Java开发之消息队列
简介介绍消息队列的重要性介绍Java程序员常用的Kafka消息队列介绍Kafka内部的一些机制及注意问题为什么要使用消息队列?比较常见的作用有3点,解耦、异步处理、流量削峰,这里分别一一介绍这些特点。解耦我们在设计微服务的时候经常会出现几个模块之间需要相互依赖,例如A和B服务相互依赖,那么部署一个A,必须部署一个B,导致A模块和B模块之间形成了强耦合。如果此时我们在A和B模块之间引入消息队列,那么
简介
- 介绍消息队列的重要性
- 介绍Java程序员常用的Kafka消息队列
- 介绍Kafka内部的一些机制及注意问题
为什么要使用消息队列?
比较常见的作用有3点,解耦、异步处理、流量削峰,这里分别一一介绍这些特点。
解耦
我们在设计微服务的时候经常会出现几个模块之间需要相互依赖,例如A和B服务相互依赖,那么部署一个A,必须部署一个B,导致A模块和B模块之间形成了强耦合。如果此时我们在A和B模块之间引入消息队列,那么A可以不用依赖B,只需要A和B之间规定通用的消息格式即可,这样A和B就解耦了,这样以后别的模块需要依赖A或B,可以对接消息队列的格式即可了,完全不用关心A和B服务到底是什么接口了,也就不依赖A和B的实现方式。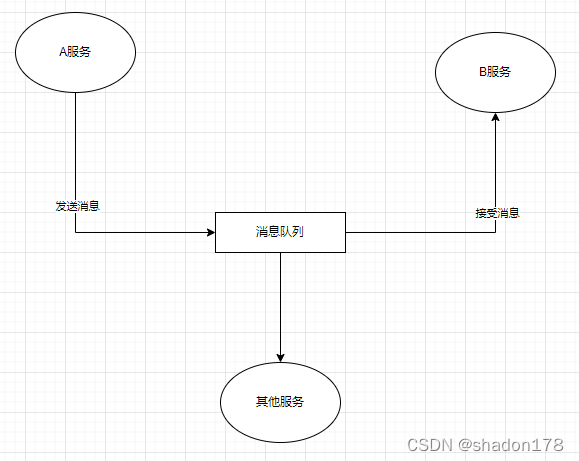
异步
例如A服务要执行一些耗时的操作并且还要处理客户请求,这是可以将耗时的操作发给消息队列,处理耗时操作的服务就可以单独去处理耗时操作,这样A服务就不用等待耗时操作完成之后才响应客户了。
流量削峰
如果服务的最高并发只能处理5000,但是偶尔瞬间的并发用户可能多于5000,这个时候可以使用消息队列将多于5000的请求缓存起来,当进程空闲出来再处理消息队列中的请求,防止高并发的用户请求压垮服务。
总结
服务解耦和异步处理应该是经常会用到的功能,至于流量削峰在一般情况下很少使用。我在项目中用到消息队列的场景很多,例如日志收集、监控指标的收集、数据同步、微服务模块之间的解耦等等。因此,在Java开发项目中可以说是消息队列无处不在,强烈建议每个Java开发必须熟悉1到2给常见的消息队列服务,并且明白其中的各个原理和特性。
Kafka消息队列
基本概念
生产者
发送数据到kafka的进程统称为生产者
消费者
消费kafka中的数据的进程统称为消费者
Topic
可以理解为一张存放队列数据的表,每一个存进来的数据都会有key和value,且没有格式限制,只要不超过规定的数据大小,基本可以存放各种类型的数据。
副本和分区
因为kafka也是高可用的,因此又引入了副本和分区的概念,每个topic的数据可以进行分区,将数据分发给不同的分区(这里有分区策略,待会细讲。),每个分区负责部分数据,每个分区内的数据按投递的顺序排列。每个分区又可以复制出多个副本,副本就可以分配给不同的节点,从而减少了热点数据都由一个节点来处理的问题。副本和分区基本上是高可用的标准配置,例如常见的HDFS、ElasticSearch、Redis等等都有这个概念,这里就不细说。
每个副本有leader与follower角色,leader负责读和写,follower只负责从leader同步过来数据,不能对外提供服务,只会存在一个leader和多个follower。当leader挂了的时候,会根据选举算法从新从follower中选择一个成为leader。
Offset
每个分区都有自己的offset,用来标识数据的位置,是一个自增的id值。每一个被写入的数据都会分配一个自增的offset值来表示位置,如图所示: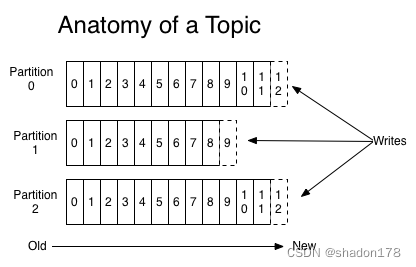
Broker
可以理解为kafka集群中的每个节点,每一个单独的节点就是一个broker,集群中的broker是通过zookeeper来协调的。
GroupId
消费组,每个组内的消费者共同消费数据,但组内的每个消费者只会消费一个特定分区,组内的消费者不会同时消费相同分区的数据。不同消费组互不干扰。每个消费组内的消费者默认会均匀的分配分区,例如某topic有p0,p1,p2,p3总共4个分区,那么消费组内分区的分配方式如下: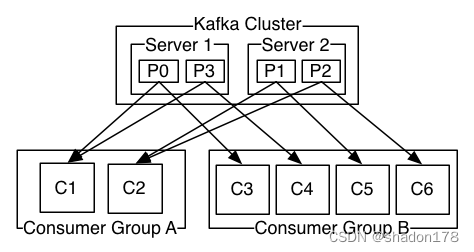
C1消费组只会消费P0和P3分区的数据,不会消费其他分区的数据。消费组A和消费组B之间互不干扰,C1消费了数据,并不影响C3继续消费相同数据。
常见问题
分区和副本分配策略
用分区号对broker总数取余来分配的,例如分区3个,broker2,那么有一个broker会分配到2给分区,其他broker只会分配到一个分区。如果分区数为3,broker为4,那么其中一个borker不会分配到该分区,其他broker会分配到一个分区。
