使用es实现个人博客的模糊搜索,搜索推荐
使用ElasticSearch完成文档的模糊搜索,高亮显示,搜索推荐等功能
目录
应用博客
需求
考虑如何将博客系统接入es技术。
1.如何将数据库的数据同步到es去,处理好mapping
2.做模糊搜索+智能推荐的技术选型
3.所选技术的优缺点
4.高亮显示(选择命中的标题,概要以及它的文章内容,节选50个字符)
5.JAVA_API的使用
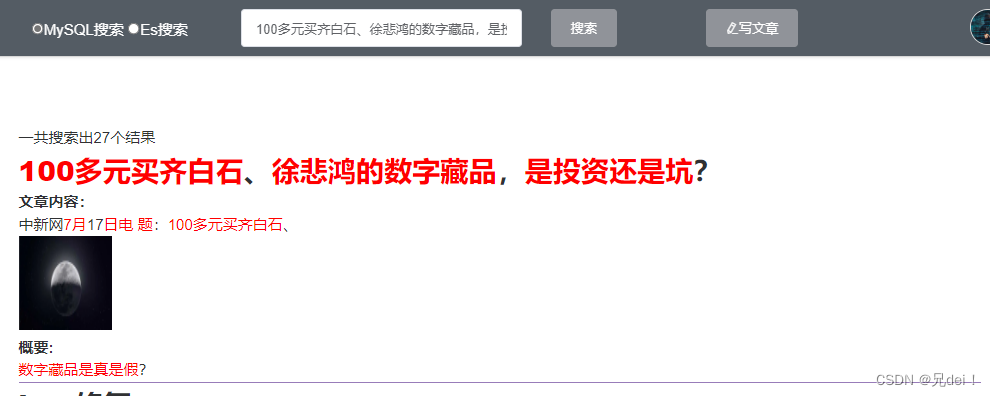
实现效果
提供两种查询方式——es和Mysql
以下为es,有搜索推荐(通过前缀判断),有多字段(文章标题,概要,内容)以及模糊查询(智能纠错等)


mysql查询: 通过like语句

canal完成数据同步(从mysql到es)
插入数据


canal这边完成响应:

使用es搜索已经能搜索到了

设计
1.如何将数据库的数据同步到es去,处理好mapping
1.1 使用Logstash完成全量同步;使用Canal完成增量同步
1.2 分词器选用: ik;过滤器:小写过滤
1.3 需要同步进es的数据库表: 文章表,标签,分类表
2.做模糊搜索+智能推荐的技术选型
2.1 模糊搜索使用:fuzzy
2.2 智能推荐使用:context_suggester/complate_suggester
3.所选技术的优缺点
3.1 fuzzy模糊搜索的优缺点需要与prefix以及wildcard相比较。
首先,prefix的性能很差,没有缓存,并且只支持前缀模糊,功能较差;而wildcard通配符的实用性并不强,智能纠错级别并不需要太高,综合来看fuzzy功能不差,性能也不错。
[fuzziness设置为1就好,设为2的话错误率就太高了]
3.2 context_suggester是基于completion suggester的一种智能推荐方案,采用了completion这种es的特有类型,基于内存性能高。可以满足前缀推荐,并且还可以通过分类以及标签来做推荐,功能更加强大。缺点就是在插入数据的时候需要考虑input输入值,难度比completion suggester高。
[(为了方便)可以通过标题设置Input值,分类和标签直接插入suggest的子字段里,boost(权重)可以不考虑]
4.高亮显示(选择命中的标题,概要以及它的文章内容,节选50个字符)
遇到的问题:一开始一直无法解决这个问题,就是高亮标签传到前台已经被当成字符串显示出来

