Redis搭建集群,三主三从集群模式
几种常见的redis集群模式:方案一:主从复制优点:支持主从复制,主机会自动将数据同步到从机,可以进行读写分离为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。Master Server是以非阻塞的方式为Slaves提供服务。所以在Ma
几种常见的redis集群模式:
方案一:主从复制
优点:
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然
必须由Master来完成
Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端
仍然可以提交查询或修改请求。
Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请
求,Redis则返回同步之前的数据
缺点:
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等
待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降
低了系统的可用性。
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
方案二:哨兵模式
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换,系统更健壮,可用性更高。
缺点:
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
方案三:集群模式
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主
节点宕机的时候,就会启用从节点
集群中至少应该有奇数个节点,所以至少有三个节点,每个节点至少有一个备份节点,所以至少需
要6个节点
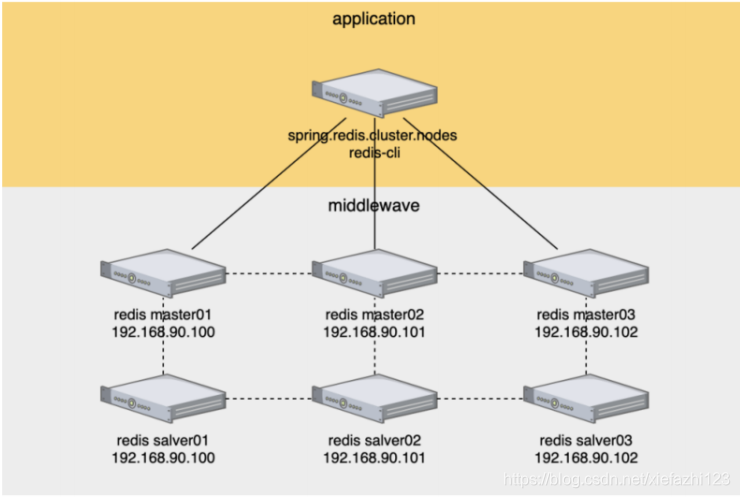
Redis推荐采⽤⽆中⼼化的集群⽅案,所有主节点同时提供读写服务,提服务中断本⽅案采⽤三主三从、6个节点部署集群,节点之间保持互相通信,区分客户端或应⽤程序通过配置cluster所有节点的模式调⽤集群
一. redis的解压安装
**环境:**准备三台机器,分别为192.168.90.17,192.168.90.124,192.168.90.165,三台机器均为ubuntu系统。
**目标:**每台机器redis部署为一主一从,三台机器redis部署为三从三从集群模式。
1.下载redis压缩包并解压
1.wget http://download.redis.io/releases/redis-5.0.12.tar.gz
2.tar -zvxf redis-5.0.12.tar.gz
注:这种方式下载的包有问题,无法解压。可从redis官网将5.0.12版本的包先下载下来,然后上载到服务器上,然后在进行解压即可。
2.安装,在redis-5.0.12目录下执行
1. make install PREFIX=/home/adp/redis-5.0.12(注意后面PREFIX的值为你解压后生成的Redis目录的绝对路径)
执行完后会生成一个在redis-5.0.12目录下会生成一个bin目录,并且deps和src也会更新
3.开始配置
先在一台机器上(192.168.90.17)做一下配置:
(1)redis-5.0.12目录下创建一个cluster-conf目录,并在cluster-conf目录下创建6380、6381两个目录
1. [root@adp]$ mkdir cluster-config
2. [root@adp]$ mkdir 6380
3. [root@adp]$ mkdir 6381
(2)创建端口目录并修改配置信息,如下
1. [root@adp]$ cp redis.conf ./cluster-config/6380
2. [root@adp]$ cp redis.conf ./cluster-config/6381
分别修改6380、6381目录下redis.conf文件如下内容:
以6380端口为例:
1.端口
port 6380
2.指定日志文件路径
logfile “/home/adp/redis-5.0.12/cluster-config/6380/redis.log”
3.指定rdb、aof文件写入路径
dir /home/adp/redis-5.0.12/cluster-config/6380/
4.是否开启集群
cluster-enabled yes
5.集群配置文件名称
cluster-config-file nodes-6380.conf
6.超时时间
cluster-node-timeout 15000(默认值)
7.持久化配置
appendonly yes
8.pidfile redis-5.0.12/cluster-config/6380.pid/ pid位置
9.ip 绑定 一定要写本机ip并且建立集群的时候要用这个ip建立
bind 需要绑定本机的真实ip,这样外部才能连接进来
10.redis 密码设置,每个节点的密码必须一致
masterauth <yourpassword> 连接主节点密码
requirepass <yourpassword> 各个节点访问密码
11.cluster-config-file nodes.conf 节点信息,自动生成
12.daemonize yes 守护线程模式(后台启动)
13.关闭保护模式用 于公网访问
protected-mode no
[](javascript:void(0);
真实配置如下:
port 6380
logfile /home/adp/redis-5.0.12/cluster-config/6380/redis.log
dir /home/adp/redis-5.0.12/cluster-config/6380/
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
appendonly yes
pidfile redis-5.0.12/cluster-config/6380.pid/
