Logstash:用 Filebeat 把数据传入到 Logstash
在今天的讲座里,我们来讲述一下如何把Filebeat里的数据传入到Logstash之中。在做这个练习之前,我想信大家已经安装我之前的文章“如何安装Elastic栈中的Logstash”把Logstash安装好。之前,我们介绍了一这样的一幅图:如上图所示,我们可以直接把beats里的数据直接传入到Elasticsearch,也可以直接接入到Logstash之中。数据采集流程:...
在今天的讲座里,我们来讲述一下如何把 Filebeat 里的数据传入到 Logstash 之中。在做这个练习之前,我想信大家已经安装我之前的文章 “如何安装Elastic栈中的Logstash” 把 Logstash 安装好。
之前,我们介绍了一这样的一幅图:
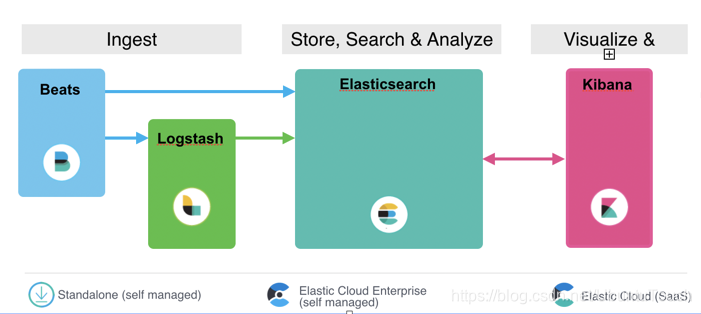
如上图所示,我们可以直接把 beats 里的数据直接传入到 Elasticsearch,也可以直接接入到 Logstash 之中。
数据采集流程:
- Beats 采集(Filebeat/Metricbeat)–> Elasticsearch –> Kibana
- Beats 采集(Filebeat/Metricbeat)–> Logstash –> Elasticsearch –> Kibana
既然 Beats 可以直接把数据直接写入到 Elasticsearch 之中,为什么我们还需要 Logstash 呢?这主要的原因是因为 Logstash 有丰富的 filter 供我们使用,可以帮我们加工数据,并最终把我们的数据转为我们喜欢的格式。Beats 在 ELK 中是一个非常轻量级的应用。是用 go 语言写的。它不需要有很强大的运行环境来运行。它通常运行于客户端中。
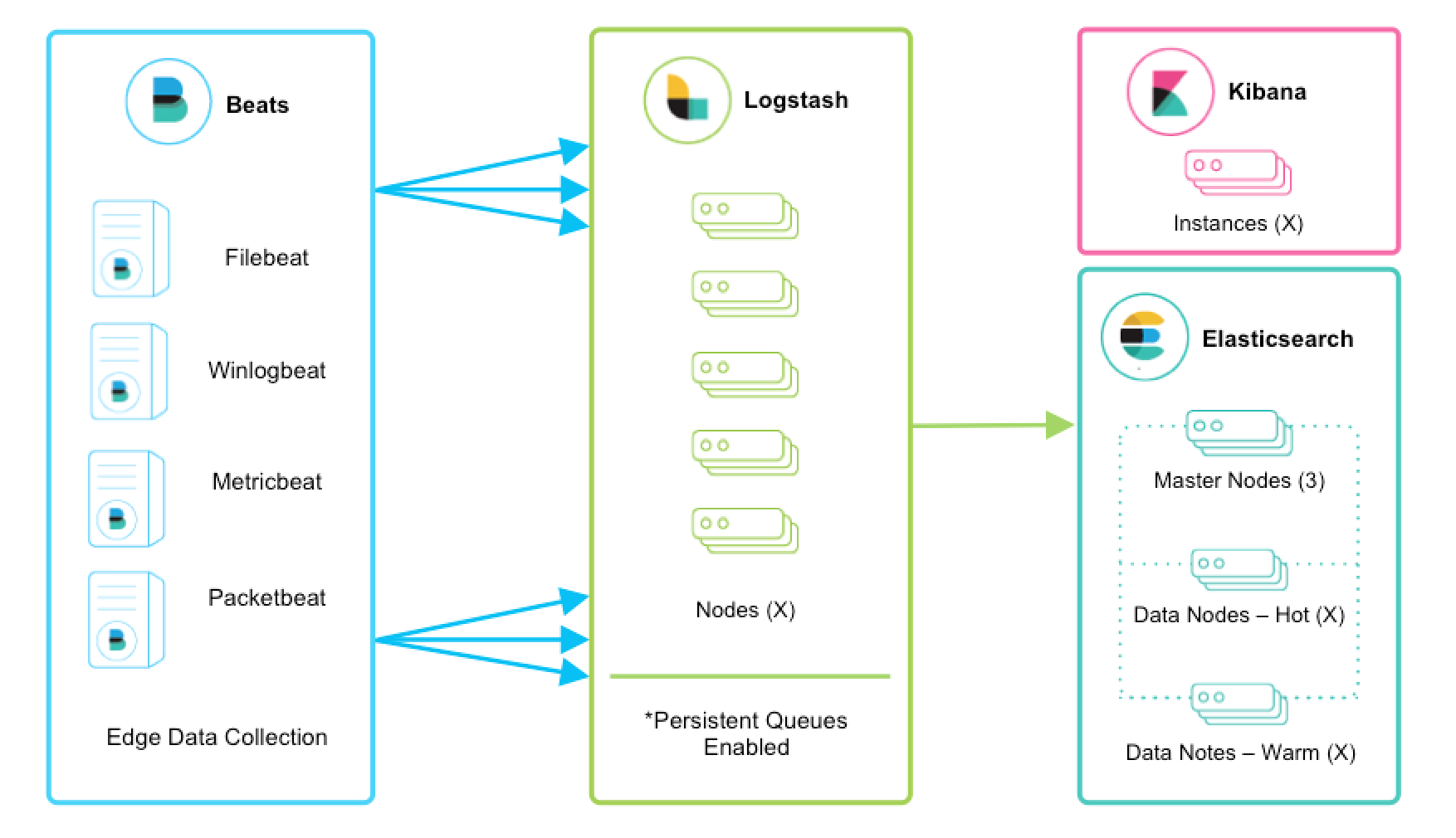
建立样本文件
为了方便我们的说明,我们先创建一个简单的 sample.log 文件。这个文件可以位于你电脑的任何位置。为了方便,我们把这个文件存于 Filebeat 的安装的根目录下。它的内容如下:
sample.log
2019-09-09T13:00:00Z Whose woods these are I think I know.
2019-09-09T14:00:00Z His house is in the village, though;
2019-09-09T15:00:00Z He will not see me stopping here
2019-09-09T16:00:00Z To watch his woods fill up with snow.
2019-09-09T17:00:00Z My little horse must think it queer
2019-09-09T18:00:00Z To stop without a farmhouse near
2019-09-09T19:00:00Z Between the woods and frozen lake
2019-09-09T20:00:00Z The darkest evening of the year.
2019-09-09T21:00:00Z He gives his harness bells a shake
