(六)Hadoop实现简单的日志分析
1)创建Maven项目2)引入依赖3)编写Hadoop 日志分析相关Job代码4)导出jar包5)上传到Hadoop 集群6)编写Hadoop jar包执行jar包7)手动执行验证8)使用后台系统远程手动实现分析9)使用定时任务实现定时分析...
内容简介
数据可视化课程设计上课案例项目、使用简易商城项目产生用户访问日志,使用nginx记录访问日志、使用Flume +kafka完成日志采集到HDFS、使用Spark 完成日志离线分析、使用Sqoop将分析结果抽取到MySQL,最终使用SSM后端项目完成数据可视化展示。
一、Hadoop分布式集群安装
二 、Nginx安装配置、部署前端项目
三 、MySQL安装
四 、Tomcat安装、部署后端项目
五 、Flume安装、配置、实现日志定时复制、采集
六 、Hadoop实现简单的日志分析
七 、Kafka集群安装配置、Flume整合Kafka实现日志采集
八 、Spark集群安装、配置
九 、使用Spark进行日志分析
十 、Sqoop安装配置、抽取分析结果到MySQL数据库
十 一、使用Echarts展示分析结果
Hadoop实现简易离线日志分析
1)创建Maven项目
2)引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ShopLogAnalysis</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.2</version>
