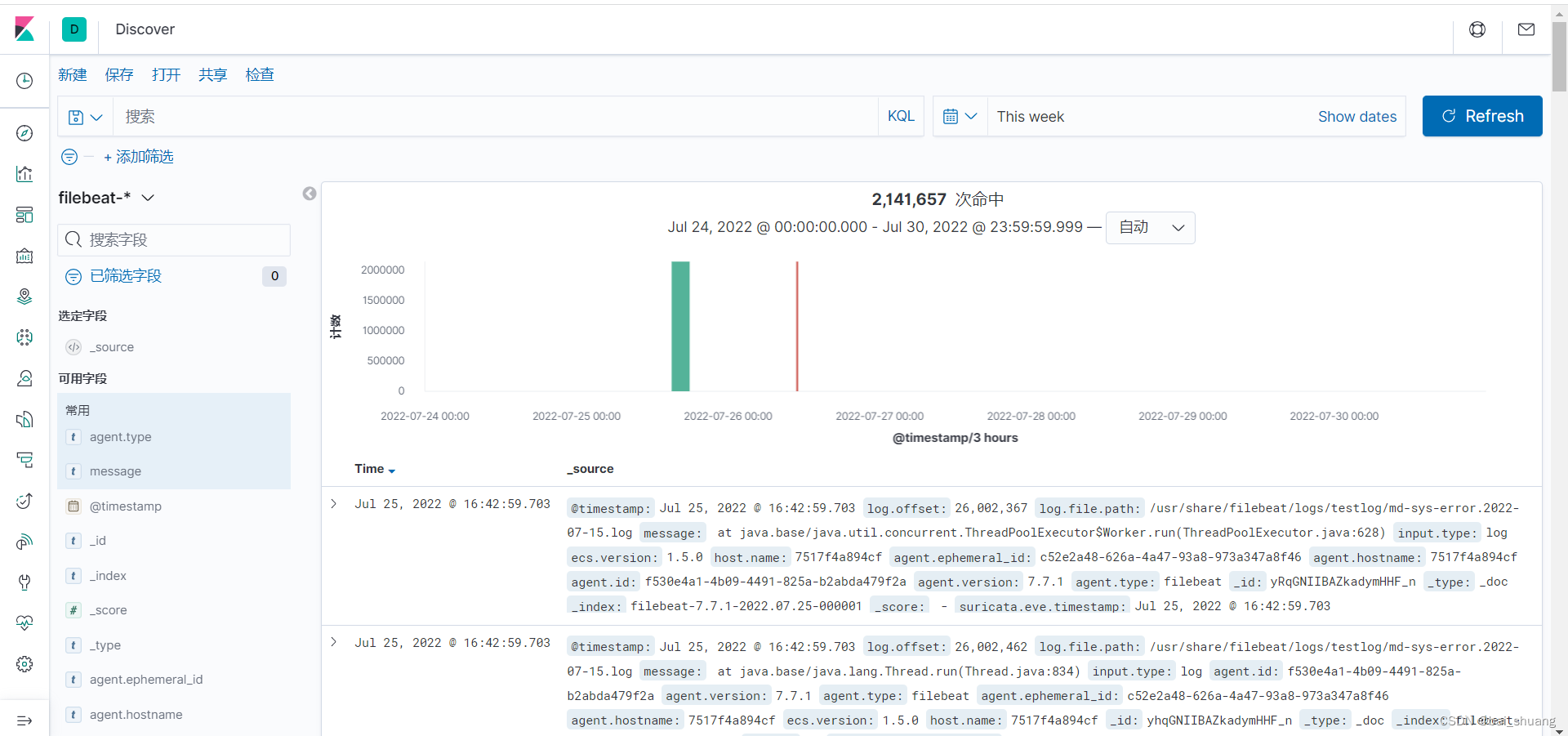
可以通过搜索或者日期筛选,字段筛选,等等各种操作查看你需要的日志信息。
或者可以在 日志目录下 查看日志
搭建完成
5、总结
通过上面的搭建,相信读者对日志EFK也有了了解,在体验各种爽到爆的搜索聚合,统计分析功能相信你会爱上kibana。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)