2019-09-09T22:00:00Z To ask if there is some mistake.
2019-09-09T23:00:00Z The only other sound's the sweep
2019-09-09T00:00:00Z Of easy wind and downy flake.
2019-09-09T01:00:00Z The woods are lovely, dark, and deep,
2019-09-09T02:00:00Z But I have promises to keep,
2019-09-09T03:00:00Z And miles to go before I sleep,
2019-09-09T04:00:00Z And miles to go before I sleep这是一首英文诗。
配置 Logstash
我们可以在你电脑的任何一个位置建立一个 Logstash 的配置文件,比如,我们建立一个叫做 logstash-beats.conf 的文件:
logstash-beats.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
filter {
grok {
match => [
"message", "%{TIMESTAMP_ISO8601:timestamp_string}%{SPACE}%{GREEDYDATA:line}"
]
}
date {
match => ["timestamp_string", "ISO8601"]
}
mutate {
remove_field => [message, timestamp_string]
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
user => elastic
password => "your password"
}
stdout {
codec => rubydebug
}
}
在这里,我想来说明一下:
- 这里的 input 使用了 beat,并监听端口5044。很多 Beats 都使用一个端口,并向这个端口发送数据。在接下来的 Filebeat,我们可以看到如何配置这个端口,并发送 log 数据到这个端口
- 在 filter 的这个部分,我们首先使用 grok。它的基本语法是 %{SYNTAX:SEMANTIC}。SYNTAX 是与你的文本匹配的模式的名称。这个有点类似于正则表达式。例如,3.44 将与 NUMBER 模式匹配,55.3.244.1 将与 IP 模式匹配。SEMANTIC 是你为匹配的文本提供的标识符。针对我们的例子:
2019-09-09T13:00:00Z Whose woods these are I think I know.2019-09-09T13:00:00Z:使用 TIMESTAMP_ISO8601 匹配,并形成一个叫做 timestamp_string 的字符串。SPACE 用来匹配时间后面的空格,而剩下的部分由 GREEDYDATA 进行匹配,并存于 line 这个字符串中。比如针对我们的例子 line 就是 “Whose woods these are I think I know.” 字符串
