flink 出现反压场景, 异常场景造成Exceeded checkpoint tolerable failure threshold.
现象:flink 自定义写hdfs 的addsink 方法处理慢,出现了挤压现象;导致上游反压,后排查发现时 addsink 里面有一个解析rawtrace方法耗时很长, 同时RichSinkFunction 是和平行度一样的线程数, 导致出现了阻塞解决方案: 把解析rawtrace代码放在了keyby, map里,keyby是按照traceId, 将解析rawtrace 放在procesfunt
flink 出现反压场景,异常场景造成Exceeded checkpoint tolerable failure threshold.
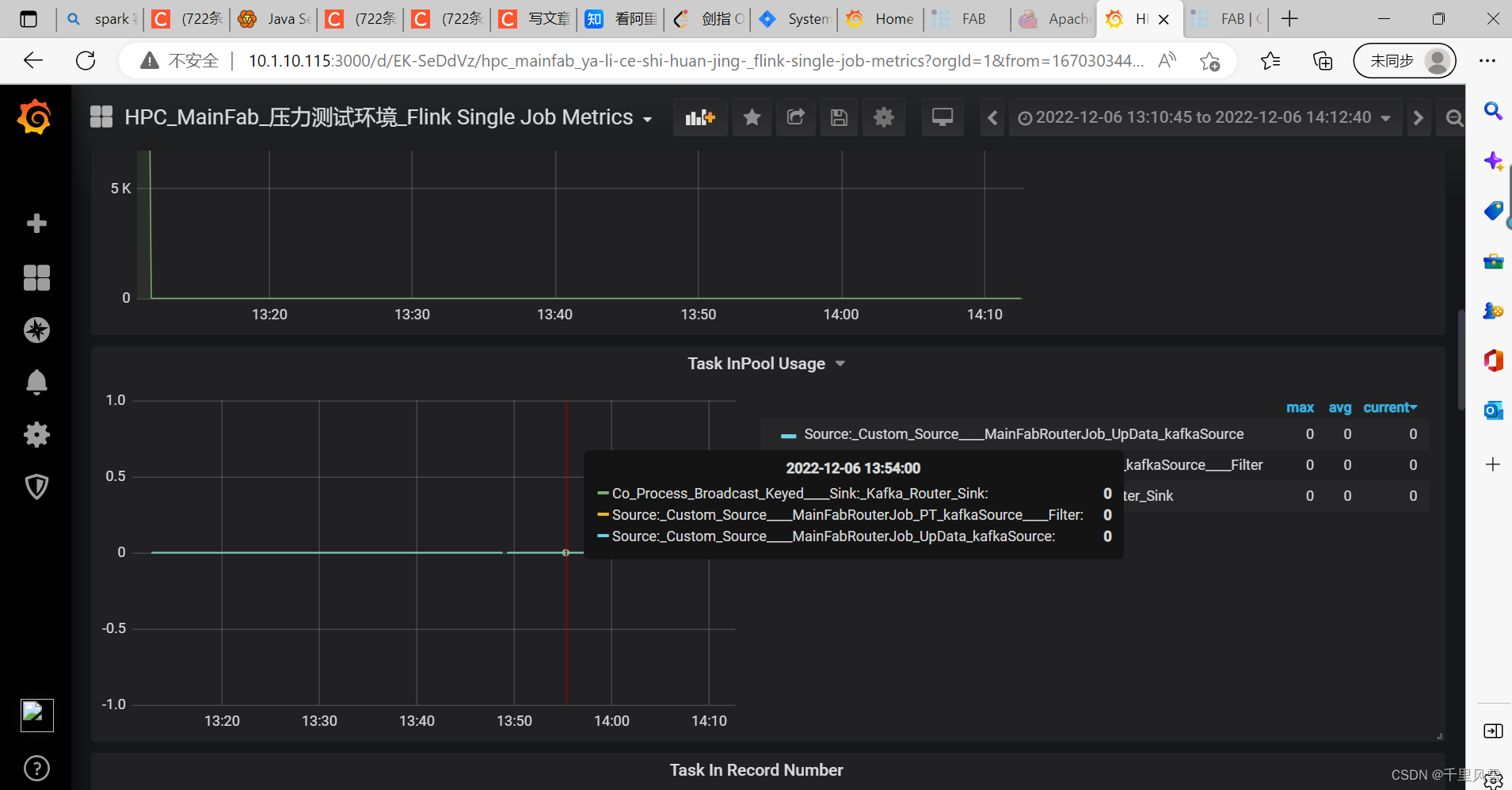
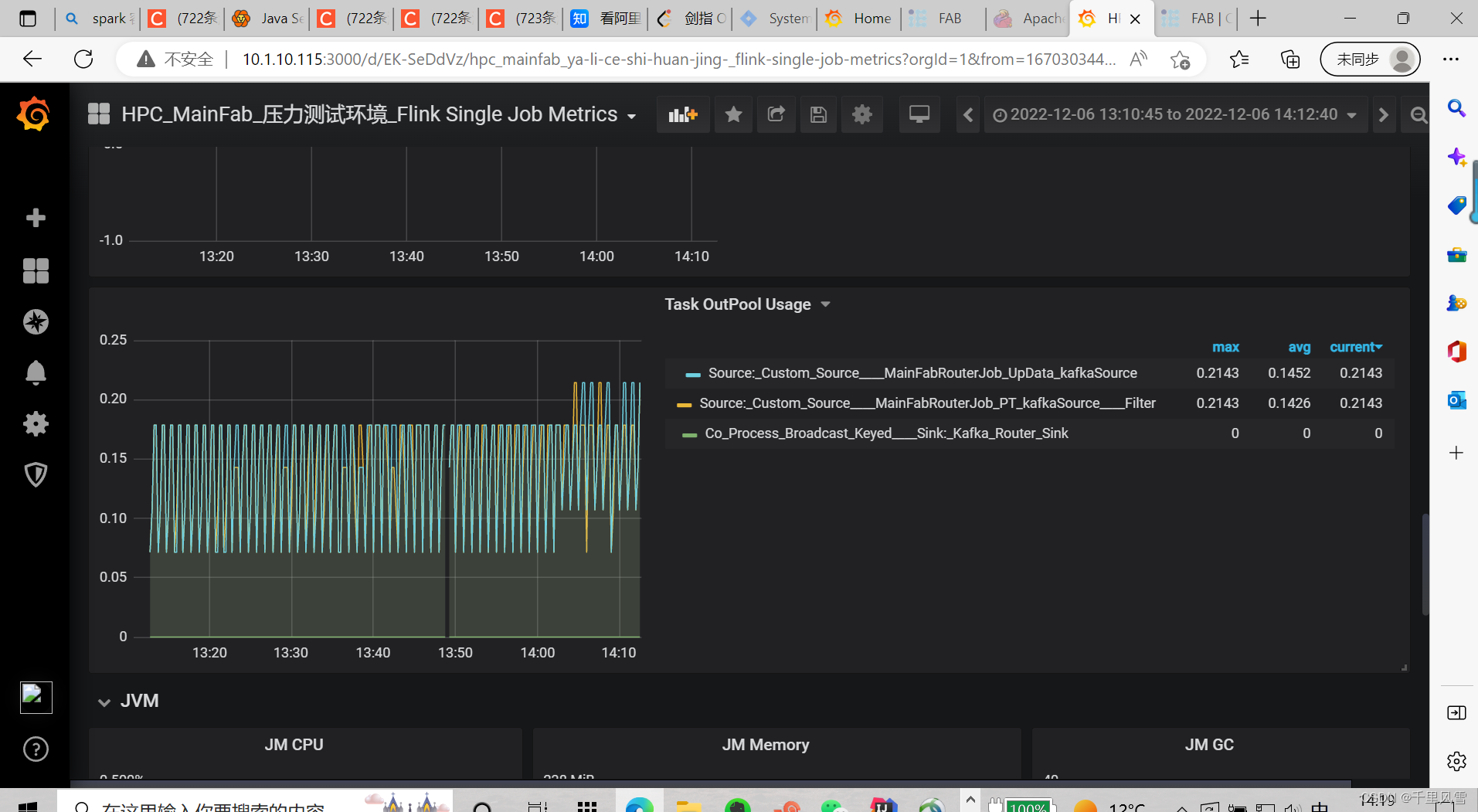

监控反压情况
根据算子的InPool, OutPool 的比例, 可以看出是在哪个算子出现了反压
反压造成的原因:
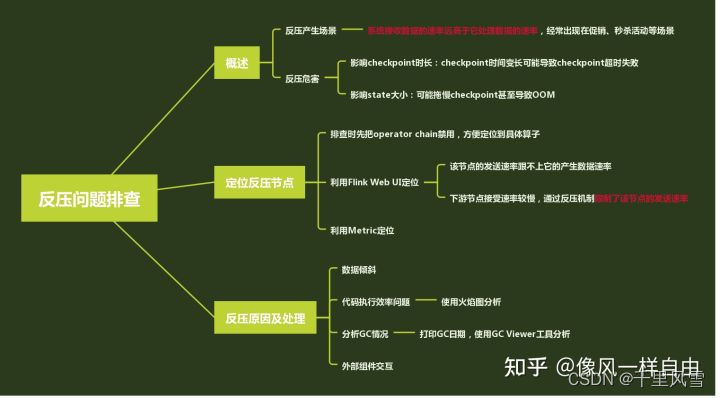
具体的现象:
1:加载配置
现象: 有一次 flink KeyedBroadcastProcessFunction 类里的open 方法加载 全量hbase 配置信息时, 有一个function代码解析耗时10分支以上,超过了checkpoint时长, 导致 checkpoint失败,
整个数据流出现了反压现象, 不能往下走,
解决方案: 优化慢的function代码
2: flink 自定义写hdfs 的addsink 方法里 出现了挤压现象,
现象: flink 自定义写hdfs 的addsink 方法处理慢,出现了挤压现象;导致上游反压,后排查发现时 addsink 里面有一个解析rawtrace方法耗时很长, 同时RichSinkFunction 是和平行度一样的线程数, 导致出现了阻塞