</dependency>
</dependencies>
</project>
3)编写Hadoop 日志分析相关Job代码
编写Mapper代码 LogMapper.java
package com.niit;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @program: ShopLogAnalysis
* @description:
* @author: hanliang
* @create: 2021-01-09 22:27
**/
// LongWritable, Text Map阶段的输入的数据的key的类型以及 Value类型
// Text, IntWritable Map阶段的输出的数据的key的类型以及 Value类型
public class LogMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
// 按指定模式在字符串查找
String pattern = "=[0-9a-z]*";
// 创建 Pattern 对象
Pattern r = Pattern.compile(pattern);
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//
String data = value.toString();
// 现在创建 matcher 对象
Matcher m = r.matcher(data);
if (m.find()) {
String idStr = m.group(0);
String id = idStr.substring(1);
//
context.write(new Text(id),new IntWritable(1));
}
}
}
编写Reducer代码 LogReducer.java
package com.niit;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @program: ShopLogAnalysis
* @description:
* @author: hanliang
* @create: 2021-01-09 22:29
**/
public class LogReducer extends Reducer<Text, IntWritable,Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable v: values) {
sum += v.get();
}
context.write(key,new IntWritable(sum));
}
}
编写Job类代码 LogJob.java
package com.niit;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @program: ShopLogAnalysis
