Elasticsearch(一)——Es安装(三个必安工具、安装各种类型分词器)、Es 十大核心概念、通过 Kibana 操作 Es(中文分词、Es各种索引命令操作)
Elasticsearch(一)——Es安装(三个必安工具、安装各种类型分词器)、Es 十大核心概念、通过 Kibana 操作 Es(中文分词、Es各种索引命令操作)
Elasticsearch(一)——Es安装(三个必安工具、安装各种类型分词器)、Es 十大核心概念、通过 Kibana 操作 Es(中文分词、Es各种索引命令操作)
一、Elasticsearch 安装
这里博主是用 windows 来安装,其他地方不太好安装,容器出问题,主要是比较费空间和占内存。
这个 ES 可以当成搜索引擎来对待,也可以当成 NoSQL 数据库。
1、引言
在海量数据中执行搜索功能时,如果使用MySQL,效率太低。
将搜索关键字,以红色的字体展示。
Lucene,搜索的基础工具,是一个 jar 包。
Hadoop 两个可以直接用的产品,搜索引擎:
- Solr
- Elasticsearch
2、介绍
a、介绍
- ES 是一个使用 Java 语言并且基于 Lucene 编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于 RESTful 风格的 WEB 接口,官方客户端也对多种语言都提供了相应的 API。
- Lucene:Lucene 本身就是一个搜索引擎的底层,一个搜索工具。Solr,Es
- 分布式:ES 主要是为了突出他的横向扩展能力。
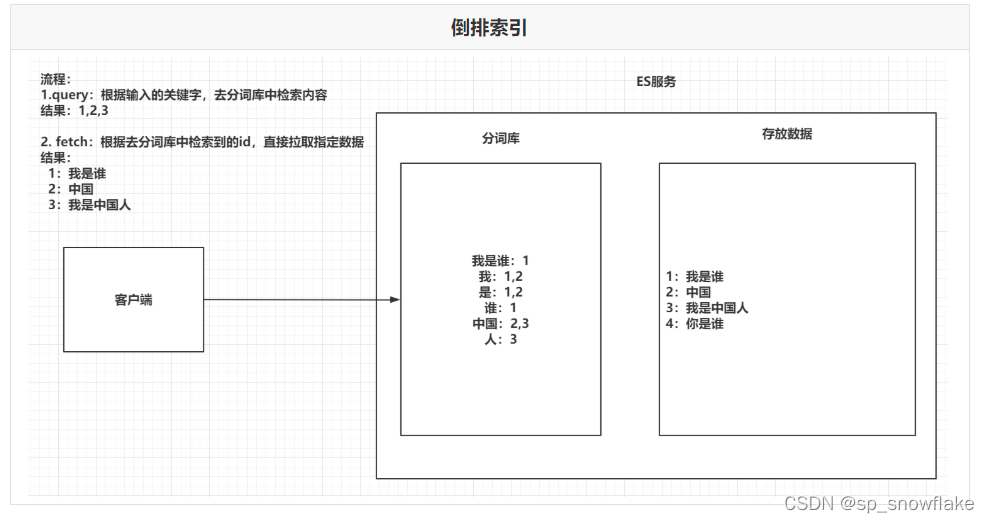
- 全文检索:将一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去分词库中检索,找到匹配的内容。(倒排索引)
- RESTful 风格的 WEB 接口:操作 ES 很简单,只需要发送一个 HTTP 请求,并且根据请求方式的不同,携带参数的同时,执行相应的功能。
- 应用广泛:Github.com,WIKI,Gold Man 用 ES 每天维护将近 10TB 的数据。
b、由来

c、ES 和 Solr
- Solr 在查询死数据时,速度相对 ES 更快一些。但是数据如果是实时改变的,Solr 的查询速度会降低很多,ES 的查询的效率基本没有变化。
- Solr 搭建基于需要依赖 Zookeeper 来帮助管理。ES 本身就支持集群的搭建,不需要第三方的介入。
- 最开始 Solr 的社区可以说是非常火爆,针对国内的文档并不是很多。在 ES 出现之后,ES 的社区火爆程度直线上升,ES 的文档非常健全。
- ES 对现在云计算和大数据支持的特别好。
d、倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。当用户去查询数据时,会将用户的查询关键字进行分词。然后去分词库中匹配内容,最终得到数据的id标识。根据id标识去存放数据的位置拉取到指定的数据。
3、安装(强烈建议安装目录下没有中文)
安装目录如果有中文,后面可能会有一些难以察觉的错误;一开始就纯英文路径就可以免去这些问题的考虑。
安装要装三个东西。
a、单节点安装(Es 本体)
首先打开 Es 官网,找到 Elasticsearch:
https://www.elastic.co/cn/elasticsearch/
然后点击下载按钮,选择合适的版本直接下载即可。

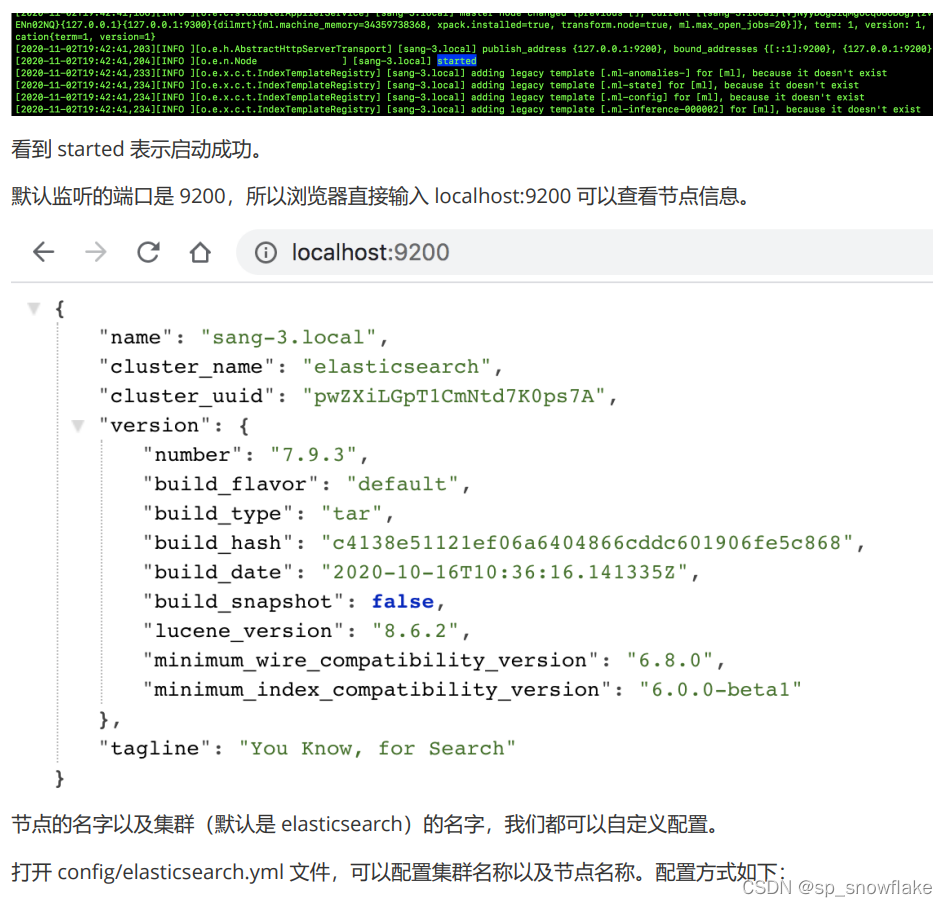
cluster.name: xxx
node.name: xxx
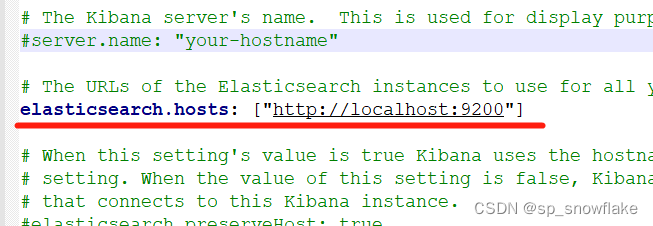
配置完成后,保存配置文件,并重启 es。重启成功后,刷新浏览器 localhost:9200 页面,就可以看到最新信息。
Es 支持矩阵:
https://www.elastic.co/cn/support/matrix
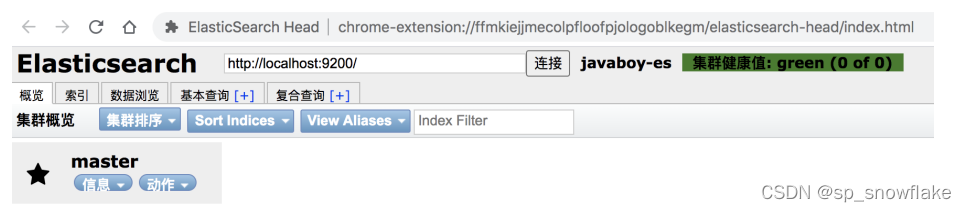
b、HEAD 插件(查看 Es 详细信息,非必须安装)
这玩意不是必须安装的,但是安装了会方便查看。
这里有两种方式,一个是浏览器插件,另外一个是下载插件安装。不建议下载插件,因为这么安装相当于 ES-HEAD 是一个独立运行的工程,这种方式访问 ES 会有一个跨域的问题,还要配置跨域,比较麻烦。
(1)浏览器插件安装
Chrome 直接在 App Store 搜索 Elasticsearch-head,点击安装即可。
如果是 火狐浏览器,可以直接在扩展插件下载。(听说的,但是博主找不到)
(2)下载插件安装(不建议,因为要处理跨域问题)
四个步骤:
- git clone git://github.com/mobz/elasticsearch-head.git
- cd elasticsearch-head
- npm install
- npm run start
启动成功,页面如下:

注意,此时看不到集群数据。原因在于这里通过跨域的方式请求集群数据的,默认情况下,集群不支持跨域,所以这里就看不到集群数据。
解决办法如下,修改 es 的 config/elasticsearch.yml 配置文件,添加如下内容,使之支持跨域:
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后,重启 es,此时 head 上就有数据了。

c、Kibana 安装
一个测试、练习的工具。也可以用 postman 来测试,但是 postman 不方便, Kibana 内部提供了一些工具。
Kibana 是一个 Elastic 公司推出的一个针对 es 的分析以及数据可视化平台,可以搜索、查看存放在 es中的数据。
注意:要跟 Es 相同版本,不然可能链接不上 Es。
安装步骤如下:
- 下载 Kibana:https://www.elastic.co/cn/downloads/kibana
- 解压
- 配置 es 的地址信息(可选,如果 es 是默认地址以及端口,可以不用配置,具体的配置文件是config/kibana.yml)
- 执行 ./bin/kibana 文件启动
- localhost:5601
上面第三步的配置演示:
Kibana 安装好之后,首次打开时,可以选择初始化 es 提供的测试数据,也可以不使用。

d、分布式安装
这个分布式安装这里只是提一下,主要还是上面的三个安装。
假设:
一主二从,master 的端口是 9200,slave 端口分别是 9201 和 9202。
首先修改 master 的 config/elasticsearch.yml 配置文件:
node.master: true
network.host: 127.0.0.1
配置完成后,重启 master。将 es 的压缩包解压两份,分别命名为 slave01 和 slave02,代表两个从机。分别对其进行配置。
slave01/config/elasticsearch.yml:
# 集群名称必须保持一致
cluster.name: javaboy-es
node.name: slave01
network.host: 127.0.0.1
http.port: 9201
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
slave02/config/elasticsearch.yml:
# 集群名称必须保持一致
cluster.name: javaboy-es
node.name: slave02
network.host: 127.0.0.1
http.port: 9202
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
然后分别启动 slave01 和 slave02。启动后,可以在 head 插件上查看集群信息:

4、安装分词器(强烈建议安装目录下没有中文)
Es中默认不提供中文分词,其实不是不能分,主要是对中文分词的方式不对。
a、内置分词器
ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。查询分析则主要分为两个步骤:
- 词条化:分词器将输入的文本转为一个一个的词条流。
- 过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤
器、小写过滤器等。
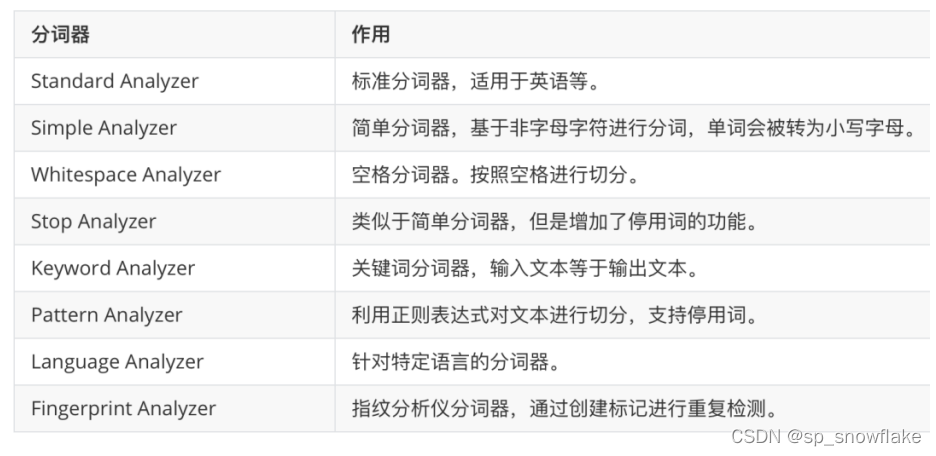
ElasticSearch 中内置了多种分词器可以供使用。
内置分词器(下面这些统统都不支持中文分词):
b、中文分词器
在 Es 中,使用较多的中文分词器是 elasticsearch-analysis-ik,这个是 es 的一个第三方插件,代码托管在 GitHub 上:
https://github.com/medcl/elasticsearch-analysis-ik
两种使用方式:
(1)第一种使用方式(Windows)
- 首先打开分词器官网:https://github.com/medcl/elasticsearch-analysis-ik。
- 在 https://github.com/medcl/elasticsearch-analysis-ik/releases 页面找到最新的正式版,下载下来。我们这里的下载链接是 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip。
- 将下载文件解压。
- 在 es/plugins 目录下,新建 ik 目录,并将解压后的所有文件拷贝到 ik 目录下。
- 重启 es 服务。
(2)第二种使用方式(Linux)
/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearchanalysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
c、测试
测试看第三章的第四、五小节,可以看到有无中文分词器的差别。
d、本地自定义扩展词库
比如有的网络流行热词,这种词语肯定是不能按照我们想的意思来分词的,所以可以通过本地自定义词库来对一些我们想要的词语进行分词,比如像:群除我佬(群里除了我都是大佬)这种词,就可以自定义。
先查看 es/plugins/ik/config 目录下的 IKAnalyzer.cfg.xml 文件:

在 es/plugins/ik/config 目录下(这里已经导入了分词库,ik 是自定义的文件夹),新建 my_ext.dic 文件(文件名任意),在该文件中可以配置自定义的词库:
新建这么一个文件:
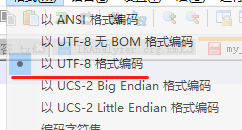
记得这里要设置编码格式:

然后还要配置这个词库:
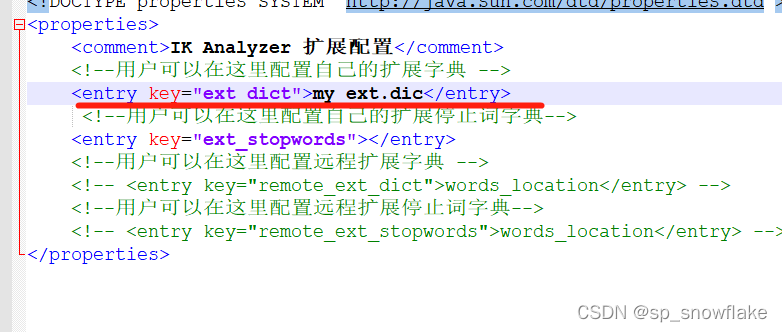
接着重启 Es,然后再测试,这时就能发现可以成功分词了。测试结果看第三章第四小节。
e、远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 es 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
具体使用方式如下,新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 ext.dic 文件,写入扩展词:
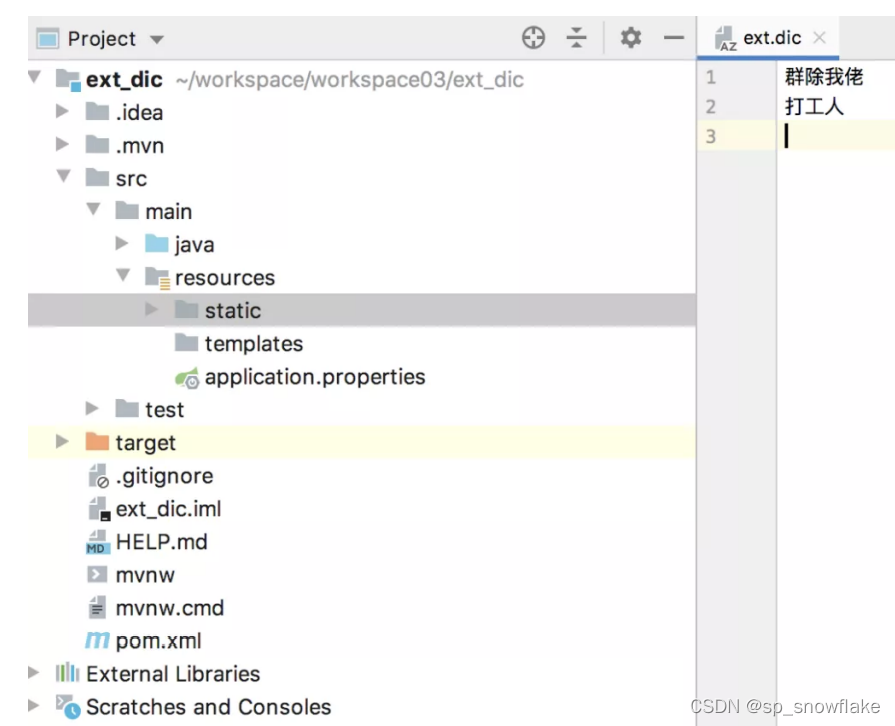
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展词接口:

配置完成后,重启 es ,即可生效。
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展。
5、打开步骤
安装好以后,以后每次需要打开就按照以下步骤:
打开 Es 本体( Es 目录下 / bin / elasticsearch.bat)。
打开 Kibana (Kibana 目录下 / bin / kibana.bat)。
二、Es 十大核心概念
1、集群(Cluster)
一个或者多个安装了 es 节点的服务器组织在一起,就是集群,这些节点共同持有数据,共同提供搜索服务。
一个集群有一个名字,这个名字是集群的唯一标识,该名字成为 cluster name,默认的集群名称是 elasticsearch,具有相同名称的节点才会组成一个集群。
意思就是只要起同一个名字,就是集群,会自动的互相找到对方。
可以在 config/elasticsearch.yml 文件中配置集群名称:
cluster.name:xxx
在集群中,节点的状态有三种:绿色、黄色、红色:
- 绿色:节点运行状态为健康状态。所有的主分片、副本分片都可以正常工作。
- 黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行,但是至少有一个副本分片是不能正常工作的。
- 红色:表示集群无法正常工作。
2、节点(Node)
集群中的一个服务器就是一个节点,节点中会存储数据,同时参与集群的索引以及搜索功能。一个节点想要加入一个集群,只需要配置一下集群名称即可。默认情况下,如果我们启动了多个节点,多个节点还能够互相发现彼此,那么它们会自动组成一个集群,这是 es 默认提供的,但是这种方式并不可靠,有可能会发生脑裂现象。所以在实际使用中,建议一定手动配置一下集群信息。
3、索引(index)
索引可以从两方面来理解:
名词:具有相似特征文档的集合。类似于关系型数据库中的数据库概念,并不跟库完全一样,只是可以当成这么理解。
动词:索引数据以及对数据进行索引操作。意思就是要存储一个数据,存储到 Es 里面去。
4、类型(Type)
类型是索引上的逻辑分类或者分区。在 es6 之前,一个索引中可以有多个类型,从 es7 开始,一个索引中,只能有一个类型。在 es6.x 中,依然保持了兼容,依然支持单 index 多个 type 结构,但是已经不建议这么使用。
5、文档(Document)
一个可以被索引的数据单元。例如一个用户的文档、一个产品的文档等等。文档都是 JSON 格式的。
6、分片(Shards)
索引都是存储在节点上的,但是受限于节点的空间大小以及数据处理能力,单个节点的处理效果可能不理想,此时我们可以对索引进行分片。当我们创建一个索引的时候,就需要指定分片的数量。每个分片本身也是一个功能完善并且独立的索引。
默认情况下,一个索引会自动创建 1 个分片,并且为每一个分片创建一个副本。
7、副本(Replicas)
副本也就是备份,是对主分片的一个备份。
8、Settings
集群中对索引的定义信息,例如索引的分片数、副本数等等。
9、Mapping
Mapping 保存了定义索引字段的存储类型、分词方式、是否存储等信息。
10、Analyzer
字段分词方式的定义。
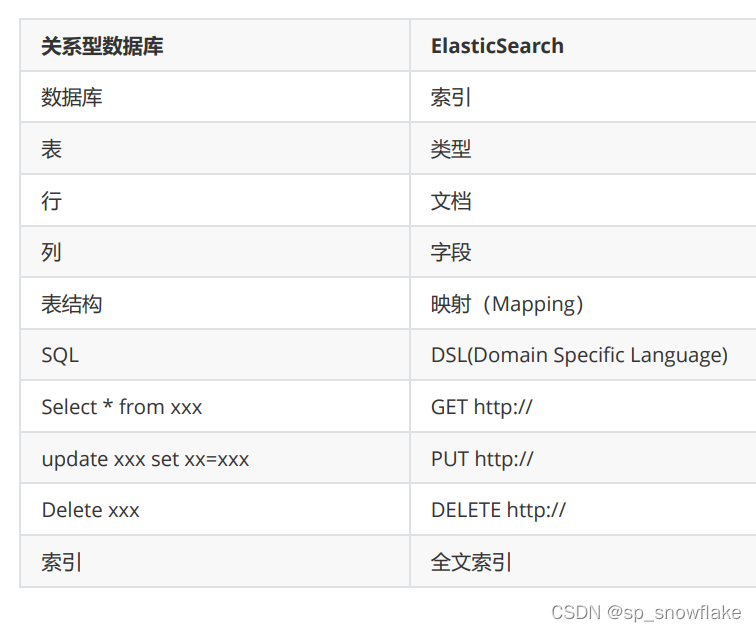
11、ElasticSearch Vs 关系型数据
三、通过 Kibana 操作 Es
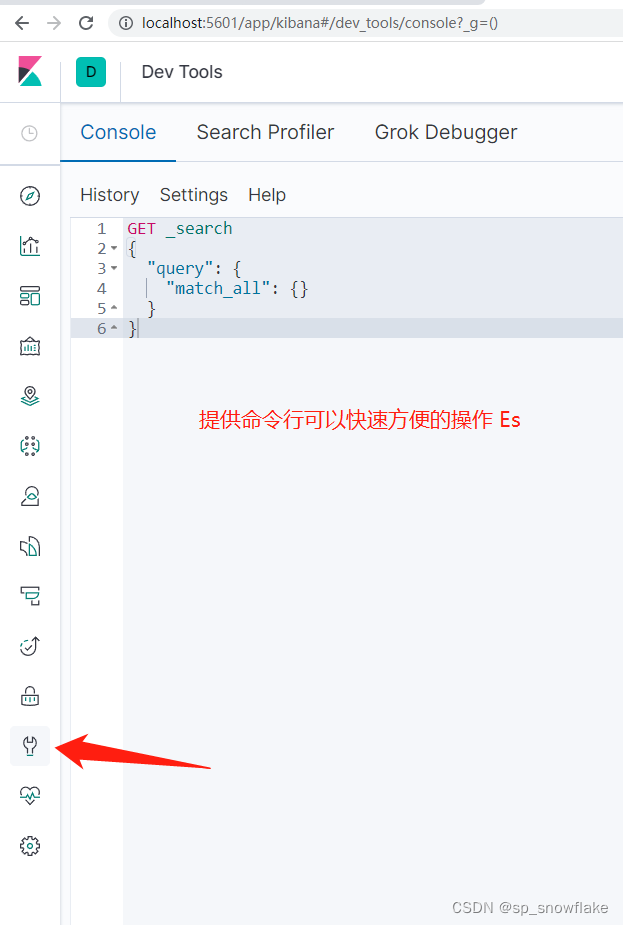
1、初识命令行
2、关于 http 的 get 的请求体说法
其实 http 协议中并没有说 get 不能有请求体,但是在 Java 中确实是没有请求体的。但是在 Es 中可以传请求体,Es也考虑到有的语言不支持 get 的请求体,所以在 Es 中能够使用 get 请求的统统都可以使用 post 请求,就是防止有的语言中 get 没有请求体;换成 post 的就可以处理了。
3、简单使用
首先,创建索引不能有大写字母!不然会报错。
a、请求创建索引
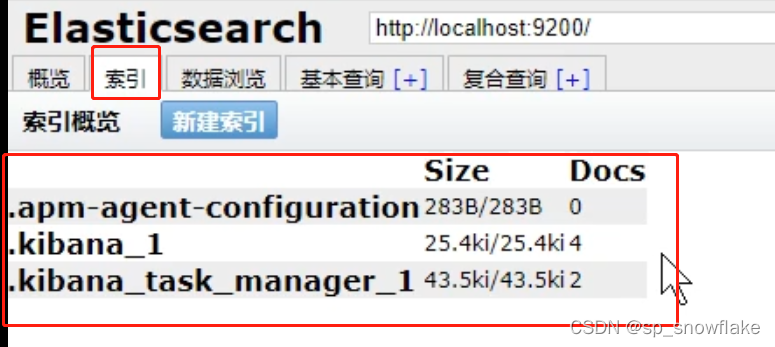
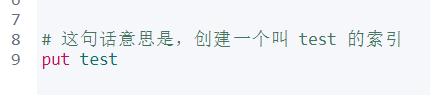
可以看到现在没有一个叫 test 的索引,那么现在可以创建索引(put 请求可以添加索引也可以更新索引;当没有这个索引的时候就是添加索引):
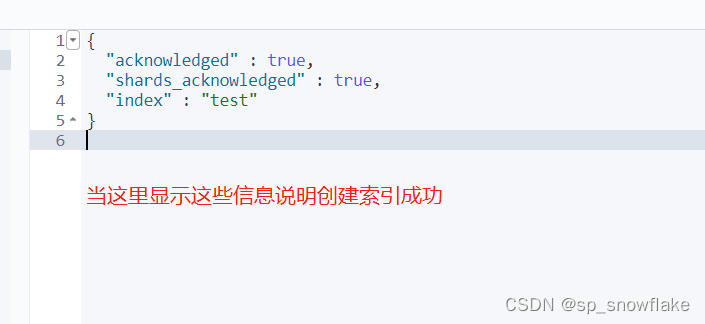
然后看控制台右边:
此时再刷新 Es-head 索引分栏:
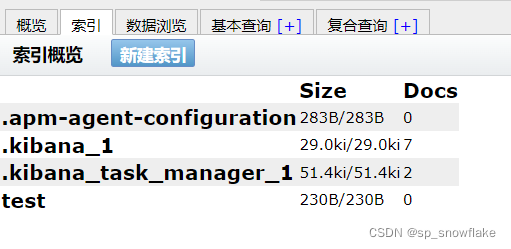
可以发现就有 test 索引了。
b、通过 head 插件创建索引
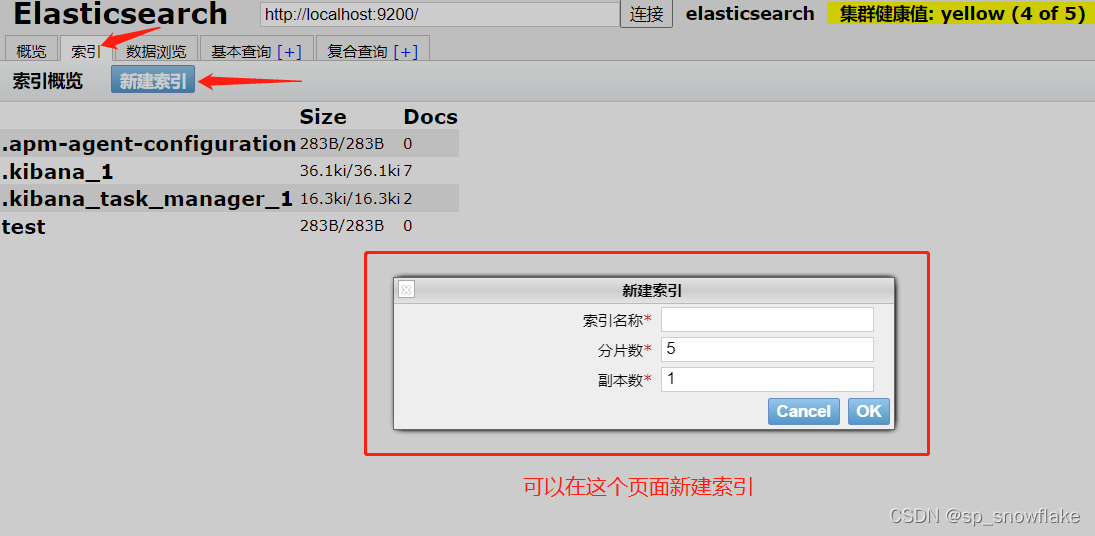
然后效果:
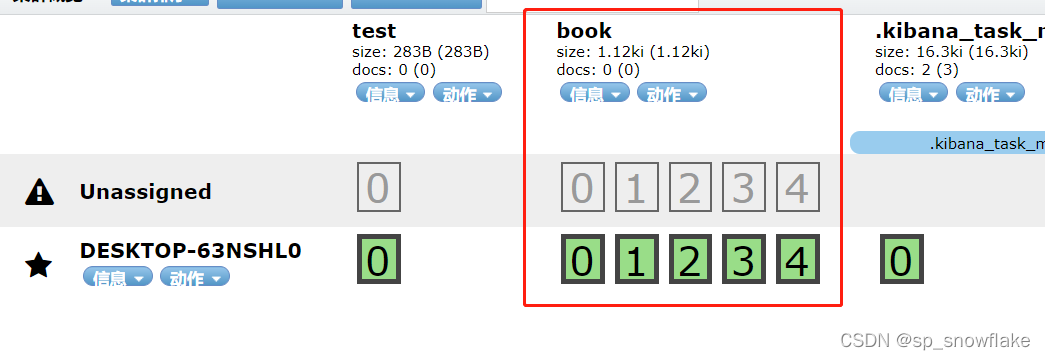
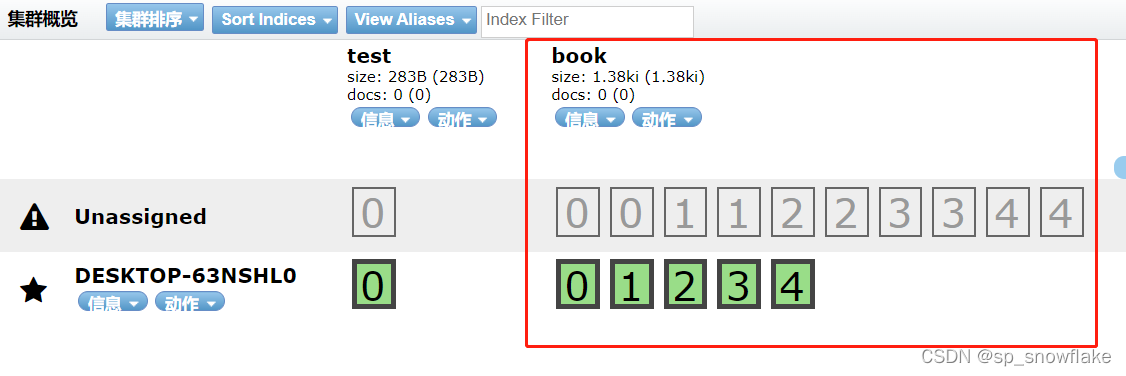
可以看到这就是五个分片(0、1、2、3、4),然后上下有两层,也就是一个副本。
c、对一个英文语句进行分词