bind 192.168.90.17
masterauth 123456
requirepass 123456
daemonize yes
protected-mode no
(3)将文件复制到其他两台机器上
[root@adp]$ scp -r redis-5.0.12 root@192.168.90.124:/home/adp
[root@adp]$ scp -r redis-5.0.12 root@192.168.90.165:/home/adp
注:由于是分三台机器(真实的高可用),所以涉及到的端口配置不需要修改 。如果是在同一台机器上搭建的集群属于伪集群
(4)启动,先切换到redis的src目录下分别在三台机器上都执行对应命令,开启每个端口实例,后便可启动集群。
[root@adp]$ ./redis-server /home/adp/redis-5.0.12/cluster-config/6380/redis.conf &
[root@adp]$ ./redis-server /home/adp/redis-5.0.12/cluster-config/6381/redis.conf &
执行完后在终端输入,会看到对应的进程信息,则表示成功启动
[root@adp]$ ps -ef|grep redis
hadoop 4046 16759 0 16:00 pts/1 00:00:00 grep redis
hadoop 25805 16759 0 11:48 pts/1 00:00:04 ./redis-server 0.0.0.0:6380 [cluster]
hadoop 25808 16759 0 11:48 pts/1 00:00:04 ./redis-server 0.0.0.0:6381 [cluster]
(5)创建集群
集群结构:每个节点保存数据和集群信息状态,每个节点和其他节点连接
其结构特点:
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
容错性:
容错性指软件检测应用程序所在运行的软件或硬件中发生的错误并从错误中恢复的能力,通常可以从系统的可靠性,可用性,可测性的等几方面来衡量。
- 1 什么时候判断 master 不可用?
投票机制。投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master节点通信超时(cluster-node-timeout)认为当前 master 节点挂掉
- 2 什么时候整个集群不可用(cluster state: fail)
如果集群任意 master 挂掉,且当前 master 没有 slave。集群进入fail状态也可以理解成集群的 Slot 映射 0-16383] 不完整时进入 fail 状态。如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态
分 5.0下的版本,和 5.0 以上的版本安装(注:本文采用5.0以上的版本)
1)*5.0以上的版本:*
*使用redis-cli 创建redis集群(redis5以前的版本集群是依赖 ruby 脚本实现)*
****启动了每个端口之后,就直接创建集群:******
****第一种:直接创建,随机分配从机。******
****选项–replicas 1 表示为集群中的每个主节点创建一个从节点******
1. [root@mastersrc]# ./redis-5.0.2/src/redis-cli --cluster create --cluster-replicas 1 192.168.90.17:6380 192.168.90.17:6381 10.1.1.12:6380 10.1.1.12:6381 10.1.1.39:6380 10.1.1.39:6381
接着会出现一个选项,直接输入 yes 既可继续创建任务
第二种:指定从机(本文采用该种方式)
选项–replicas 0 表示先为集群创建不含slaver 的集群。
./src/redis-cli --cluster create 192.168.90.17:6380 192.168.90.124:6380 192.168.90.165:6380 --cluster-replicas 0
手动添加slaver(从机)
使用创建时的cluster-master-id 或执行 ./src/redis-cli --cluster check 192.168.90.17:6380 查看运行状态
挂载slaver
./src/redis-cli --cluster add-node 192.168.90.17:6381 192.168.90.17:6380 --cluster-slave --cluster-master-id ba8415845612eceeb50f89eaa44485a393b58d1a
./src/redis-cli --cluster add-node 192.168.90.124:6381 192.168.90.124:6380 --cluster-slave --cluster-master-id 52aa810b8d3cf6dfcf37fbb3d64805f632d6af91
./src/redis-cli --cluster add-node 192.168.90.165:6381 192.168.90.165:6380 --cluster-slave --cluster-master-id 18b31f22eccc86ca13bcd992776cd3987b572441
如果创建了集群之后,想要设置密码,进行一下操作,不需要去修改 redis.conf 配置文件
./redis-cli -c -h bigdata24 -p 6380
config set masterauth <yourpassword>
config set requirepass <yourpassword>
config rewrite 示例:
./redis-cli -c -h bigdata24 -p 6380
config set masterauth 123
config set requirepass 123
config rewrite