副本的分配策略很简单,主要将相同分区的不同副本尽量划分给不同的borker节点,因此副本数量不要超过broker节点的数量,否则会直接抛错。
生产者分区策略
生产者产生的数据会投递到kafka中,kafka会根据响应的策略将数据投递到指定的分区中。
- 生产者指定分区:这种方式比较简单,通过配置指定分区,数据将全部投递到指定分区中。
- 默认分区器:如果存在key则将key取hash然后与分区数取余获取分区号;如果没有key,则采用粘性分区策略,也就是先随机选择一个分区,一直使用直到达到时间和容量要求,则切换其他分区,依次循环。
- 轮询策略:依次往不同的分区写入数据。
- 随机策略:随机往不同的分区写入数据。
消费者分区策略
消费者分区策略都是基于同一个消费组而言的,不同的消费组可以使用不用的策略,相互之间没有任何影响。
- 消费者指定分区:则一直消费该分区的数据。
- Range strategy 范围策略:例如有5个分区,消费组A内有2给消费组A1,A2,那么A1分配(0,1,2),A2分配(3,4);如果有4给分区,那么A1和A2都有2给分区。
再平衡 rebanlance
再平衡导致kafka需要给消费组内的所有消费组重新分配分区,发现再平衡的条件有如下几种:
- 同一个消费组内新增消费者
- 消费者离开当前所属的消费组,包括节点宕机或卡死等。
- 主题新增分区
Kafka数据清除策略
可以配置定期清除topic中的数据。
生产者数据如何确保数据已经投递成功?
消息的一致性保证是一个问题权衡的问题,没有一种方法能解决所有问题。我们可以发送一条确认一条,但是效率低;我们也可以积累一批数据再一起发送到kafka中,这又存在数据重传的问题。因此我们需要权衡数据丢失、数据投递顺序、性能问题。
- 数据顺序,如果要保证数据投递的顺序,那么只能使用一个分区,所有的数据都投递到该分区中(当然这里也可以利用数据的特性进行分区)。每个数据必须等前面的数据投递成功才能投递下一个数据,一断某一个出错,应该中断整个链路,禁止后续消息继续投递。
- 数据丢失问题
可以使用参数来控制,但是会牺牲性能,需要根据实际情况衡量,重要参数如下:
acks=0: 生产者不用等待服务器的回复,容易丢失数据。
acks=1: 生产者只需要等待leader成功回复即可,如果follower没有收到数据且切换成了leader,也存在丢失数据的可能,但比第一种情况要小很多。
acks=all: 所有副本都收到成功的回复消息,一致性高,但是延迟也高。注意,这种方式一定要结合副本来使用才安全,否则如果只有一个leader节点,也无法真正的保证消息不丢失。
retries: 生产者重试次数。
producer.type=sync/async 同步或异步投递数据
-
数据重复问题
使用同步模式下,基本不存在数据重复问题。 -
总结
根据实际业务情况,调整核心参数,达到最优的解决方案,记住没有银弹能解决所有问题,这个一个取舍问题。
消费者如何确保成功消费?
重要参数:
enable.auto.commit: 是否自动提交
自动提交:默认情况,消费者每5秒自动提交一次offset。例如提交了一次offset后,此时offset=5,接下来的5秒内消费了2条数据且立马发生rebanlance,还没来得及提交offset,此时会导致这2条数据需要重新消费。
手动提交(同步):每次消费一条数据后手动提交offset,只有提交成功后才会继续消费下一条数据。这种方式可以保证正确的唯一消费数据,但是由于每消费一条数据都需要手动提交offset,在性能上可能会差一点。
手动同步提交自带重试功能,可以应付简单的网络异常情况。
手动提交(异步):异步提交不会阻塞后续的消费,由单独的进程去提交offset。异步提交也不会重试。异步提交失败,只能通过回调记录异常数据。
如何实现Exactly Once语义
如果要实现真正的exactly once的语义是很难的,这会涉及到很复杂的各种情况。如果大家想弄懂分布式后存在哪些问题,推荐书籍《数据密集型应用系统设计》,详细的讲解了分布式后存在的各种问题。为了实现exactly once可以在消费者实现幂等操作,即能容忍重复消费,这样消费者可以直接使用自动提交,提高处理性能。这种实现方式是公认的、容易实现的方式。
总结
kafka是一款比较优秀的消息队列工具,在使用之前一定要先了解各个功能特点,结合自身业务特点,有选择的设置合适的参数,从而发挥kafka优势和性能。经常听同时抱怨kafka丢失等问题,只要理解以上说的各个点,合理的设置生产者和消费者参数,不可能丢失数据的,请大家放心使用。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)