解决方案: 把解析rawtrace代码放在了keyby, map里, keyby是按照traceId, 将解析rawtrace 放在procesfuntion里, 每来一条数据就解析一次, 而不是在最后写入的时候去解析,这样不会出现阻塞的现象
3: flink 写入hbase,
现象: 自定义addsink,开始是一条数据写入一次, 当高峰值时,大量的indicator数据需要写入, 导致反压严重, 最后消费写入时间超过了checkpoint, flink job 出现了checkpoint 超时现象。 job 内部重启
解决方案: 自定义翻滚窗口触发器,按照条数和时间触发,批量写入hbase
4: flink job 处理业务逻辑长 run
现象: 比如24个小时的窗口数据,缓存,一个机台可能有1000个传感器,每个传感器一秒一条数据; keby机台,出现了数据倾斜的现象, 最后导致一个并行度处理, checkpoint超时, flink job 挂掉,
解决方案: 优化1: 自定义keby将1000个拆分到不同的分区, 比如按照50分成一组,解决数据倾斜, 优化2: 一个run 24小时的传感器数据缓存到rocksdb,防止内存撑爆
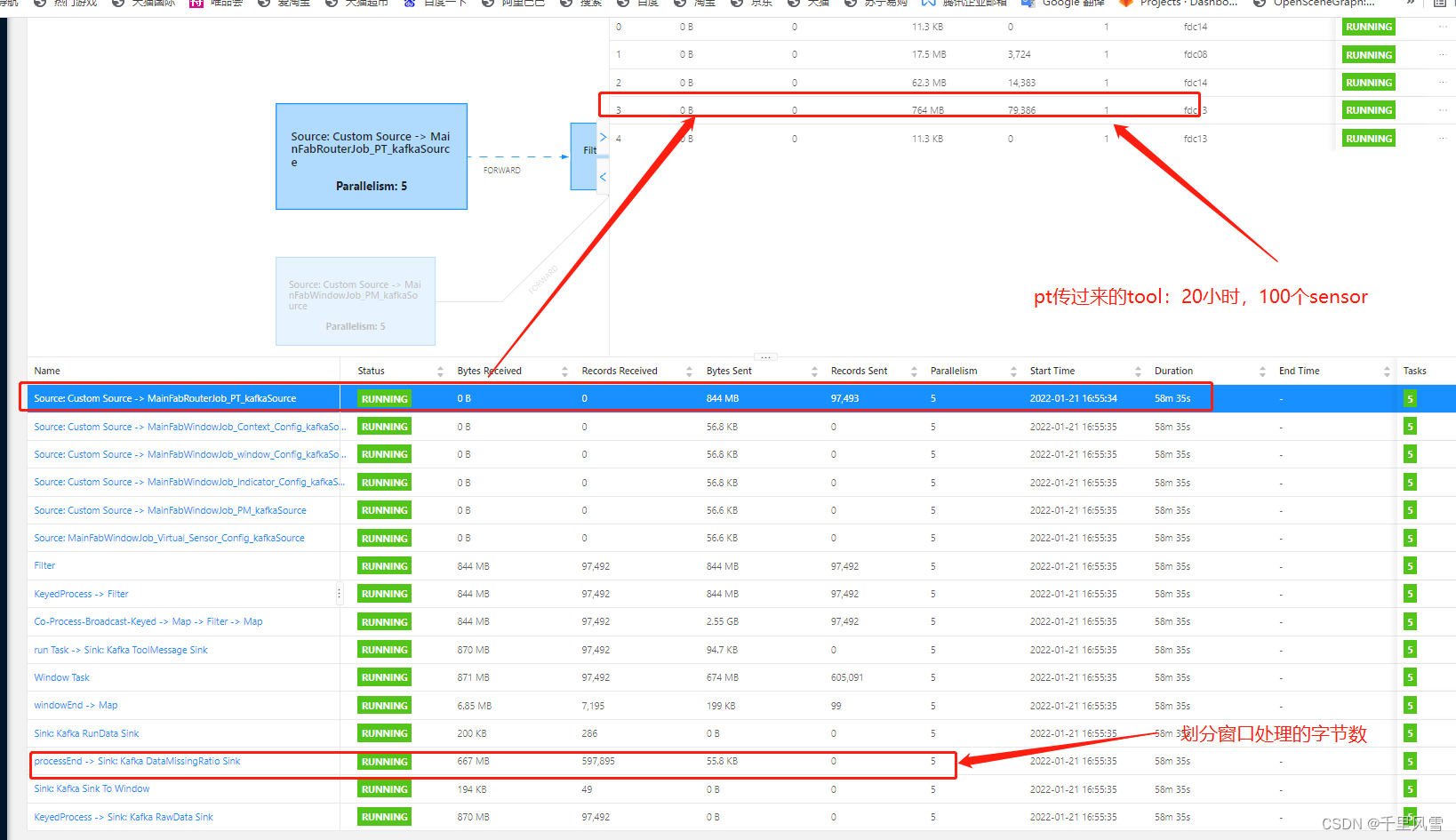
job挂掉现象
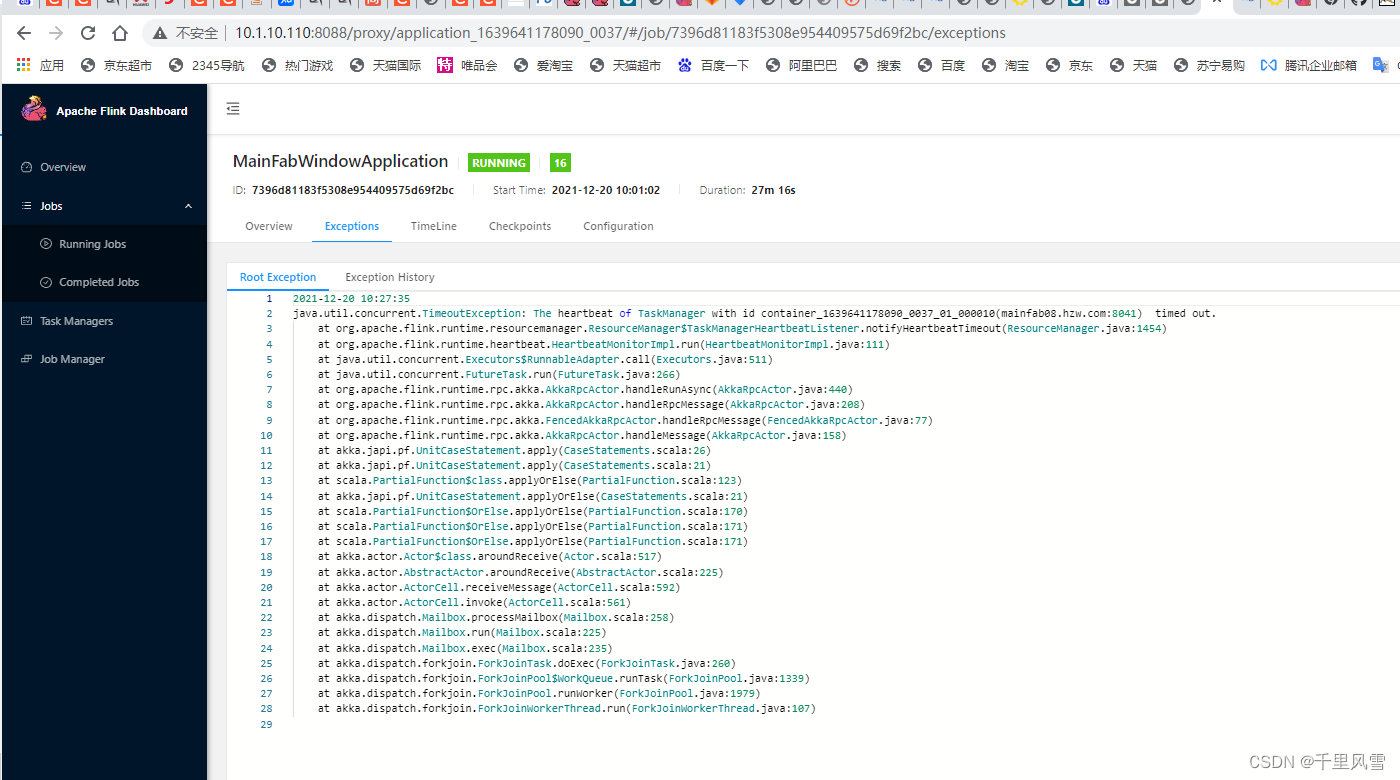
报错:org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold.
org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold.
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleCheckpointException(CheckpointFailureManager.java:98) ~[MainFabFlinkJob-phase3dev-dc2c28c-211217093339.jar:?]