- date 这个 filter 可以帮我们把一个字符串变成一个 ISO8601 的时间,并最终存于一个叫做 @timestamp 的字段中。如果没有这个 filter,我们可以看到最终的 @timestamp 是采用当前的运行时间,而不是在 log 里的时间
- 我们使用 mutate 过滤器把之前的 message 和 timestamp_string 都删除掉
在接下来的实验中,我们可以把上面的这些 filter 注释掉,你可以看看在输出中有什么变化。这里的 filter 是安装顺序从上到下执行的。在实际的练习中,我们可以把上面的 mutate 和 date 进行调换,我们应该看到不同的结果。
- 在 output 中,我们把数据输出到 Elasticsearch,并同时输出到 stdout,这样我们也可以在 terminal 的输出中看到输出的信息。这个也很方便我们做测试。如果大家已经安装了 x-pack 安全,可以在 Elasticsearch 中加入用户名及密码:
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-poem"
document_type => "_doc"
user => elastic
password => "YourPassword"
}
stdout {
codec => rubydebug
}
}更多关于 filter 的介绍,可以参阅我们的官方网址 “Filter plugins”。
在 Logstash 中,按照顺序执行的处理方式被叫做一个 pipeline。一个 pipeline 含有一个按照顺序执行的逻辑数据流。pipeline 从 input 里获取数据,并传送给一个队列,并接着传入到一些 worker 去处理:
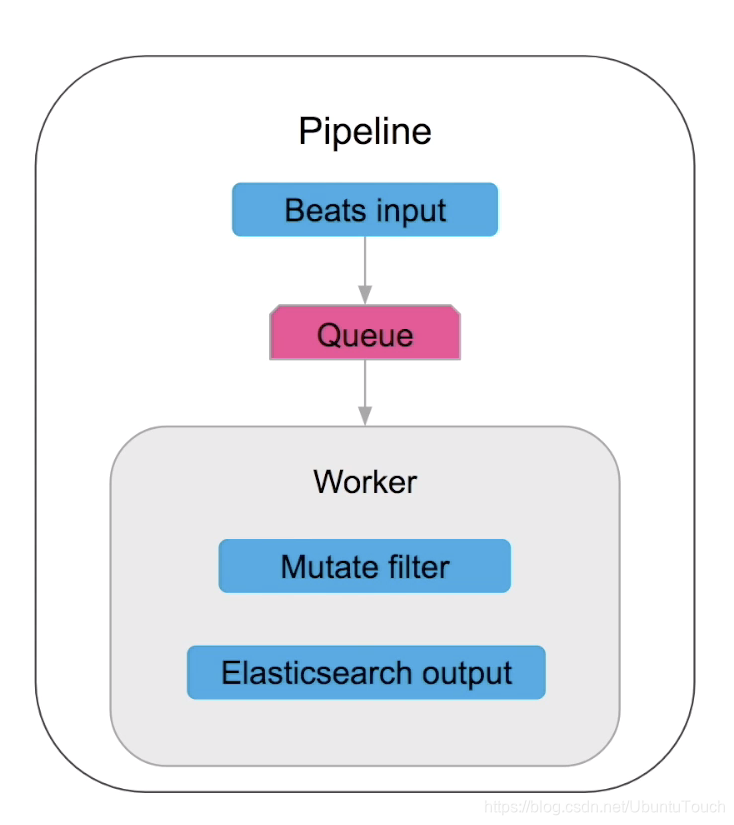
配置好 Logstash 后,我们可以使用如下的命令来执行:
$ ./bin/logstash -f ~/data/logstash-beats.conf 在这里,我把 logstash-beats.conf 放置于我 home 目录下的一个叫做 data 的子目录。大家需要根据自己的文件位置进行修改。这样我们的 Logstash 就已经运行起来了。
安装 Filebeat
deb:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-amd64.deb
sudo dpkg -i filebeat-7.3.1-amd64.debrpm:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-x86_64.rpm
sudo rpm -vi filebeat-7.3.1-x86_64.rpmmac:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-darwin-x86_64.tar.gz
tar xzvf filebeat-7.3.1-darwin-x86_64.tar.gzbrew:
brew tap elastic/tap
brew install elastic/tap/filebeat-fulllinux:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-linux-x86_64.tar.gz