加入了密码之后,进入到集群时,需要加 -a 选项 ,后面跟上你设置的密码
集群基本使用;
查看集群状态:
./redis-5.0.2/src/redis-cli -h 192.168.90.17 -p 6380 cluster nodes
使用redis-cli 连接集群, 指定 -c 参数
./redis-5.0.2/src/redis-cli -p 6380 -c -a 123
指定连接的主机节点(-h 主机ip, -a redis的密码(前提要设置密码,每个节点的密码必须保持一致))
./redis-5.0.2/src/redis-cli -h id地址 -p 6380 -c
进入集群的一个节点的一些操作:
查看节点信息命令:
> cluster info
> cluster nodes示例:[root@locslhost src]# redis-cli -c -p 6380 127.0.0.1:6380> get aa->Redirected to slot [2422]located at 127.0.0.1:6381"222"127.0.0.1:6381>
上面示例可以看出,客户端连接加 -c 选项进入到集群中,存储和提取 key 的时候不断在 6380和6381 之间跳转,这个称为客户重定向。之所以会客户端重定向,是因为redis cluster 中的每个Master 节点都会负责一部分的槽(slot),存取的时候都会进行键值空间计算定位 key 映射在哪个槽上,如果是映射的槽正好是的当前的master节点负责则直接存取,否则就会跳转到其他master节点负责的槽中存取。
-----------------------------------------------------------------------
*2)****5.0以下的版本安装:(5.0以下版本自行测试)*****
*安装ruby、redis
安装ruby2.3.1版本,建议采用这种方式安装(网上的其他方式基本都会失败,亲测)
第一步:下载安装包到对应目录(wget命令不指定目录 ,则下载到当前目录)*
[root@masterruby-2.3.1]$ wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
第二步:下载成功后解压,并切换到解压后的ruby目录下执行编译与安装:
[root@masterruby-2.3.1]$ ./configure --prefix=
[root@masterruby-2.3.1]$ make && make install
第三步:至此2.3.1版本ruby安装完成,输入如下命令,验证ruby是否安装完成
[root@masterruby-2.3.1]$ ruby -v
第四步:安装redis
[root@masterruby-2.3.1]$ gem install redis
第五步:开启集群在Redis的src目录下执行
[root@mastersrc]# ./redis-trib.rb create --replicas 1 10.1.1.34:6380 10.1.1.34:6381 10.1.1.12:6380 10.1.1.12:6381 10.1.1.39:6380 10.1.1.39:6381
至此集群搭建完成
可跨机器验证集群
[hadoop@slave2 bin]$ ./redis-cli -c -h 10.1.1.39 -p 6381
10.1.1.39:6381>
-c 为集群形式开启 -h ip -p 端口
查看集群状态
[ ](javascript:void(0)😉
](javascript:void(0)😉
[root@mastersrc]# ./redis-trib.rb check 127.0.0.1:6380
>>> Performing Cluster Check (using node 127.0.0.1:6380)
M: a0d41b839bf4f71cd32249587d9d00d571c2ec05 127.0.0.1:6380
slots:0-5460 (5461 slots) master
1 additional replica(s)
M: 0b1fb1ccd3af0a85a75f27b915a96ac832175ee5 10.1.1.12:6380
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: 2b1c67e00dfab99c46c5ad46b5b5af0a1021ce8e 10.1.1.39:6380
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: a62ac61543200fdbfd278f9e80e2105ff11d1780 10.1.1.34:6381
slots: (0 slots) slave
replicates 0b1fb1ccd3af0a85a75f27b915a96ac832175ee5
S: 26a7f4214285c39985c9803283f9ac8b39a72ac6 10.1.1.12:6381
slots: (0 slots) slave
replicates a0d41b839bf4f71cd32249587d9d00d571c2ec05
S: b0b2ace762a2210070a444cf8c9b6adf2ae585e1 10.1.1.39:6381
slots: (0 slots) slave
replicates 2b1c67e00dfab99c46c5ad46b5b5af0a1021ce8e
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
扩展(redis5.0版本集群移除节点):
redis 集群多了之后,发现现在的有些节点有些多余没用,或者达不到用那么多节点的情况,那么就可以进行 节点的移除, 5.0 版本由于不用 ruby 进行集群操作了,所以方式跟5.0以前有很多不同的地方
我以我机器上的 7008 节点为例
首先登录集群, 使用 cluster nodes 查看信息
获取到 7008 节点的ID(红圈中前面 8f111b3074341e145105d70bc27cf501553f239f )