* @description:
* @author: hanliang
* @create: 2021-01-09 22:30
**/
public class LogJob {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(LogJob.class);
job.setMapperClass(LogMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(LogReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean completion = job.waitForCompletion(true);
}
}
4)导出jar包
file–>Project Structure
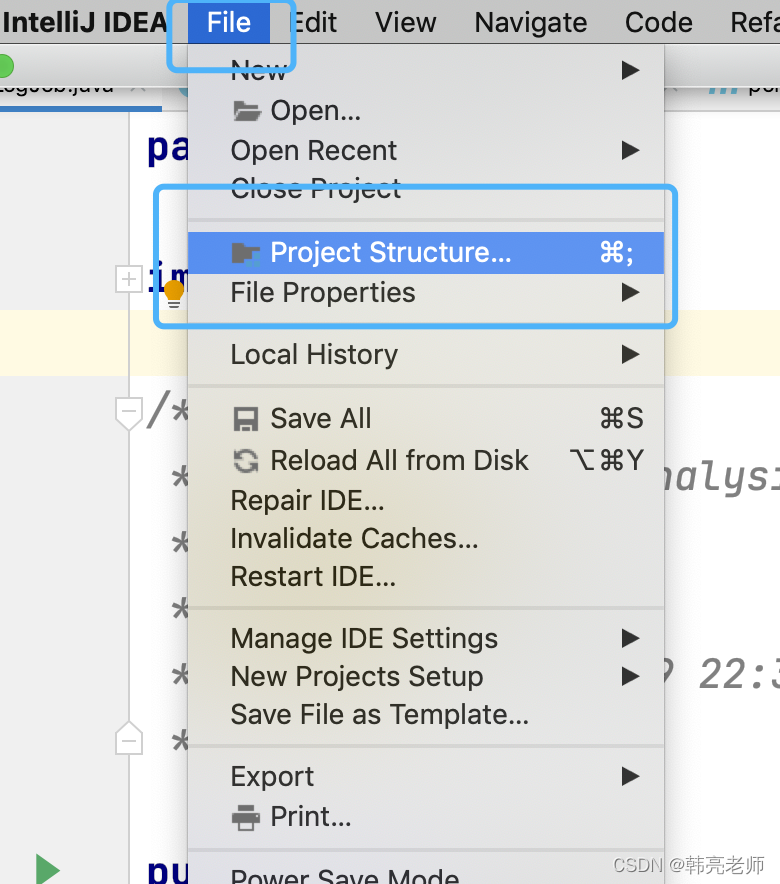
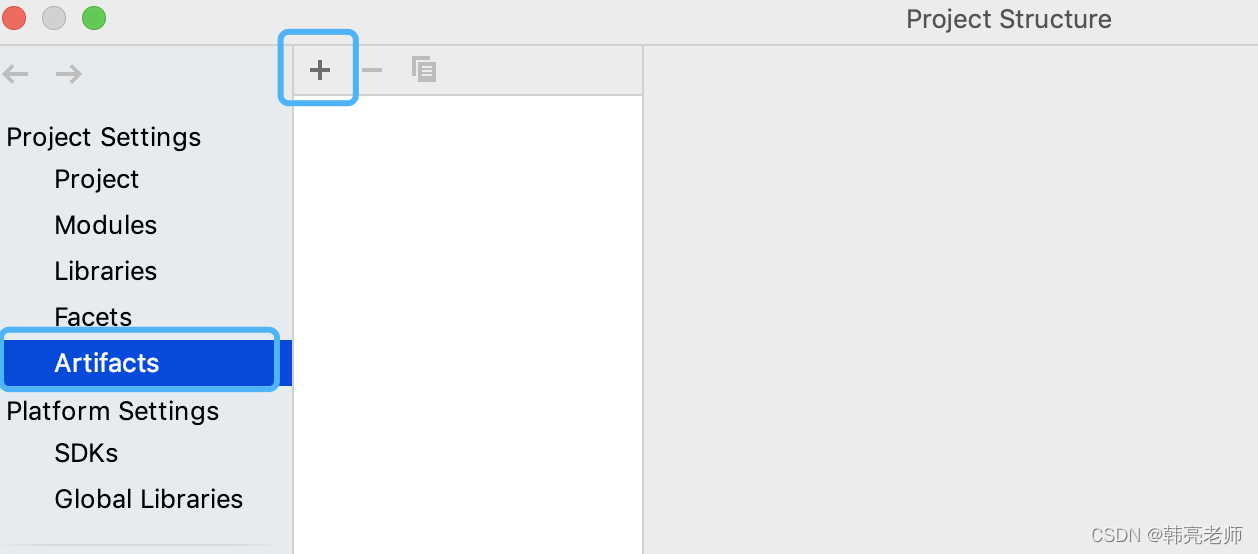
artifacts —>选择➕
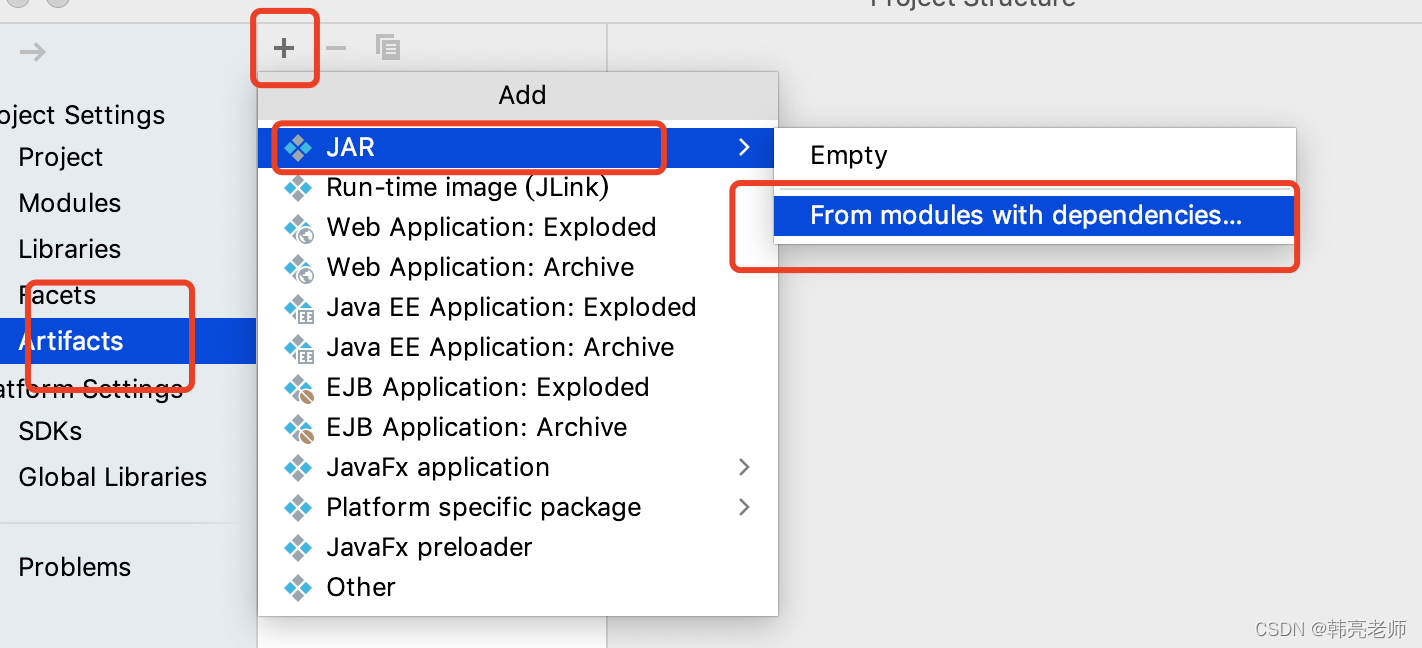
选择主类
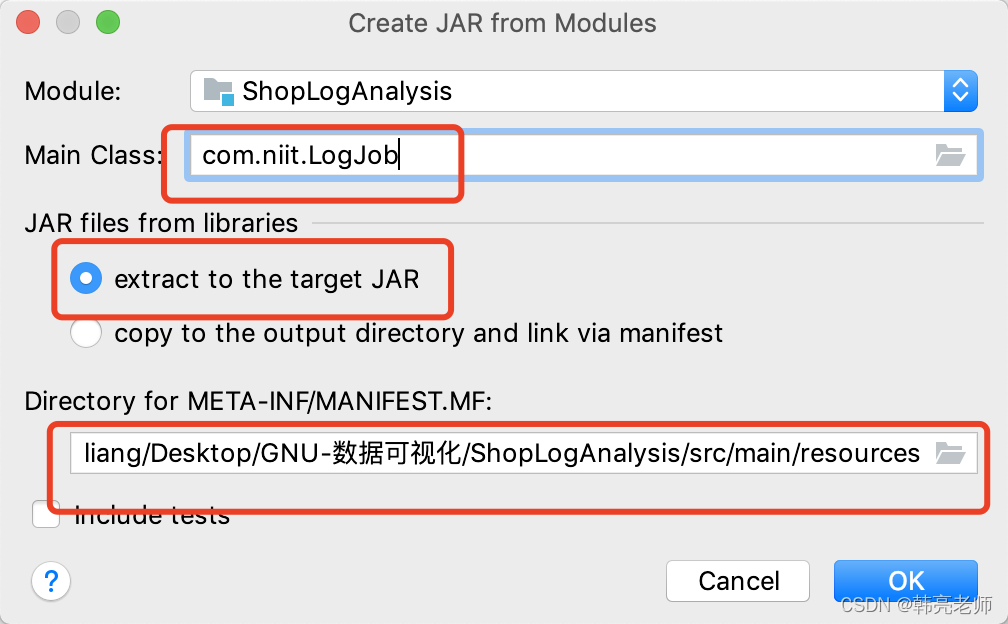
然后选择 apply,选择OK
在build菜单选择 build artifacts
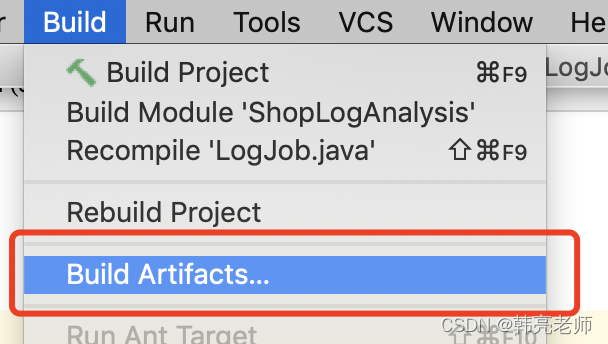