后面就是在finally块里面选择对应的标签进行处理就解决掉了。

5.JAVA_API的使用
5.1 导入对应es版本的依赖
5.2 在项目底下创建好es_service包
5.3 创建对应es索引的model类,操作类
6.canal同步数据细节
1.deployer
canal的服务端,需要做的配置:
进入deployer\conf\example,修改instance.properties
canal.instance.master.address=127.0.0.1:3306 #数据库连接地址
#数据库信息填写
canal.instance.dbUsername=root
canal.instance.dbPassword=root
canal.instance.connectionCharset = UTF-8
# table regex
canal.instance.filter.regex = .\*\\..\*2.adapter
2.1 进入根目录,修改application.yml
server:
port: 8081
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true
username: root
password: root
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7
hosts: http://127.0.0.1:9200
properties:
mode: rest #transport or rest
# # security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch #集群名字2.2 进入es7目录,创建对应数据库名字的配置文件
例如这里我想将数据库'test' 的数据同步到Es,那么就在这个文件下面创建test.yml
编写test.yml
dataSourceKey: defaultDS #源数据源的key,对应SrcDataSources中的值
destination: example #canal的instance
groupId: g1 #智慧同步对应groupId的数据
esMapping:
_index: my_table #es的索引名
_id: _id #es的id 不配置则必须配置下面的pk
upsert: true
#pk: id
sql: "select id as _id,name from my_table"
#sql语句编写--> id必须设置成_id
# objFields:
# _labels: array:;
etlCondition: "where a.c_time>={}"
commitBatch: 3000 #提交批大小
注意:
es里面必须含有这个索引,并且映射要和Mysql字段做好匹配
过程中踩到的坑:
1.安装目录含有中文。启动adapter直接闪退。
2.adapter下的application.yml里面,es对应的Ip没写好。这个地方没写好的话,数据库的数据更新时adapter后台会有反应,但是es收不到数据的
- name: es7
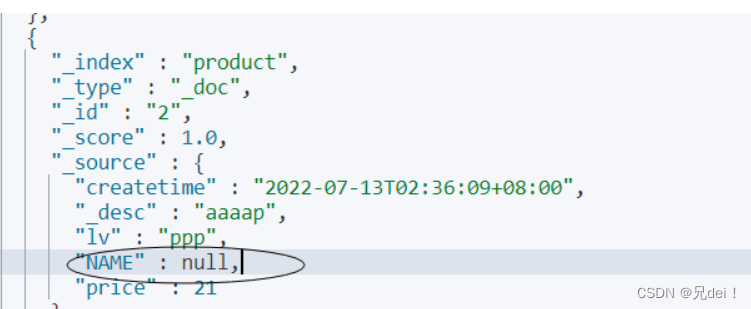
hosts: http://127.0.0.1:9200 #这里不加http://会报错 Illegal character in scheme name at index 03.测试缺字段索引可否
SELECT id AS id, createtime,desc,lv,NAME,price FROM product
mysql的表:

es的索引:

故意弄少了两个字段。
实验证明可行,es的索引字段里面不需要跟mysql保持数量上的一致,但是做匹配的时候会区分大小写,所以在es7文件夹里面的配置文件的sql语句编写要注意规范。
4.又一个坑点(多表如何同步)
尝试写成多个yml文件,指向同一索引?
看看sql映射说明:
sql支持多表关联自由组合, 但是有一定的限制: 1主表不能为子查询语句。 2只能使用left outer join即最左表一定要是主表。 3关联从表如果是子查询不能有多张表。 4主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容)。 5关联条件只允许主外键的'='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1。 6关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id其中的a.role_id 或者b.id必须出现在主select语句中。 Elastic Search的mapping 属性与sql的查询值要一一对应(不支持 select *), 比如: select a.id as _id, a.name, a.email as _email from user, 其中name将映射到es mapping的name field, _email将 映射到mapping的_email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射。
看完以上说明,我想着尝试一下Select主句里面加上我连接对象的id,发现成功了
sql: "SELECT DISTINCT ma.id AS _id,mab.id as mab_id,ma.comment_counts,
ma.create_date,ma.summary,ma.title,mab.content,
ma.view_counts,ma.weight,ma.summary_img
FROM ms_article ma
LEFT JOIN ms_article_body mab ON ma.body_id = mab.id"尝试把所有连接对象id加入到Select主句中:
sql: "SELECT DISTINCT ma.id AS _id,ma.comment_counts,
ma.create_date,ma.summary,ma.title,mab.id as mab_id,
ma.view_counts,ma.weight,msu.account,mc.id as mc_id,
mab.content ,mc.category_name ,mat.article_id as mat_id,
ma.summary_img,mt.tag_name,mat.tag_id as mat_tag_id,
msu.id as msu_id
FROM ms_article ma
LEFT JOIN ms_article_body mab ON ma.body_id = mab.id
LEFT JOIN ms_category mc ON mc.id=ma.category_id
LEFT JOIN ms_article_tag mat ON mat.article_id = ma.id
LEFT JOIN ms_tag mt ON mt.id=mat.tag_id
LEFT JOIN ms_sys_user msu ON ma.author_id= msu.id"这下不报错了。但是还是得测试多表插入数据是否能够正常更新
1.删除没问题。
2.修改没问题
3.插入一开始有问题,但是后面排查清楚之后发现,把查询字段全部加上或者把相应的字段加上就行。
例如说,ma.body_id = mab.id 里面 ma是我的主表,mab是子表,此时我放在select主句的应该是主表对应的body_id。所以我上面的那段Sql语句还是有点问题的,经过修改之后变成:
sql: "SELECT DISTINCT ma.id AS _id,ma.comment_counts,
ma.create_date,ma.summary,ma.title,ma.body_id,
ma.view_counts,ma.weight,msu.account,ma.category_id,
mab.content ,mc.category_name ,mat.article_id as mat_id,
ma.summary_img,mt.tag_name,mat.tag_id as mat_tag_id,
ma.author_id as mau_id,mt.id as mt_it
FROM ms_article ma
LEFT JOIN ms_article_body mab ON ma.body_id = mab.id
LEFT JOIN ms_category mc ON mc.id=ma.category_id
LEFT JOIN ms_article_tag mat ON mat.article_id = ma.id
LEFT JOIN ms_tag mt ON mt.id=mat.tag_id
LEFT JOIN ms_sys_user msu ON ma.author_id= msu.id"完成。
gitee仓库
制作不易,还请多多点赞+star~

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)