执行下面命令(红色部分是7008节点的ID)
/usr/local/redis-5.0.5/bin/redis-cli --cluster del-node 192.168.58.129:7008 8f111b3074341e145105d70bc27cf501553f239f
出现以上信息代表成功

登录 7007 节点。查看节点信息

可以看到节点信息中已经没有 7008了
接着删除7007, 这个是一个主节点,删除起来比较麻烦一点,因为主节点分配了 slot槽, 所以这里我们必须先把 7007的slot槽放到其他的可用节点中去,然后再进行移除节点操作才行,不然会出现数据丢失问题
步骤一:把数据移动到其它主节点中去(目前只能把数据移到另外一个节点,没办法做到平均分配)
执行重新分片命令
/usr/local/redis-5.0.5/bin/redis-cli --cluster reshard 192.168.58.129:7007
打印以下信息

弹出以下提示:

上面看到7007 哪里 只有 199 个slot 槽,这里就填 199
回车之后 出现 what is the receiving node ID? 意思是你想移动到那个节点上

我想移动到 7003的节点上,那么此处输入 7003节点的ID
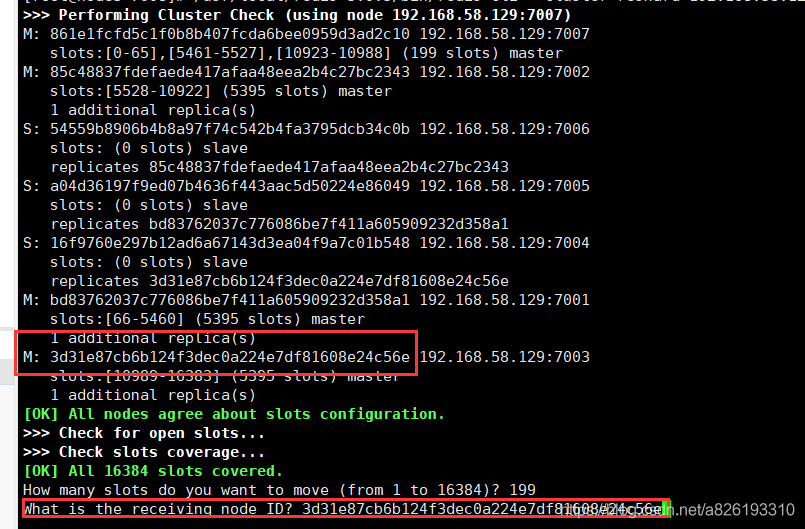
回车
出现以下界面
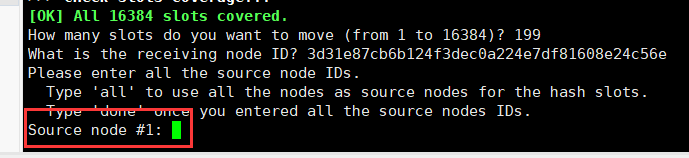
