使用Flume消费Kafka数据到HDFS (亲测好用)
1.概述对于数据的转发,Kafka是一个不错的选择。Kafka能够装载数据到消息队列,然后等待其他业务场景去消费这些数据,Kafka的应用接口API非常的丰富,支持各种存储介质,例如HDFS、HBase等。如果不想使用Kafka API编写代码去消费Kafka Topic,也是有组件可以去集成消费的。下面笔者将为大家介绍如何使用Flume快速消费Kafka Topic数据,然后将消费后的数据转发到
1.概述
对于数据的转发,Kafka是一个不错的选择。Kafka能够装载数据到消息队列,然后等待其他业务场景去消费这些数据,Kafka的应用接口API非常的丰富,支持各种存储介质,例如HDFS、HBase等。如果不想使用Kafka API编写代码去消费Kafka Topic,也是有组件可以去集成消费的。下面笔者将为大家介绍如何使用Flume快速消费Kafka Topic数据,然后将消费后的数据转发到HDFS上。
2.内容
在实现这套方案之间,可以先来看看整个数据的流向,如下图所示:
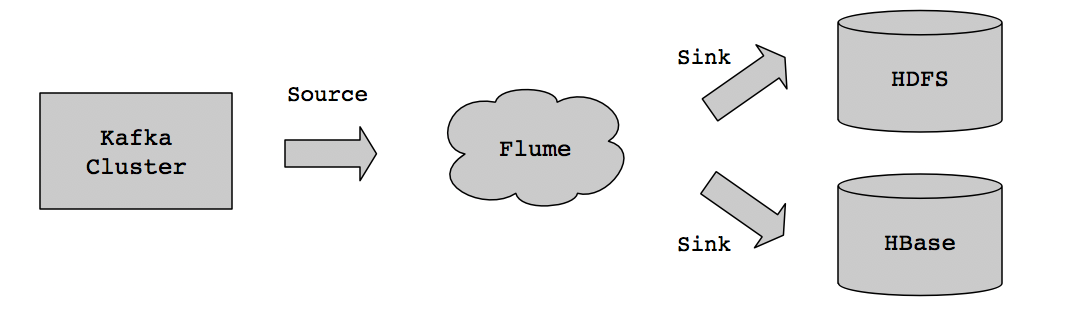
业务数据实时存储到Kafka集群,然后通过Flume Source组件实时去消费Kafka业务Topic获取数据,将消费后的数据通过Flume Sink组件发送到HDFS进行存储。
2.1 准备基础环境
按照上图所示数据流向方案,需要准备好Kafka、Flume、Hadoop(HDFS可用)等组件。
2.1.1 启动Kafka集群并创建Topic
Kafka目前来说,并没有一个批量的管理脚本,不过我们可以对kafka-server-start.sh脚本和kafka-server-stop.sh脚本进行二次封装。代码如下所示:
#! /bin/bash # Kafka代理节点地址, 如果节点较多可以用一个文件来存储 hosts=(dn1 dn2 dn3) # 打印启动分布式脚本信息 mill=`date "+%N"` tdate=`date "+%Y-%m-%d %H:%M:%S,${mill:0:3}"` echo [$tdate] INFO [Kafka Cluster] begins to execute the $1 operation. # 执行分布式开启命令 function start() { for i in ${hosts[@]} do