ELK部署
ELK部署
无聊发发最近玩的ELK
elasticsearch
首先部署elasticsearch,目前为止我用的是比较新的版本(7.1.0)
官网下载elasticsearch,解压运行
看下配置问题,默认是./config/elasticsearch.yml,仔细看看里面有个日志目录和数据目录需要改一下,和自己添加目录。
新建用户,切换用户。
运行命令
./bin/elasticsearch
./bin/elasticsearch -d # 后台运行如果在centos中运行,会遇到各种跟系统配置冲突的问题。如vm.max_map_count,改系统文件就行了,不用重启。
启动好了,记得测试下
访问 127.0.0.1:9200,应该会出现如下结果,如果不是,应该就是没启动成功,或者其他问题了

kibana
版本和elasticsearch版本一致,不多介绍,目前没用到多少。默认端口5601
logstash
版本和elasticsearch版本一致。主要进行数据分词,在elasticsearch添加索引,给elasticsearch输入数据。logstash插件很多,但是运行时占用内存高,一般不部署在每个机器上直接监听日志文件输出。
运行命令:先启动elasticsearch
./bin/logstash -f ./config/logstash_test.conf指定配置文件./config/lostash_test.conf运行,配置内容主要有下面三个
# 输入
input {
redis {
host => "127.0.0.1"
port => 6379
# password => "123456" # redis密码,没有密码就不需要这个参数
key => "apilog" #这里的key值和filebeat配置文件中output.redis的key值保持一致
data_type => "list"
db =>1
}
}
# 过滤,在这里进行分词,[fields][filetype]和filebeat中的一致
filter {
if [fields][filetype] == "apiweb_producelog" {
json {
source => "message"
remove_field => ["_type","beat","offset","tags","prospector"] #移除字段,不需要采集
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] #匹配timestamp字段
target => "@timestamp" #将匹配到的数据写到@timestamp字段中
}
}
}
# 输出,最后一个是加上时间,按日期对日志进行分开收集
output {
# 输出到 Elasticsearch,根据filebeat中配置的filetype,在ES中建立不同的索引
if [fields][filetype] == "apiweb_producelog" {
elasticsearch {
# Elasticsearch 地址
hosts => ["localhost:9200"]
# Elasticsearch 索引名
index => "producelog"
}
} else if [fields][filetype] == "apiweb_supplierlog" {
elasticsearch {
hosts => ["localhost:9200"]
index => "supplierlog"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
index => "apilog-%{+YYYY.MM.dd}"
}
}
}
filebeats
简单的收集器,具有占用内存小,方便部署等优势,因此作为部署在每台服务器上的日志收集器。
将filebeats收集到的数据输出到redis中,当然也可输出到kafka等MQ中,进行缓冲和数据容灾机制处理。
运行命令:
.\filebeat -e -c filebeat.yml同样是指定filebeat.yml配置文件进行运行。
filebeat.yml如下
# ============================== Filebeat 输入配置==============================
filebeat.inputs:
- type: log
enabled: true
# 每 5 秒检测一次文件是否有新的一行内容需要读取
backoff: "5s"
# 是否从文件末尾开始读取
tail_files: false
# 需要收集的数据所在的目录
paths:
- /Log/2021/*.log
# 自定义字段,在logstash中会根据该字段来在ES中建立不同的索引
fields:
filetype: apiweb_producelog
# logstash配置文件中的[fields][filetype]一致
# 这里是收集的第二个数据,多个依次往下添加
- type: log
enabled: true
backoff: "5s"
tail_files: false
paths:
- /home/openweb/Logs/Warn/*.log
fields:
filetype: apiweb_supplierlog
# ============================== Filebeat modules ==============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
# ============================== Filebeat 输出配置====================
output.redis:
enabled: true
# redis地址
hosts: ["192.168.1.103:6379"]
# redis密码,没有密码则不添加该配置项
password: 123456
# 数据存储到redis的key值
key: apilog
# 数据存储到redis的第几个库
db: 1
# 数据存储类型
datatype: list
# ================================= Processors =================================
# 猜测和运行环境有关,没有测试过
#processors:
# - add_host_metadata:
# when.not.contains.tags: forwarded
# - add_cloud_metadata: ~
# - add_docker_metadata: ~
# - add_kubernetes_metadata: ~因此,整体部署架构如下:
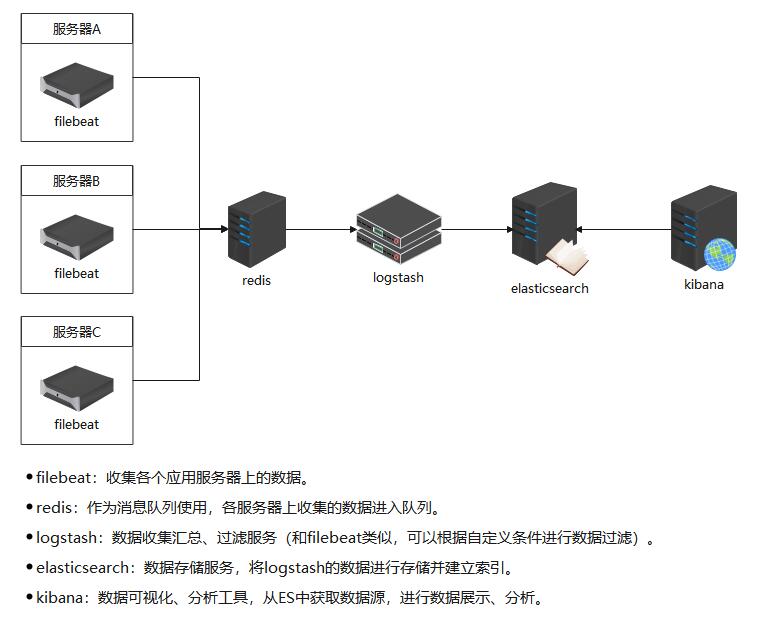
盗的图,参考别人博客部署的,并亲自实践成功的一个ELK部署。
参考博客:filebeat+redis+elk构建多服务器日志收集系统配置文件说明 - JcongJason - 博客园

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)