这里需要数据源,其实就是 7007 节点的ID,因为你是吧 7007 节点的数据放到其它地方去, 输入 7007 的ID,回车
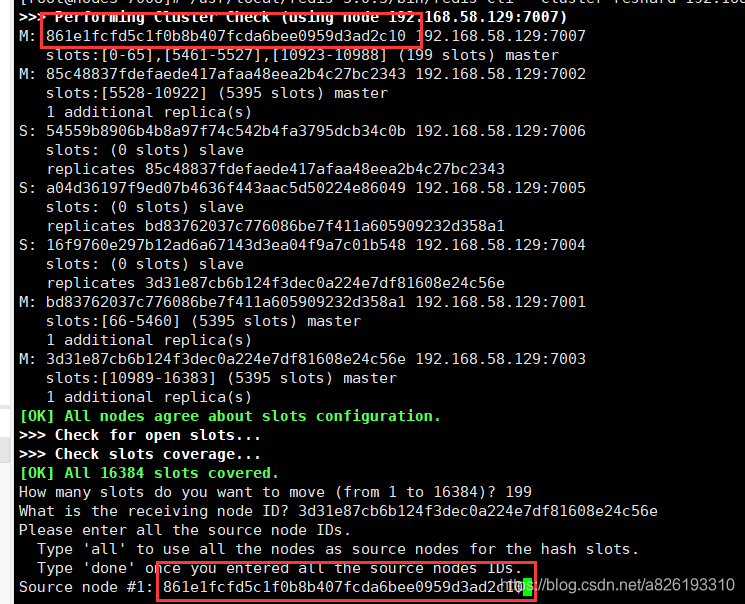
出现以下界面,
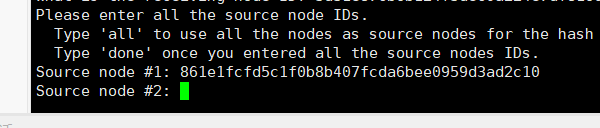
其实是让你还可以选择源节点,但是我这里只要把 7007 节点分到其它地方就行,如果没有再把其它主节点分摊的需要,此处输入 done即可,否则输入其它节点的ID,最后输入 done
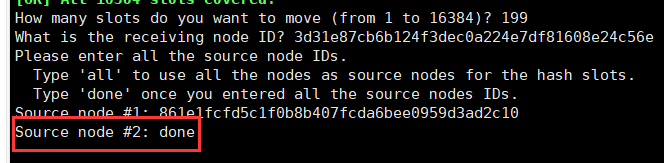
打印一堆信息,最后出现这个询问:
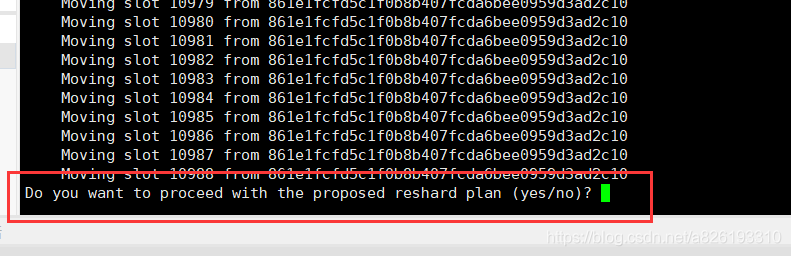
是否按照计划分配,输入yes
执行完成之后,输入 cluster nodes 查看节点信息

可以看到 7007 已经没有槽分配了
接下来,调用删除从节点的方式,删除主节点
/usr/local/redis-5.0.5/bin/redis-cli --cluster del-node 192.168.58.129:7007 861e1fcfd5c1f0b8b407fcda6bee0959d3ad2c10

移除成功,再次查看节点信息

可以看到 7007 也没有了

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)