【深入浅出flink】第14篇:kafka分区数与flink算子并行度导致Watermark不触发问题,大多数大数据开发者都会遇到的问题
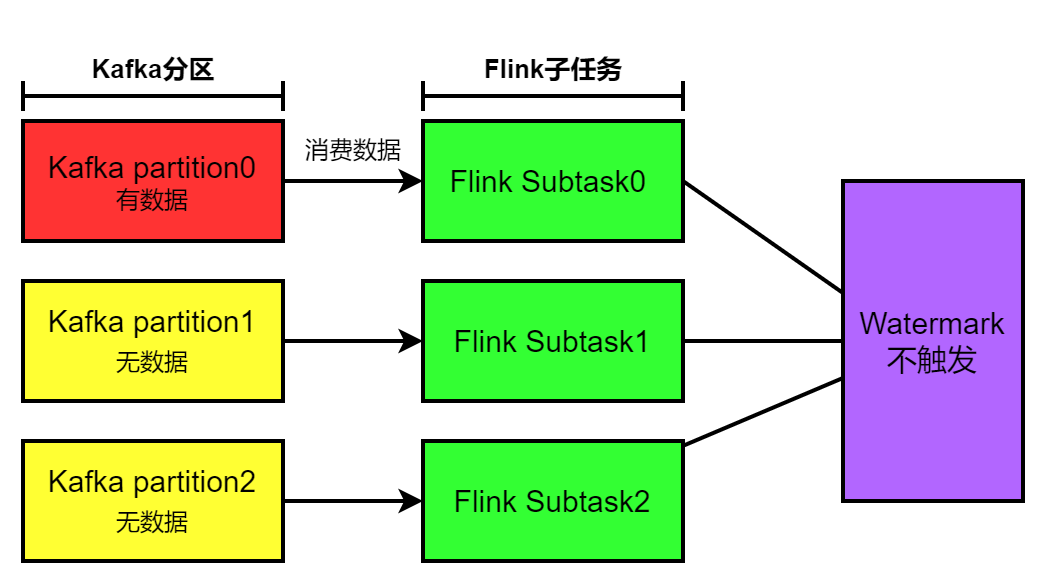
场景描述:flink消费分区有三个,其中第一个分区有数据,另外两个分区无数据。消费kafka分区的flink算子并行度为3,三个子任务分别消费kafka的分区,导致Watermark机制失效。
大家好,我是雷恩Layne,这是《深入浅出flink》系列的第十四篇文章,希望能对您有所收获O(∩_∩)O
场景描述:flink消费分区有三个,其中第一个分区有数据,另外两个分区无数据。消费kafka分区的flink算子并行度为3,三个子任务分别消费kafka的分区,导致Watermark机制失效。场景示意图如下:

模拟场景
场景复现
现在我们模拟事故的场景:
(1)传感器Beans类
// 传感器温度读数的数据类型
public class SensorReading {
// 属性:id,时间戳,温度值
private String id;
private Long timestamp;
private Double temperature;
//必须有空参的构造方法
public SensorReading() {
}
public SensorReading(String id, Long timestamp, Double temperature) {
this.id = id;
this.timestamp = timestamp;
this.temperature = temperature;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getTimestamp() {
return timestamp;
}
public void setTimestamp(Long timestamp) {
this.timestamp = timestamp;
}
public Double getTemperature() {
return temperature;
}
public void setTemperature(Double temperature) {
this.temperature = temperature;
}
@Override
public String toString() {
return "SensorReading{" +
"id='" + id + '\'' +
", timestamp=" + timestamp +
", temperature=" + temperature +
'}';
}
}
(2)业务逻辑代码
public class MyTest {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置Watermark生成周期为100ms
env.getConfig().setAutoWatermarkInterval(100);
//kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "wxler1:9092");
properties.setProperty("group.id", "sensorConsumerGroup");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
//从kafka获取数据
DataStream<String> kafkaSource = env.addSource(new FlinkKafkaConsumer011<String>("sensorTest", new SimpleStringSchema(), properties));
//将读取的数据转化为传感器Bean
DataStream<SensorReading> sensorDataStream = kafkaSource.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String value) throws Exception {
String[] fields=value.split(",");
SensorReading sensor=new SensorReading(fields[0],Long.parseLong(fields[1]),Double.parseDouble(fields[2]));
return sensor;
}
});
//加上Watermark机制,延迟时长设为2s
DataStream<SensorReading> sensorDataStreamWaterMark = sensorDataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
});
//基于事件时间的开窗聚合,统计15s内温度的最小值
SingleOutputStreamOperator<SensorReading> minTempStream = sensorDataStreamWaterMark.keyBy("id")
.timeWindow(Time.seconds(15)).minBy("temperature");
minTempStream.print("minTemp");
env.execute();
}
}
(3)使用kafka命令在集群中创建一个有3个分区的topic
kafka-topics.sh --create --topic sensorTest --partitions 3 --replication-factor 1 --bootstrap-server wxler1:9092
(4)自定义kafka生产者往topic的指定分区中发送30条数据:
public class Proceducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "wxler1:9092");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
long timeStamp=1547718209L;
double temperature=55.0;
for (int i = 1; i <= 30; i++) {
timeStamp++;
temperature--;
String msg="sensor_1,"+timeStamp+","+temperature; //数据格式:"sensor_1,1547718210,35.0"
//key相同会发往同一分区
producer.send(new ProducerRecord<String, String>("sensorTest", "myKey", msg));
}
producer.close();
}
}
(5)查看topic中每个分区消费了多少offset
kafka-run-class.sh kafka.tools.GetOffsetShell --topic sensorTest --broker-list wxler1:9092
输出如下:
sensorTest:0:30
sensorTest:1:0
sensorTest:2:0
现象描述
程序中我们设置时间滚动窗口大小为15s,Watermark延迟时长为2s,kafka生产者发送了30条数据,这30条数据最小的时间戳为1547718210(长度10位,单位是秒),最大的时间戳为1547718239,本应触发Watermark机制,结果却没有任何输出。
分析原因
当一个DataStream添加Watermark后,它每收到一个数据,都会获取数据的时间戳,计算Watermark,计算公式一般为:
Watermark = timeStamp - 延迟时长
然后判断计算得到的Watermark是否大于当前的Watermark,如果大于,则将当前的Watermark更新计算为得到的Watermark,否则不更新,从而得到自己任务的Watermark。
接下来,该任务会将它的Watermark通过广播的形式将Watermark发送给所有下游任务。下游任务收到所有来自上游的Watermark,将最小的Watermark作为自己任务的Watermark。当再次收到上游任务的Watermark后,会判断现在所有上游任务最小的Watermark是否大于自己任务的Watermark,如果大于,则进行更新,否则,不更新。
总而言之,上游任务根据获取数据的时间戳更新Watermark,下游任务根据所有上游任务最小的Watermark更新Watermark,更新的准则都是递增的,即只有大于当前任务的Watermark才更新。
现在知道了Watermark什么时候更新,那么我们就来分析一下吧。
上面代码中,Flink source用到了FlinkKafkaConsumer011,如果我们没有指定KafkaPartitioner的话,会通过FixedPartitioner来给出默认的partitioner方法:
public int partition(T record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
Preconditions.checkArgument(partitions != null && partitions.length > 0, "Partitions of the target topic is empty.");
return partitions[this.parallelInstanceId % partitions.length];
}
parallelInstanceId代表着Flink consumer程序的并行度ID,我们在程序中设置的并行度是3,所以并行度ID是[0,1,2],partitions.length代表kafka的分区数,我们环境中topic的分区数是3,所以partitions.length=3。
Flink partition的规则,就是Flink程序的并行度ID 对 kafka分区数取余,所有每个Task消费一个Partition中的数据。
然后我们通过kafka命令发现,有两个topic分区是没有数据的,只有一个分区有数据,会导致只有一个任务能够消费到数据。另外,由于我们通过env.setParallelism(3)给程序设置的并行度为3,可以看到程序的逻辑执行图如下:

左侧为上游任务,右侧为下游任务,上游任务通过Bean的id的hash值进行重分区。
我们通过一张图来看看上下游任务Watermark的传递情况:

上游子任务subTask1广播的Watermark是计算得到的,而subTask2和subTask2广播的Watermark是默认初始值即Long.MIN_VALUE(一般赋值赋成Long.MIN_VALUE/2,这里我们就当成Long.MIN_VALUE了)。因为下游子任务是通过获取所有上游任务最小的Watermark当做自己任务的Watermark,这样会导致每次获取的最小的Watermark都是Long.MIN_VALUE(这种情况下可以任务没有Watermark),就永远无法触发Watermark机制了。
我们也可以看看下游任务是否有Watermark。
将上面的程序打包上传到Flink集群上,然后执行自定义的kafka生产者发送30条数据,查看下游任务是否有Watermark,如下图所示:

可以看到,生产者发送完数据后,下游任务都没有Watermark(Watermark是Long.MIN_VALUE就代表没有Watermark)。
解决办法
那怎么解决这个问题呢?
有两种方法:
(1)将添加Watermark的datastream和其上游datastream设置不一样的并行度,如下:
//map的datastream的并行度为3
DataStream<SensorReading> sensorDataStream = kafkaSource.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String value) throws Exception {
String[] fields=value.split(",");
SensorReading sensor=new SensorReading(fields[0],Long.parseLong(fields[1]),Double.parseDouble(fields[2]));
return sensor;
}
});
//将添加Watermark的datastream的并行度设置为2
DataStream<SensorReading> sensorDataStreamWaterMark = sensorDataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTimestamp() * 1000L;
}
}).setParallelism(2);
这样,上游任务和下游任务之间会产生shuffle,默认是通过reabancle方式传递数据,当数据传递到带有Watermark的datastream时,它的每一个子任务都会有数据,所以也都会有Watermark,这样再广播给后面的任务,就不会出现Long.MIN_VALUE的Watermark了。
(2)将添加Watermark的datastream的上游datastream通过rebancle重分区
DataStream<SensorReading> sensorDataStream = kafkaSource.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String value) throws Exception {
String[] fields=value.split(",");
SensorReading sensor=new SensorReading(fields[0],Long.parseLong(fields[1]),Double.parseDouble(fields[2]));
return sensor;
}
}).rebalance();
这种方式本质是和上面的方式一样,它们的本质都是让添加Watermark的datastream的所有子任务都有数据获取。
将代码修改后,我们再次打包上传到Flink集群,代码逻辑执行图如下:

执行自定义的kafka生产者发送30条数据,查看下游任务是否有Watermark,如下图所示:

可以看到,这样下游的任务就有Watermark了,就可以通过Watermark机制正常触发计算了。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 1
1- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)