结果:
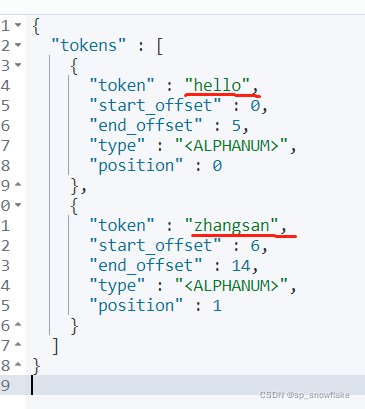
可以看到 hello zhangsan 分词后的结果是:hello zhangsan
start_offset:从第几个字符开始的。
end_offset:从第几个字符结束。
position:位置。
4、中文分词
a、没有使用中文分词器

然后查看结果:

可以看到是一个词一个词的分,那么 Es 存储就是一个字一个字的存,所以搜索也就是一个字一个字的搜索,不能用词语去搜索;也就意味着不能断句。
b、使用 ik_max_word 分词器
还是这个素材:
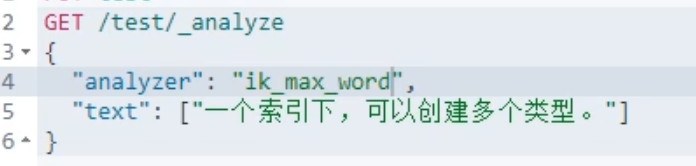
结果:
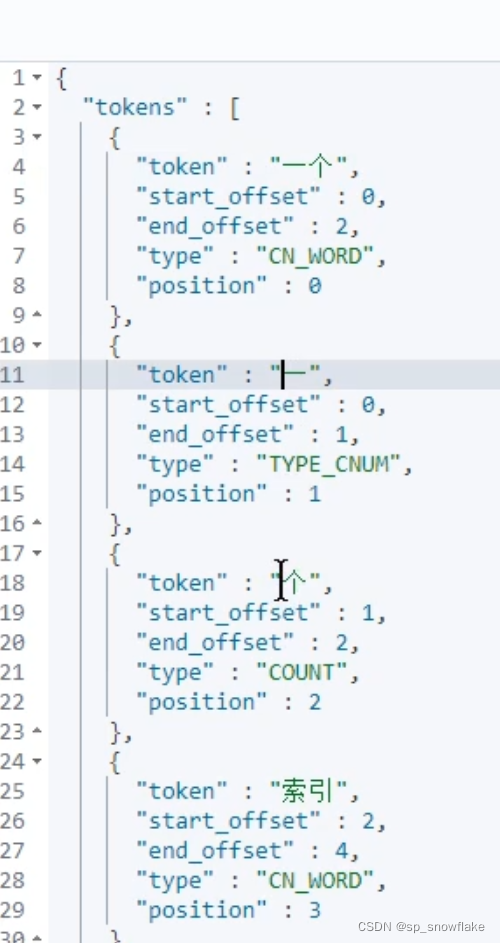
其他素材:
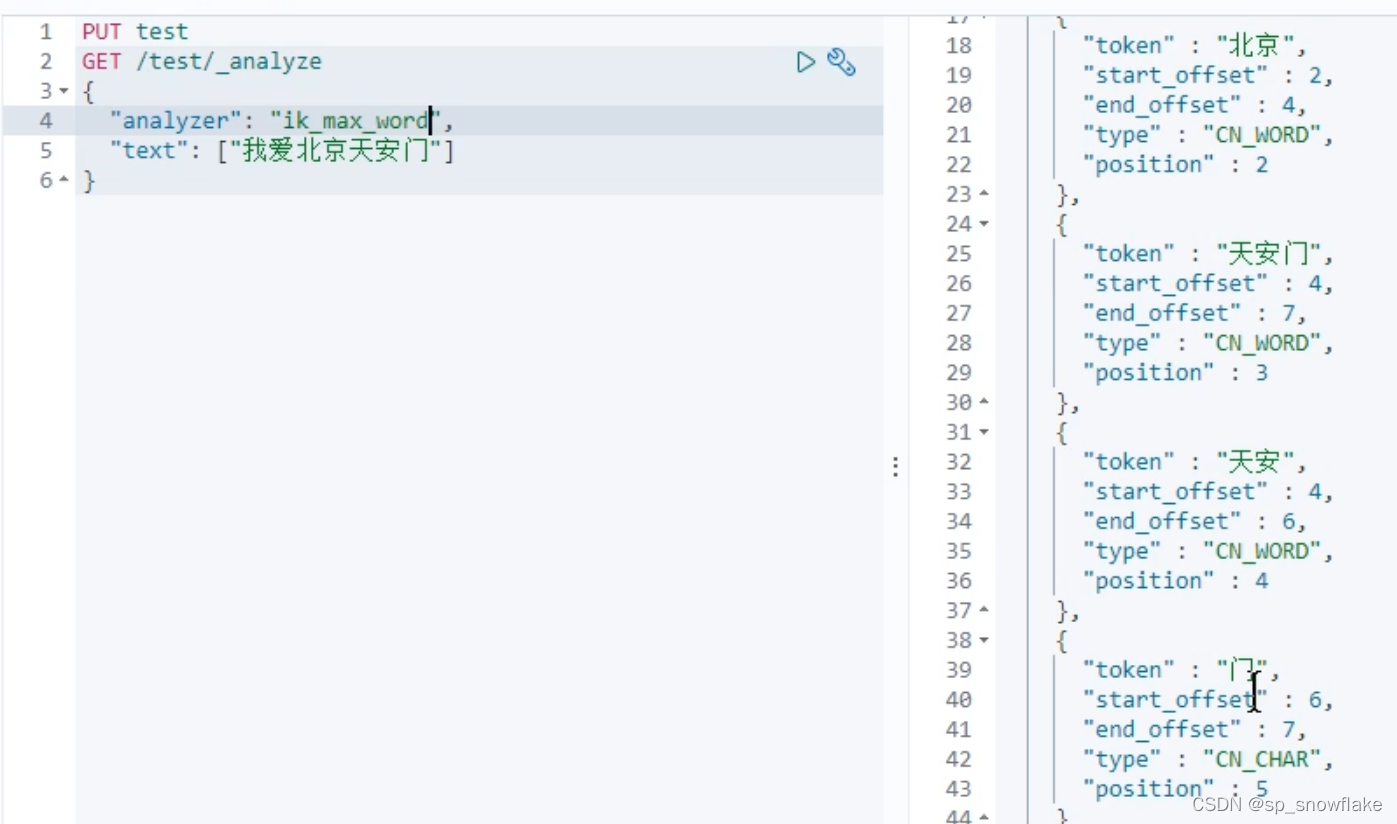
c、使用 ik_smart 分词器
素材同上:
效果:

d、网络热词等少见词
像网络热词就不能分词了:
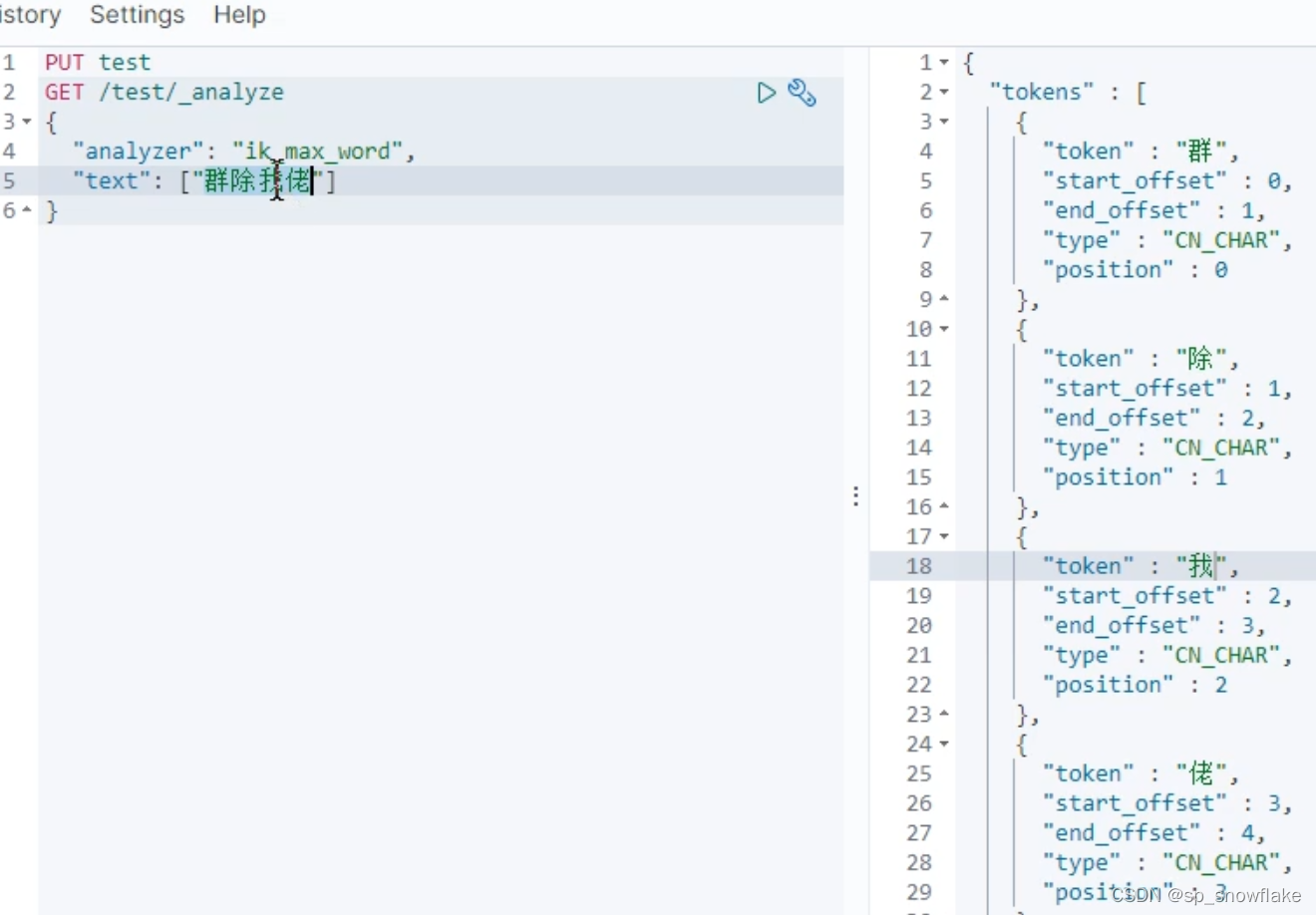
像下面这种就是分词器写好了词汇才能完整分词:
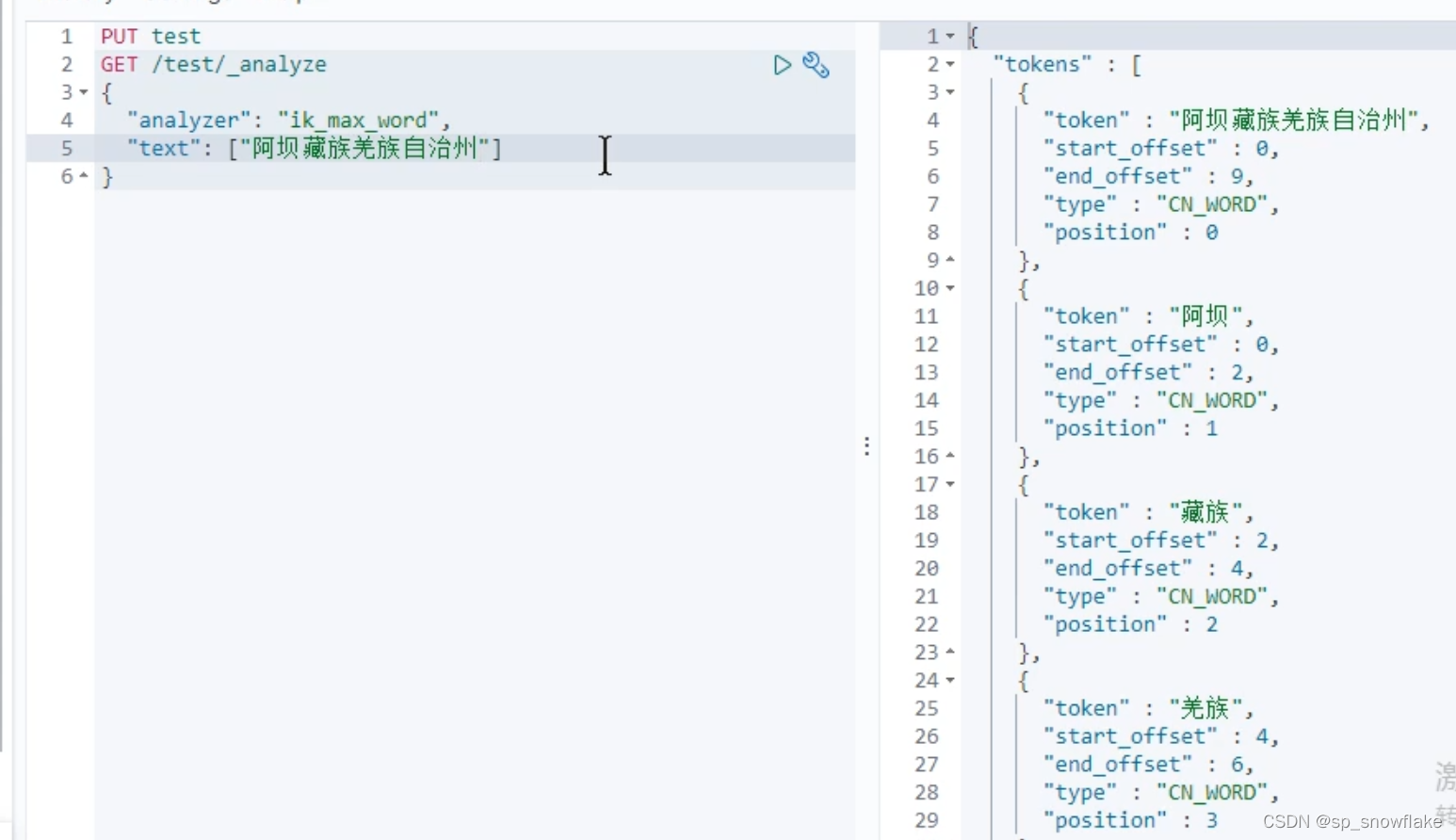
e、网络热词(使用了自定义分词库)

效果:

5、Es索引
a、创建索引
创建索引看第三小节。
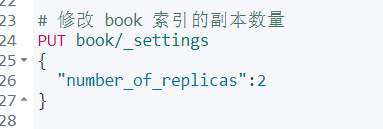
b、更新索引(修改索引副本)
前面创建 book 索引只有一个副本数量,副本数量可以更新。但是分片的数量在创建好以后就不能更新了。 因为每一条记录/文档存储到哪里都是根据现有的索引算出来的,所以一旦分片的数量变化了会导致后面搜索搜不到想要的记录。
可以通过下面命令来更新副本数量:
结果:
c、向索引中写入文档
向索引中写入文档,并赋予这条记录的 id:

结果:
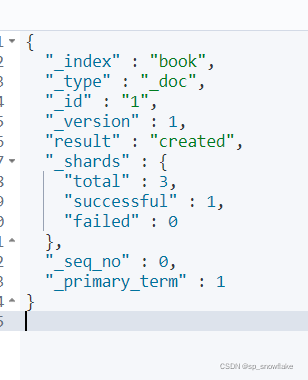
这样就向 book 索引里面添加了一条记录。
然后查看 head 插件:
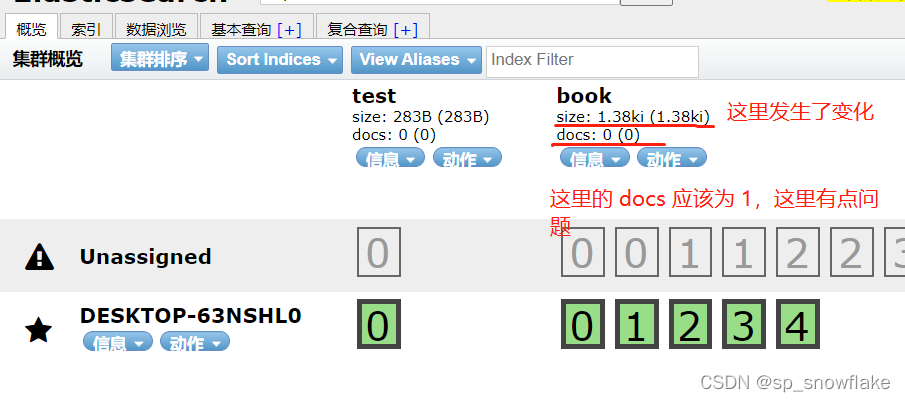
docs 应该是没有加载出来的原因,所以才显示 0。
可以点击数据浏览里面查看信息:
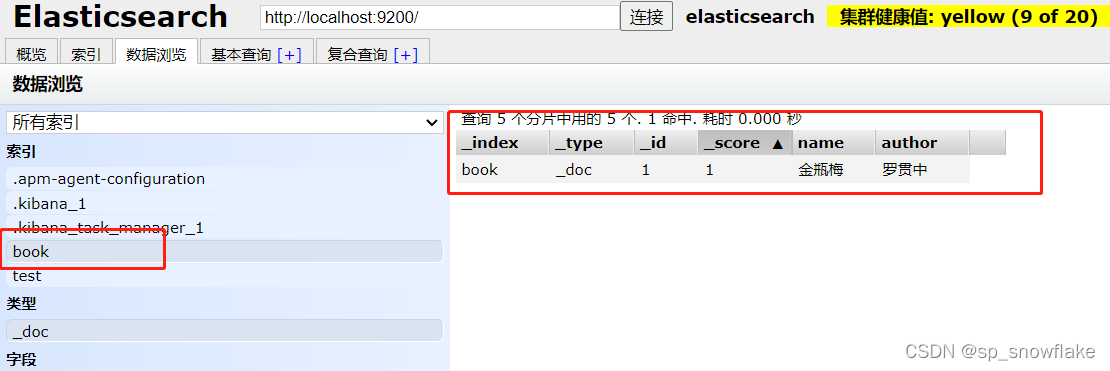
d、修改索引的读写权限
默认情况下,索引是具备读写权限的,当然这个读写权限可以关闭。
例如,关闭索引的写权限:

关闭之后,就无法添加文档了。关闭了写权限之后,如果想要再次打开,方式如下:

其他类似的权限有:
- blocks.write
- blocks.read
- blocks.read_only
e、查看索引

f、删除索引
(1)通过 head 插件删除索引
head 插件可以删除索引:
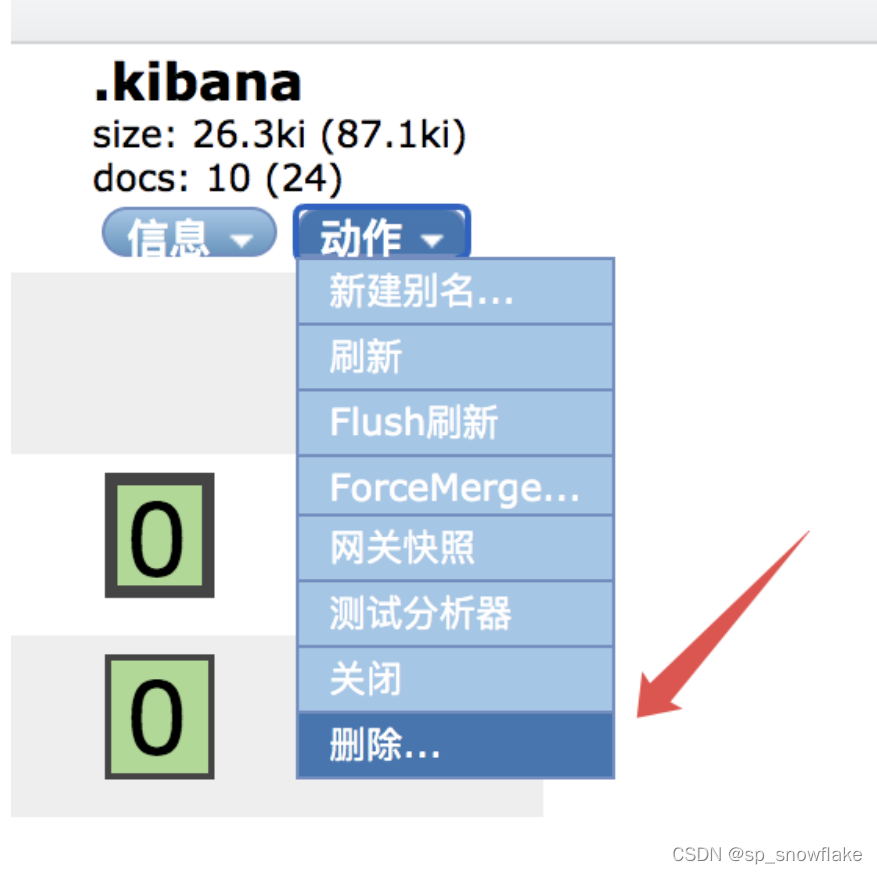
(2)通过请求删除索引
请求删除如下:
DELETE test
删除一个不存在的索引会报错。
g、索引打开/关闭

当然,可以同时关闭/打开多个索引,多个索引用 , 隔开,或者直接使用 _all 代表所有索引。
h、复制索引
索引复制,只会复制数据,不会复制索引配置。

复制的时候,可以添加查询条件。
i、索引别名(增删查)
(1)创建别名
可以为索引创建别名,如果这个别名是唯一的,该别名可以代替索引名称(前提是这个索引要存在的情况下才能创建别名):

可以在创建别名的同时添加其他查询条件,这样就可以根据索引的名字或者索引的别名通过设置好的查询条件去查询。
然后看到 head 插件,可以看到别名:

(2)删除别名
点击 b 那里的叉叉,就可以删除别名。
将 add 改为 remove 就表示移除别名:

(3)查看 索引/集群 别名

j、put 新建文档(补充一些信息和版本号的用途)
关于文档这一块上面讲过了,这里补充一些:
put 请求可以添加索引也可以更新索引;当没有这个索引的时候就是添加索引。


- _index 表示文档索引。
- _type 表示文档的类型。
- _id 表示文档的 id。
- _version 表示文档的版本(更新文档,版本会自动加 1,针对一个文档的)。
- result 表示执行结果。
- _shards 表示分片信息。
- _seq_no 和 _primary_term 这两个也是版本控制用的(针对当前 index)。
当更新当前文档时,版本号会自增:

结果:
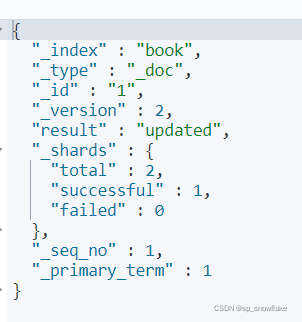
这个版本号可以在并发控制的时候,就可以利用版本号,去防止并发协作的线程不安全。比如:当刚拿到的时候是版本号 2,修改完还没有提交发现版本号变成 3,说明有人修改过了,就放弃这一次的操作。
result 显示的是 updated,意思是这一次是更新。
total 显示的是2,成功 1 个,失败 0 个。因为 book 有一个副本,实际上是往两个地方写,但是有一个副本操作不了,所以显示的是成功 1 个。
下面的 _seq_no 和 _primary_term 也是做版本并发控制的。
k、post 新建文档

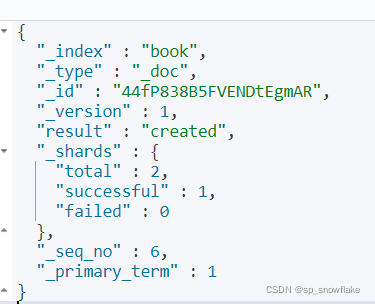
可以看到这里的 id 跟 put 方式不同,因为 post 方式不需要指定 id,会自动生成 id。
当然也可以按照 put 的方式去写,同样是有效,且也有更新的效果。
l、查询文档
(1)查看文档的信息
这里先简单的通过 id 来查询文档(有些复杂的效果后面文章再介绍):
结果:

如果查询不存在的文档,结果:

false 表示没有查到。
(2)批量查询文档

结果:
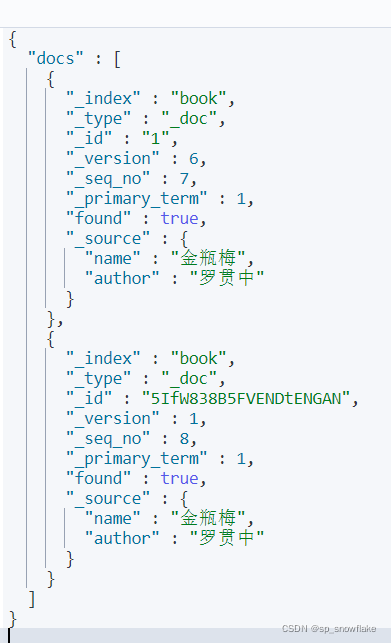
(3)查看文档是否存在
如果仅仅只是想探测某一个文档是否存在,可以使用 head 请求:

如果文档存在,响应如下:

如果文档不存在,响应如下:
m、文档更新(通过脚本语言更新)
前面说过 put 请求有创建和更新功能,但这种更新会把文档覆盖掉。
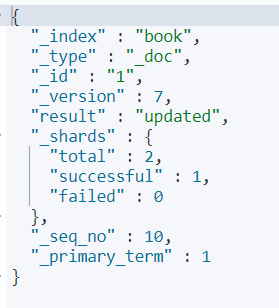
大多数时候,我们只是想更新文档的某个字段,这个可以通过脚本(painless)来实现:
painless 脚本是 Es 内置的一种脚本,通过这个脚本可以动态的更新:

结果:
注意:
1、ctx 代表的是(可以简单理解为):

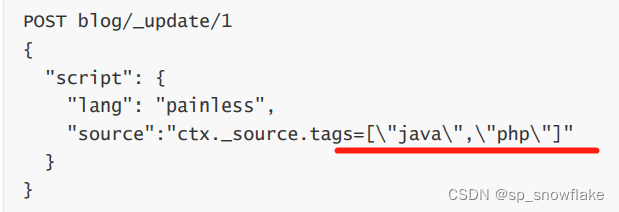
2、如果直接这样写 ctx._source.name=xxx,这样需要转义,有点麻烦,所以才有后面的 params 那些内容。
转义是啥?就比如这种:
3、这种更新不能用 put 请求,只能 post 请求。
也可以通过这种方式向文档中添加字段:
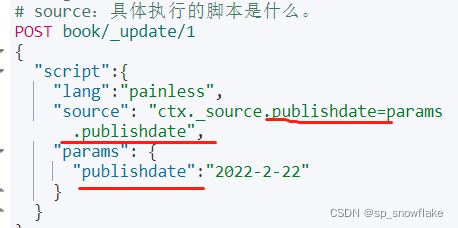
结果:
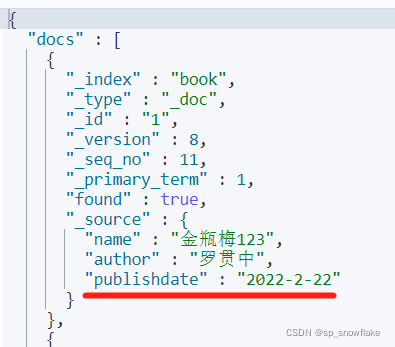
n、脚本语言的其他操作
通过这个脚本语言还可以做其他事,比如修改数组、使用 if else:

上图的 if else:如果包含 java,就把这条记录删掉,否则什么都不做。
注意:这种通过脚本方式去操作的,即便是 post 请求,也要带上 id。
o、查询更新
通过条件查询找到文档,然后再去更新:

然后把 java 改成 python:

结果:

p、删除文档
(1)根据 id 删除
从索引中删除一个文档。
删除一个 id 为 TuUpmHUByGJWB5WuMasV 的文档。

如果在添加文档时指定了路由,则删除文档时也需要指定路由,否则删除失败。
q、查询删除
查询删除是 POST 请求。
例如删除索引 blog 中 title 包含 666 的文档:

r、副本
es 是一个分布式系统,当我们存储一个文档到 es 上之后,这个文档实际上是被存储到 master 节点中的某一个主分片上。
新建一个索引:
然后添加一条记录:

文档保存成功后,可以查看该文档被保存到哪个分片中去了:

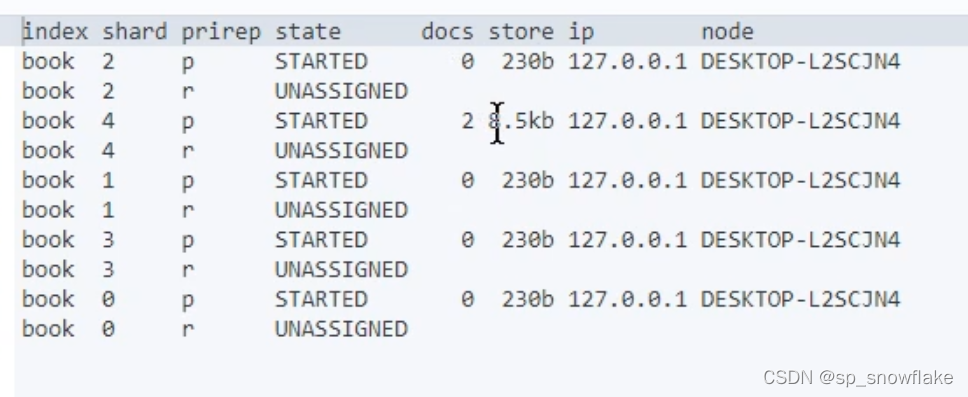
prirep 下面的 p 和 r:p 是主分片,r 是副本分片。
state:状态。STARTED 是 ok 的,另外那个就是不行的意思。
docs 找到为 2 的那一行,意思是刚刚保存的两条记录都放到 4 号分片里面。
那么 es 中到底是按照什么样的规则去分配分片的?
es 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个主分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards
routing 可以是一个任意字符串,es 默认是将文档的 id 作为 routing 值,通过哈希函数根据 routing 生成一个数字,然后将该数字和分片数取余,取余的结果就是分片的位置。
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。但是他有一个很大的劣势,就是查询时候无法确定文档的位置,此时它会将请求广播到所有的分片上去执行。另一方面,使用默认的路由模式,后期修改分片数量不方便。
像刚刚都保存到分片 4 上,是根据 id 为1 来取余;现在是根据 2 来取余,是找不出来的:


如果是 1 的话:

就可以找得到:

如果不指定 routing ,则会查找的慢一些,指定了正确的 routing ,则查找的快一些。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)