smill=`date "+%N"` stdate=`date "+%Y-%m-%d %H:%M:%S,${smill:0:3}"` ssh hadoop@$i "source /etc/profile;echo [$stdate] INFO [Kafka Broker $i] begins to execute the startup operation.;kafka-server-start.sh $KAFKA_HOME/config/server.properties>/dev/null" & sleep 1 done } # 执行分布式关闭命令 function stop() { for i in ${hosts[@]} do smill=`date "+%N"` stdate=`date "+%Y-%m-%d %H:%M:%S,${smill:0:3}"` ssh hadoop@$i "source /etc/profile;echo [$stdate] INFO [Kafka Broker $i] begins to execute the shutdown operation.;kafka-server-stop.sh>/dev/null;" & sleep 1 done } # 查看Kafka代理节点状态 function status() { for i in ${hosts[@]} do smill=`date "+%N"` stdate=`date "+%Y-%m-%d %H:%M:%S,${smill:0:3}"` ssh hadoop@$i "source /etc/profile;echo [$stdate] INFO [Kafka Broker $i] status message is :;jps | grep Kafka;" & sleep 1 done } # 判断输入的Kafka命令参数是否有效 case "$1" in start) start ;; stop) stop ;; status) status ;; *) echo "Usage: $0 {start|stop|status}" RETVAL=1 esac
启动Kafka集群后,在Kafka集群可用的情况下,创建一个业务Topic,执行命令如下:
# 创建一个flume_collector_data主题 kafka-topics.sh --create --zookeeper dn1:2181,dn2:2181,dn3:2181 --replication-factor 3 --partitions 6 --topic flume_collector_data
2.2 配置Flume Agent
然后,开始配置Flume Agent信息,让Flume从Kafka集群的flume_collector_data主题中读取数据,并将读取到的数据发送到HDFS中进行存储。配置内容如下:
# ------------------- define data source ---------------------- # source alias agent.sources = source_from_kafka # channels alias agent.channels = mem_channel # sink alias agent.sinks = hdfs_sink # define kafka source agent.sources.source_from_kafka.type = org.apache.flume.source.kafka.KafkaSource agent.sources.source_from_kafka.channels = mem_channel agent.sources.source_from_kafka.batchSize = 5000 # set kafka broker address agent.sources.source_from_kafka.kafka.bootstrap.servers = dn1:9092,dn2:9092,dn3:9092 # set kafka topic agent.sources.source_from_kafka.kafka.topics = flume_collector_data # set kafka groupid agent.sources.source_from_kafka.kafka.consumer.group.id = flume_test_id # defind hdfs sink agent.sinks.hdfs_sink.type = hdfs # specify the channel the sink should use agent.sinks.hdfs_sink.channel = mem_channel # set store hdfs path agent.sinks.hdfs_sink.hdfs.path = /data/flume/kafka/%Y%m%d # set file size to trigger roll agent.sinks.hdfs_sink.hdfs.rollSize = 0 agent.sinks.hdfs_sink.hdfs.rollCount = 0 agent.sinks.hdfs_sink.hdfs.rollInterval = 3600 agent.sinks.hdfs_sink.hdfs.threadsPoolSize = 30 agent.sinks.hdfs_sink.hdfs.fileType=DataStream agent.sinks.hdfs_sink.hdfs.writeFormat=Text # define channel from kafka source to hdfs sink agent.channels.mem_channel.type = memory # channel store size agent.channels.mem_channel.capacity = 100000 # transaction size agent.channels.mem_channel.transactionCapacity = 10000
然后,启动Flume Agent,执行命令如下:
# 在Linux后台执行命令 flume-ng agent -n agent -f $FLUME_HOME/conf/kafka2hdfs.properties &
2.3 向Kafka主题中发送数据
启动Kafka Eagle监控系统(执行ke.sh start命令),填写发送数据。如下图所示:
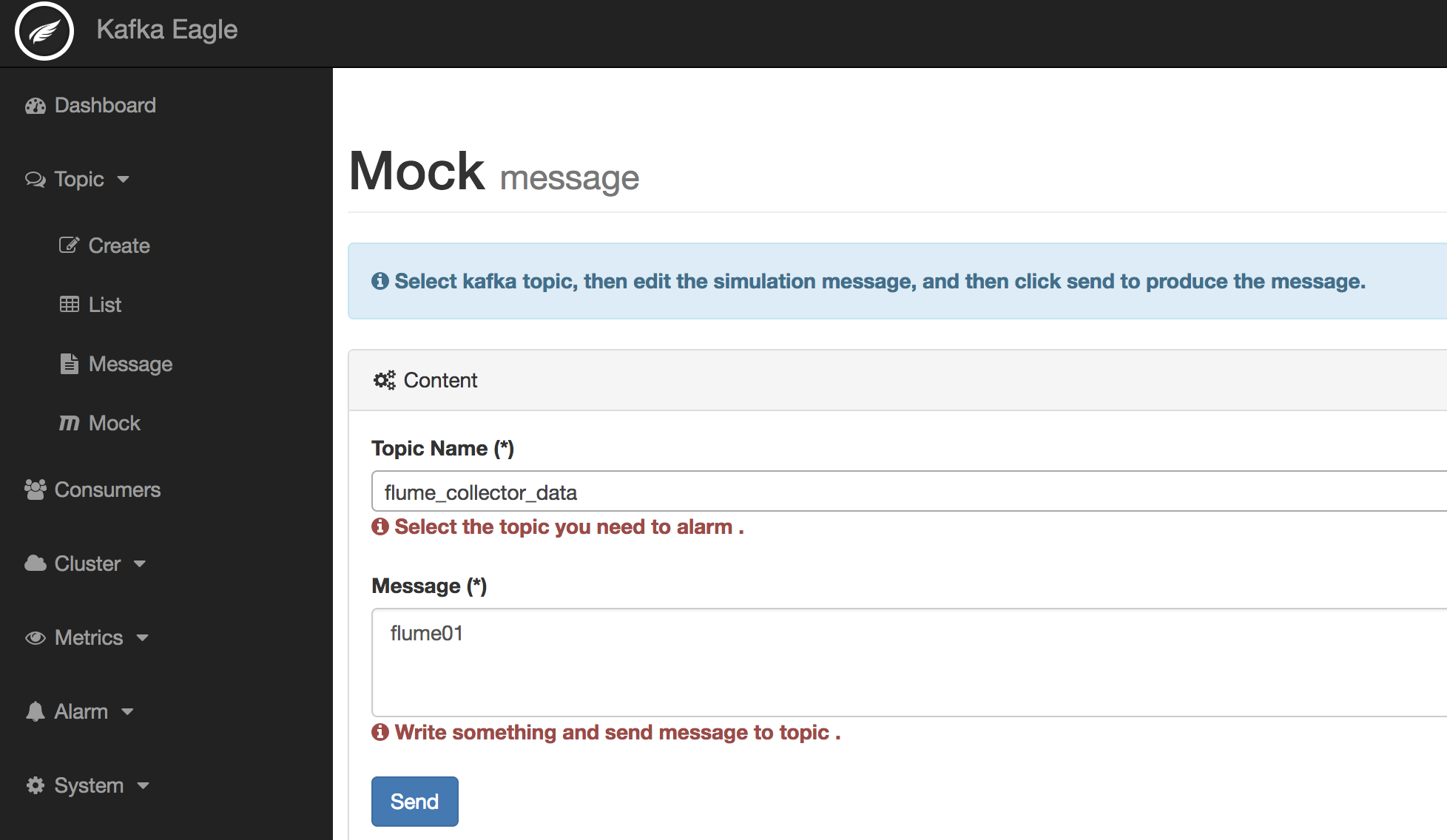
然后,查询Topic中的数据是否有被写入,如下图所示:
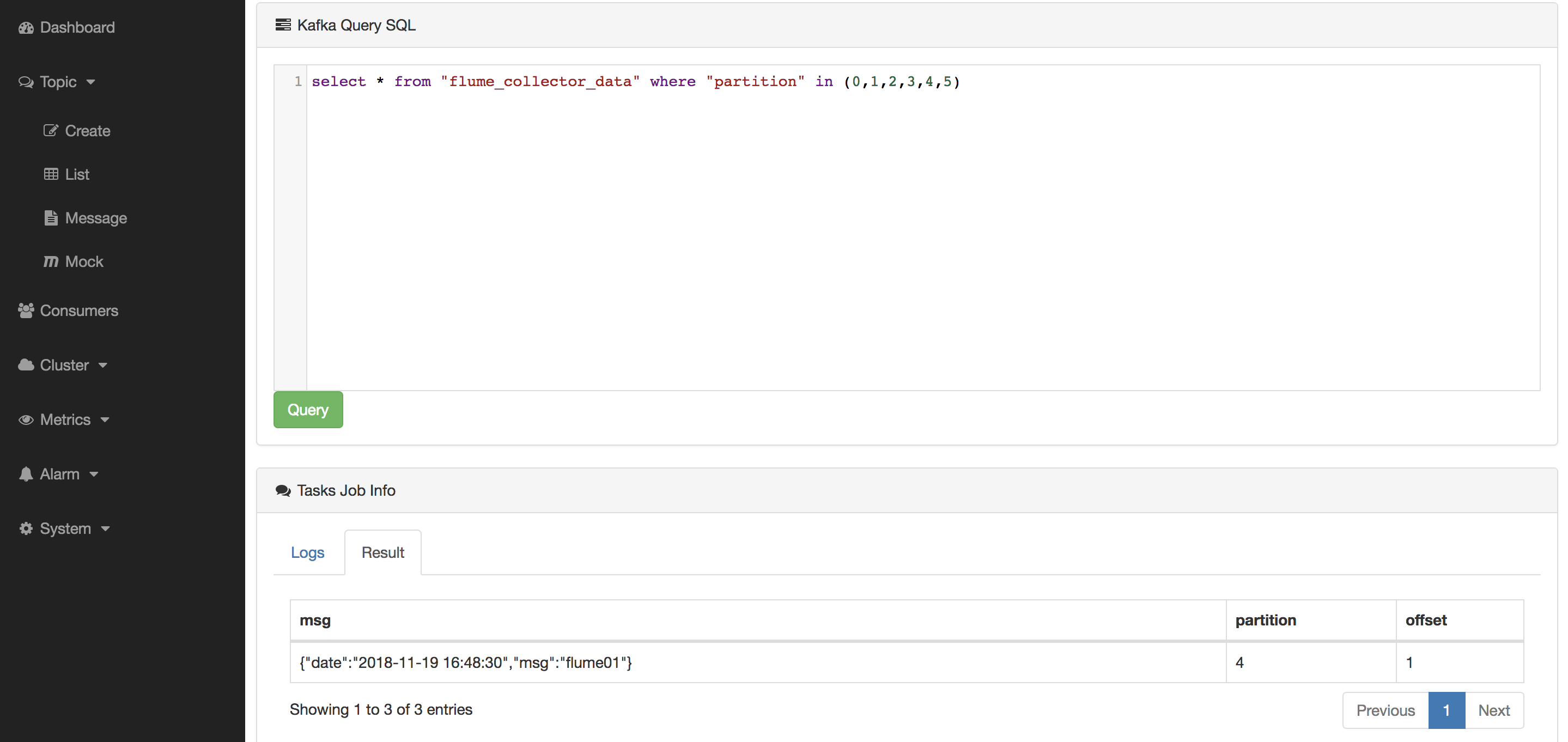
最后,到HDFS对应的路径查看Flume传输的数据,结果如下图所示:

3.Kafka如何通过Flume传输数据到HBase
3.1 创建新主题
创建一个新的Topic,执行命令如下:
# 创建一个flume_kafka_to_hbase主题 kafka-topics.sh --create --zookeeper dn1:2181,dn2:2181,dn3:2181 --replication-factor 3 --partitions 6 --topic flume_kafka_to_hbase
3.2 配置Flume Agent
然后,配置Flume Agent信息,内容如下:
# ------------------- define data source ---------------------- # source alias agent.sources = kafkaSource # channels alias agent.channels = kafkaChannel # sink alias agent.sinks = hbaseSink # set kafka channel agent.sources.kafkaSource.channels = kafkaChannel # set hbase channel agent.sinks.hbaseSink.channel = kafkaChannel # set kafka source agent.sources.kafkaSource.type = org.apache.flume.source.kafka.KafkaSource # set kafka broker address agent.sources.kafkaSource.kafka.bootstrap.servers = dn1:9092,dn2:9092,dn3:9092 # set kafka topic agent.sources.kafkaSource.kafka.topics = flume_kafka_to_hbase # set kafka groupid agent.sources.kafkaSource.kafka.consumer.group.id = flume_test_id # set channel agent.channels.kafkaChannel.type = org.apache.flume.channel.kafka.KafkaChannel # channel queue agent.channels.kafkaChannel.capacity=10000 # transaction size agent.channels.kafkaChannel.transactionCapacity=1000 # set hbase sink agent.sinks.hbaseSink.type = asynchbase # hbase table agent.sinks.hbaseSink.table = flume_data # set table column agent.sinks.hbaseSink.columnFamily= info # serializer sink agent.sinks.hbaseSink.serializer=org.apache.flume.sink.hbase.SimpleAsyncHbaseEventSerializer # set hbase zk agent.sinks.hbaseSink.zookeeperQuorum = dn1:2181,dn2:2181,dn3:2181
3.3 创建HBase表
进入到HBase集群,执行表创建命令,如下所示:
hbase(main):002:0> create 'flume_data','info'
3.4 启动Flume Agent
接着,启动Flume Agent实例,命令如下所示:
# 在Linux后台执行命令 flume-ng agent -n agent -f $FLUME_HOME/conf/kafka2hbase.properties &
3.5 在Kafka Eagle中向Topic写入数据
然后,在Kafka Eagle中写入数据,如下图所示:
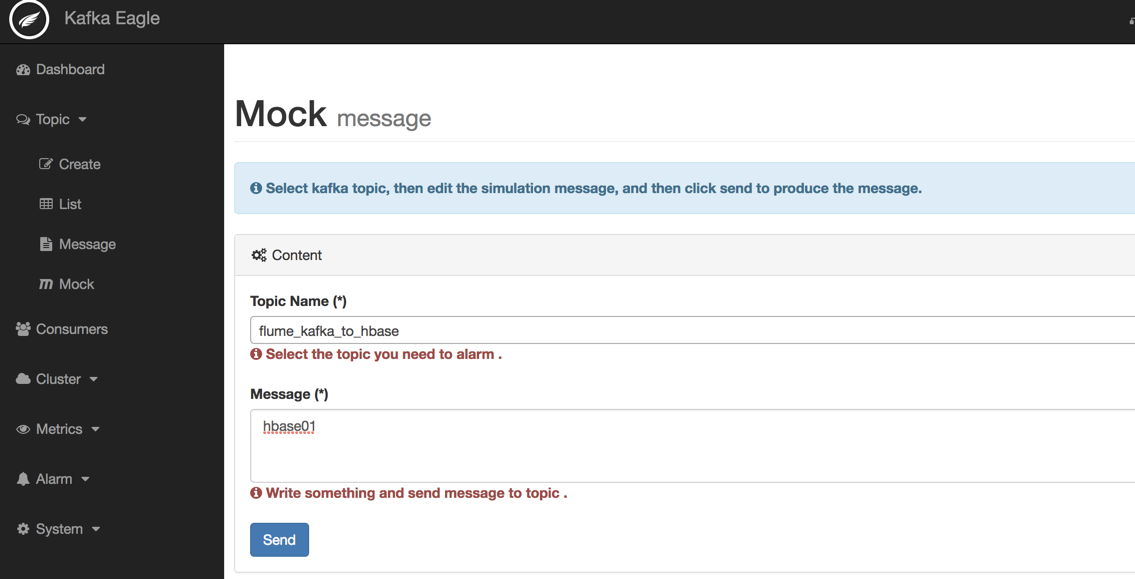
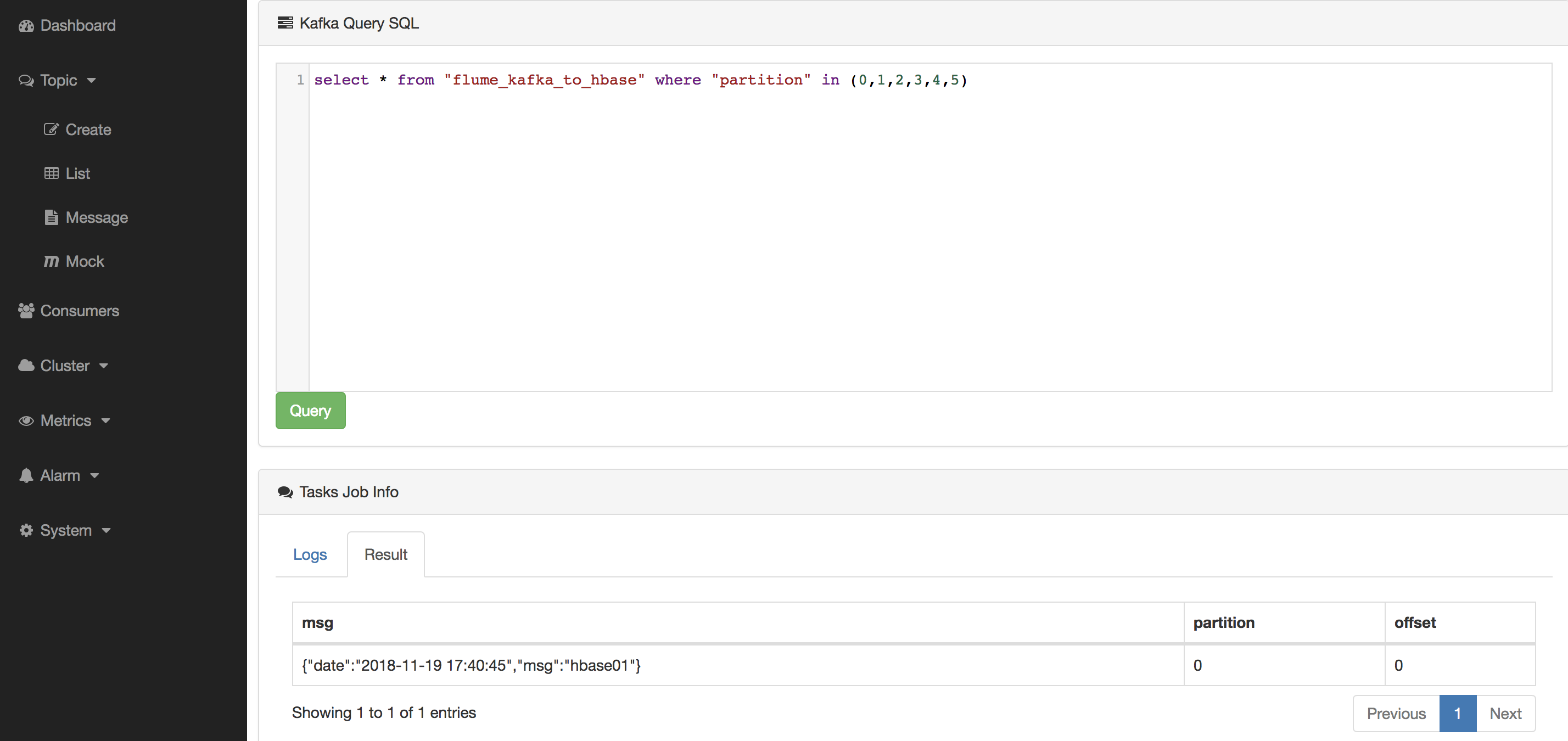
3.6 在HBase中查询传输的数据
最后,在HBase中查询表flume_data的数据,验证是否传输成功,命令如下:
hbase(main):003:0> scan 'flume_data'
预览结果如下所示:

4.总结
至此,Kafka中业务Topic的数据,经过Flume Source组件消费后,再由Flume Sink组件写入到HDFS,整个过程省略了大量的业务编码工作。如果实际工作当中不涉及复杂的业务逻辑处理,对于Kafka的数据转发需求,不妨可以试试这种方案。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)