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:67) ~[MainFabFlinkJob-phase3dev-dc2c28c-211217093339.jar:?]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1911) ~[MainFabFlinkJob-phase3dev-dc2c28c-211217093339.jar:?]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1884) ~[MainFabFlinkJob-phase3dev-dc2c28c-211217093339.jar:?]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.access$600(CheckpointCoordinator.java:95) ~[MainFabFlinkJob-phase3dev-dc2c28c-211217093339.jar:?]
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator$CheckpointCanceller.run(CheckpointCoordinator.java:2025) ~[MainFabFlinkJob-phase3dev-dc2c28c-211217093339.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_144]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_144]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_144]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) ~[?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_144]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_144]
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.addConditionWaiter(AbstractQueuedSynchronizer.java:1855) ~[?:1.8.0_144]
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2068) ~[?:1.8.0_144]
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093) ~[?:1.8.0_144]
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809) ~[?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074) ~[?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) ~[?:1.8.0_144]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_144]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_144]
2021-11-26 17:12:04,536 ERROR org.apache.http.impl.nio.client.InternalHttpAsyncClient [] - I/O reactor terminated abnormally
org.apache.http.nio.reactor.IOReactorException: I/O dispatch worker terminated abnormally
at org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor.execute(AbstractMultiworkerIOReactor.java:359) ~[MainFabFlinkJob-phase4dev-381440c-211125111401.jar:?]
at org.apache.http.impl.nio.conn.PoolingNHttpClientConnectionManager.execute(PoolingNHttpClientConnectionManager.java:221) ~[MainFabFlinkJob-phase4dev-381440c-211125111401.jar:?]
at org.apache.http.impl.nio.client.CloseableHttpAsyncClientBase$1.run(CloseableHttpAsyncClientBase.java:64) [MainFabFlinkJob-phase4dev-381440c-211125111401.jar:?]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_144]
Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
6: 误用滑动窗口
现象: 设置一天时长的窗口,一分钟滑动一次
解决方案: 设置一小时的窗口,一分钟滑动一次; 然后用小时窗口的结果数据去计算一天的实时统计i数据

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)