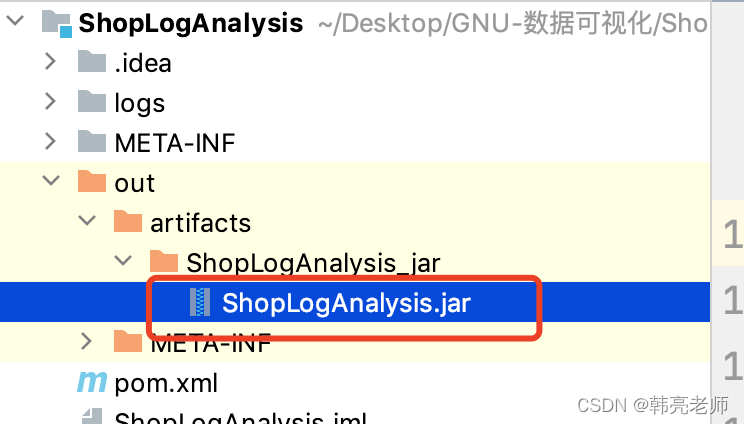
成功之后再项目目录中生成 out文件夹,里面有打好的jar包
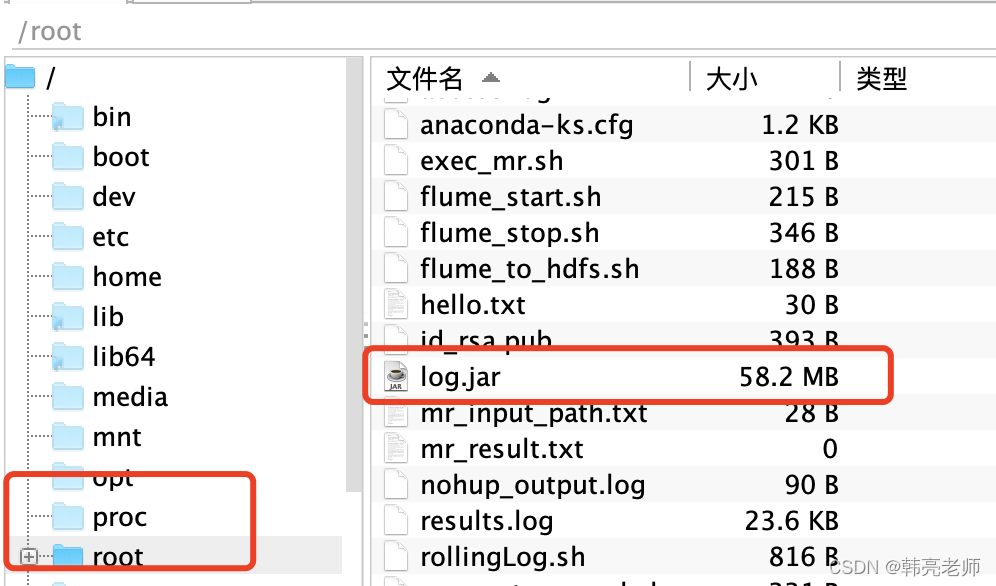
5)上传到Hadoop 集群 (我这里上传到 master节点的 /root目录,并且改名为log.jar)
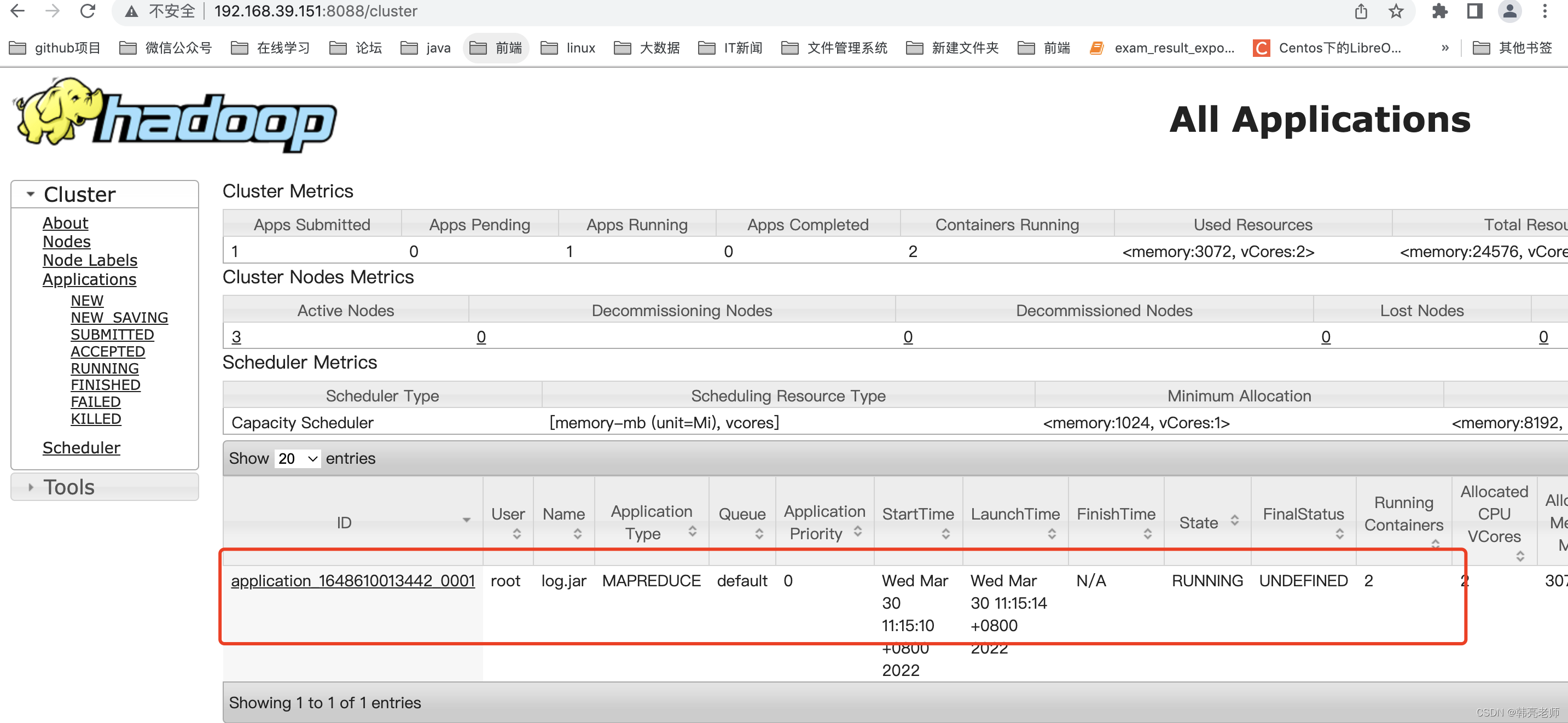
6)手动使用hadoop jar命令执行jar包验证代码的正确性
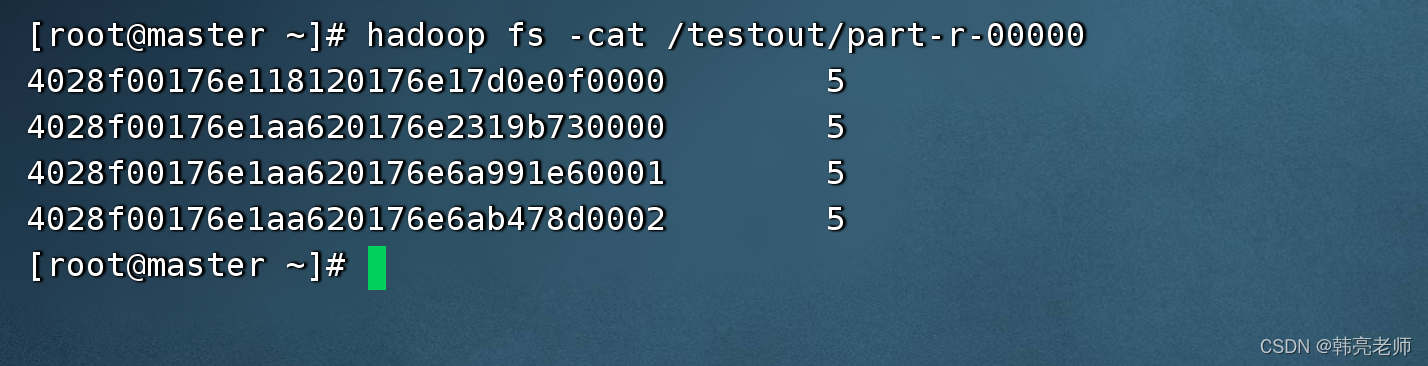
hadoop jar log.jar /flumeLogs/22-03-22/08/32/20 /testout
命令执行过程图:

执行过程中打开集群监控界面,观察job的执行过程:
执行完成之后,使用hdfs shell确认执行结果:
7)编写执行日志分析 jar包的脚本
文件位置:/root/exec_mr.sh
#!/bin/bash
#执行MapReduce程序
dataformat=`date +%Y-%m-%d-%H-%M-%S`
/mnt/training/hadoop-3.2.2/bin/hadoop jar log.jar $(cat mr_input_path.txt) /output/result/$dataformat
