Kafka中使用自带镜像迁移工具(Mirror Maker)进行数据迁移
Kafka中使用自带镜像迁移工具(Mirror Maker)进行数据迁移简述:MirrorMaker为Kafka自带的数据迁移工具,可以利用此种方式直接进行kafka集群之间的数据迁移;减少中间组件的使用。(例如通过Flink以Kafka为Source,并且以Kafka作为Sink进行数据传输,当然是基于不对数据进行任何操作的前提下)原理:通过Consumer从旧的Kafka集群中消费数据,然后通
1、简述:
MirrorMaker为Kafka自带的数据迁移工具,可以利用此种方式直接进行kafka集群之间的数据迁移;减少中间组件的使用。(例如通过Flink以Kafka为Source,并且以Kafka作为Sink进行数据传输,当然是基于不对数据进行任何操作的前提下)
2、原理:
通过Consumer从旧的Kafka集群中消费数据,然后通过Producer将数据生产在目标kafka集群中,实现数据同步备份;如图所示:

如上图所示:使用Kafka在3.0之前需要zookeeper为辅助,所有需要启动各集群上的zookeeper节点
3、具体操作命令如下:
-
分别启动zookeeper和kafka集群 (启动命令自查)
-
在kafka集群上bin目录下进行MirrorMaker工具的启动(两种启动命令的方式) 启动成功后会一直等待(说明管道建立成功)
bin/kafka-mirror-maker.sh --consumer.config consumer.properties --producer.config producer.properties --whitelist="消费的主题名"bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.config --producer.config producer.config --whitelist="消费的主题名"
-
参数配置
consumer.config: 配置旧kafka的集群信息。例如zookeeper及bootstrap地址 注意:这里的端口是自己机器上的端口信息

此外如果想要消费topic中已经存在的历史数据,只需要在consumer.config配置文件中指定偏移量位*最早**即可
auto.offset.reset=earliest
**–producer.config:**配置新kafka集群,也就是说数据最终发送的目标机器
bootstrap.servers=目标机器IP : 2181
- 其他参数配置如下:

测试是否成功可以在旧的kafka集群上启动一个producer,向上述whitelist中所指定的topic输入消息;在新的kafka上启动consumer消费相同topic信息
-
可能报错情况:

上述情况是由于找不到JAVA环境变量所导致。只需更改java环境变量为自己机器的正确存放位置即可
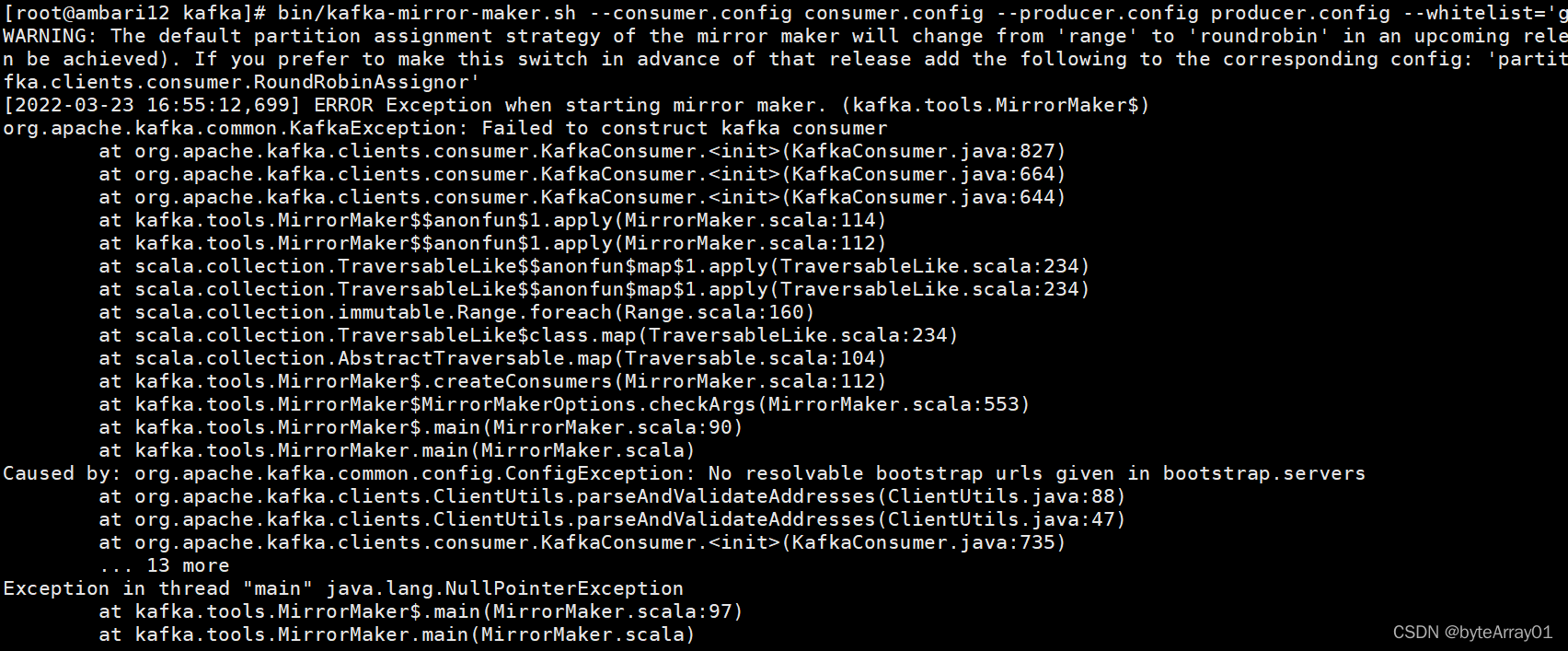
上述情况是因为自己配置consumer.config文件解析不到端口导致,需要仔细检查消费者和生产者的配置文件(即–consumer.config 后自己自定义配置的文件信息)
文末最后提醒大家使用MirrorMaker工具进行镜像同步时,建议在新的kafka集群节点进行命令的启动,这样可以避免因为网络问题造成数据丢失问题。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)