/mnt/training/hadoop-3.2.2/bin/hdfs dfs -cat /output/result/$dataformat/part-r-00000 > mr_result.txt
echo $(cat mr_result.txt)
PS:
- mr_input_path.txt 的内容,将有后台系统从界面输入一个日志路径,程序写入
2)mr_result.txt 文件保存脚本执行的结果
8)使用后台系统远程手动实现分析
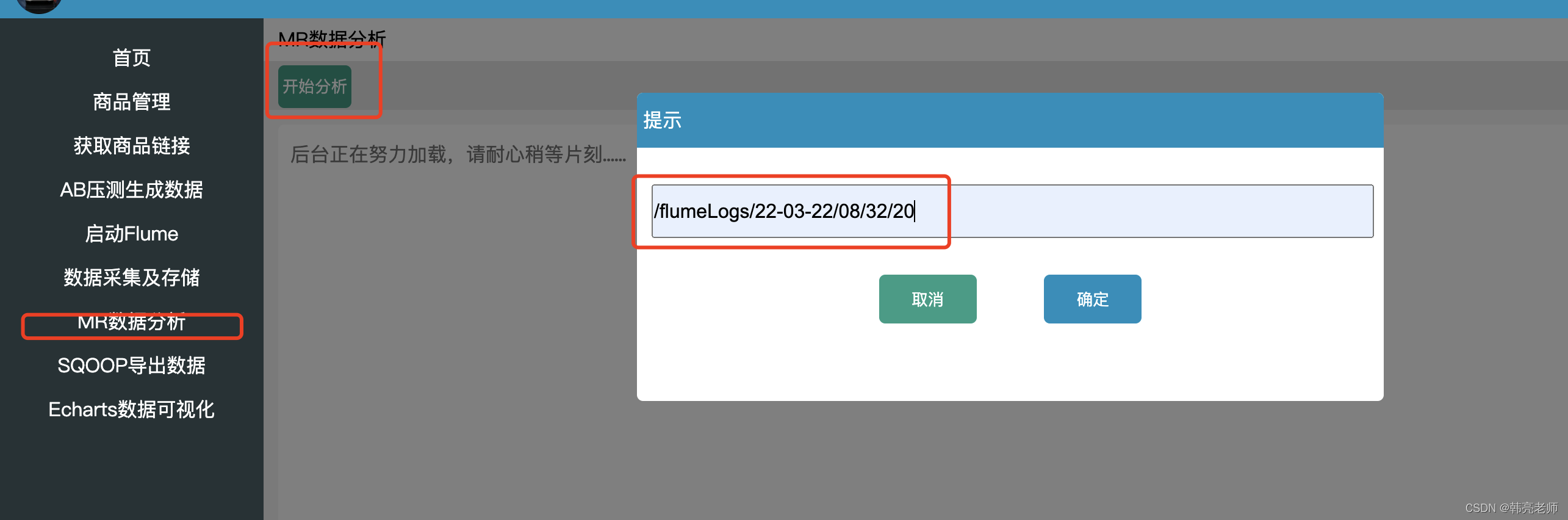
单击确定,远程执行 /root/exec_mr.sh脚本
后代的程序代码:
/**
* @category 数据的分析即执行MapReduce程序
* @param request
* @param response
* @return
*/
@RequestMapping("goods/dataAnalysis")
public @ResponseBody String dataAnalysis(@RequestParam Map<String, String> param, HttpServletRequest request, HttpServletResponse response) {
//0、获取需要的分析的是HDFS哪一个目录下的数据
String path = param.get("path");
//1、拿到前端输入的HDFS的路径写入到Linux下mr_input_path.txt文件中
FileWriter writer;
try {
writer = new FileWriter("/root/mr_input_path.txt");
writer.write(path);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
// 3、使用SSH2登录远程Linux服务器,执行shell脚本
String execResultStr = RemoteExecuteCommand.getInstance().executeSuccess("sh /root/exec_mr.sh");
// 4、构造返回前端页面的map对象
Map<String, String> map = new HashMap<String, String>();
if (!"".equals(execResultStr)) {
map.put("message", "数据分析成功~");
map.put("status", "1");
map.put("data", execResultStr);
return JSON.toJSONString(map);
}
map.put("message", "数据分析失败~");
map.put("status", "0");
map.put("data", "数据分析失败~");
return JSON.toJSONString(map);
}

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)