tar xzvf filebeat-7.3.1-linux-x86_64.tar.gz这样我们的 Filebeat 就安装好了。请注意:由于 ELK 迭代比较快,我们可以把上面的版本 7.3.1 替换成我们需要的版本即可。
配置 Filebeat
在 Filebeat 的根目录下,我们可以发现一个叫做 filebeat.yml 的文件。它里面有些描述可以帮我们理解如何配置这个文件。为了方便,我们直接把这个文件改成如下的内容:
filebeat.inputs:
- type: log
enabled: true
paths:
- ./sample.log
output.logstash:
hosts: ["localhost:5044"]这里需要注意的是之前有的文章里第一行写的是 filebeat.prospectors。经过测试在新的版本里不再适用。
我们在这里可以看到 Filebeat 会帮我们把 sample.log 文件读入,并写入到 Logstash 中。它使用了一个 5044 端口地址。这个地址在我们如下的 Longstash 配置中,我们将会使用到。我们可以通过如下的命令来运行 filebeat:
$ ./filebeat 在默认的情况下,filebeat 会自动寻找定义在 filebeat.yml 文件里的配置。如果我们的配置文件是另外的名字,我们可以通过如下的命令来执行 filebeat:
$ ./filebeat -c YourYmlFile.ymlFilebeat 的 registry 文件存储 Filebeat 用于跟踪上次读取位置的状态和位置信息。
data/registry针对.tar.gzand.tgz归档文件安装/var/lib/filebeat/registry针对 DEB 及 RPM 安装包c:\ProgramData\filebeat\registry针对 Windows zip 文件
如果我们想重新运行数据一遍,我们可以直接到相应的目录下删除那个叫做 registry 的目录即可。针对 .tar.gz 的安装包来说,我们可以直接删除这个文件:
localhost:data liuxg$ pwd
/Users/liuxg/elastic/filebeat-7.3.0-darwin-x86_64/data
localhost:data liuxg$ rm -rf registry/那么重新运行上面的 ./filebeat 命令即可。它将会重新把数据从头再进行处理一遍。这对于我们的调试来说是非常用用的。
在输出确认请求之前,Filebeat 不会考虑发新的送日志行。 由于将行传送到配置的输出的状态保留在注册表文件中,因此你可以安全地假定事件将至少一次传送到配置的输出,并且不会丢失任何数据
当我们运行完我们的 filebeat 应用,我们可以在 Logstash 的屏幕上看到:
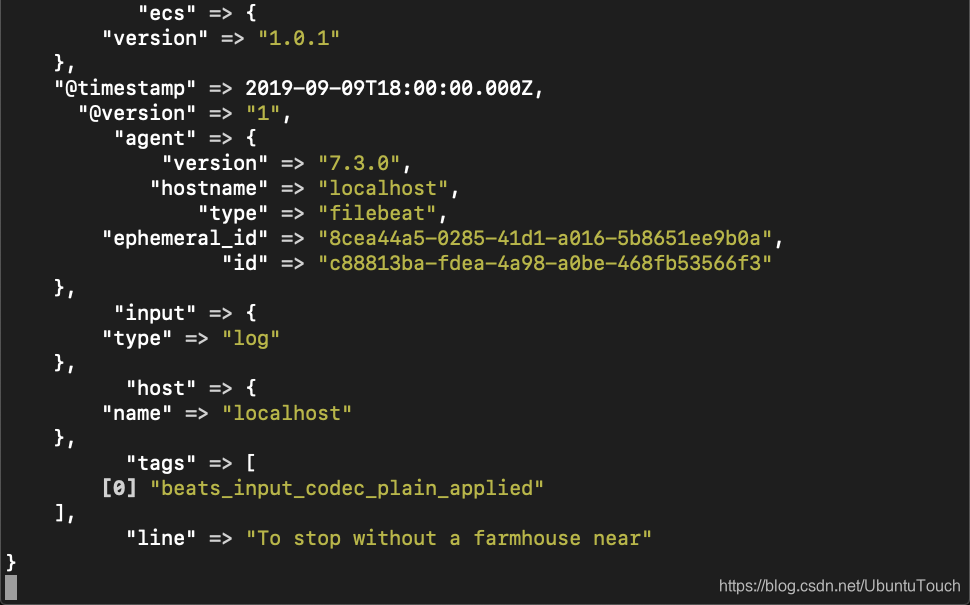
这里除了我们之前看到的那些数据之外,我们也可以看到其他很多不同的字段。这些都是filebeat自动帮我们加入进去的。因为我们加入了 date 过滤器,我们可以看 @timestamp 也取自之前的 timestamp_string 的值。在实际的调试中,我们可以把 filter 一个个地去掉或加上,这样在我们的屏幕上,我们可以看到不同的输出。这个留给大家来做自己的实验。
我们可以回到 Kibana,通过查看一个叫做 “logstash_poem” 的索引:
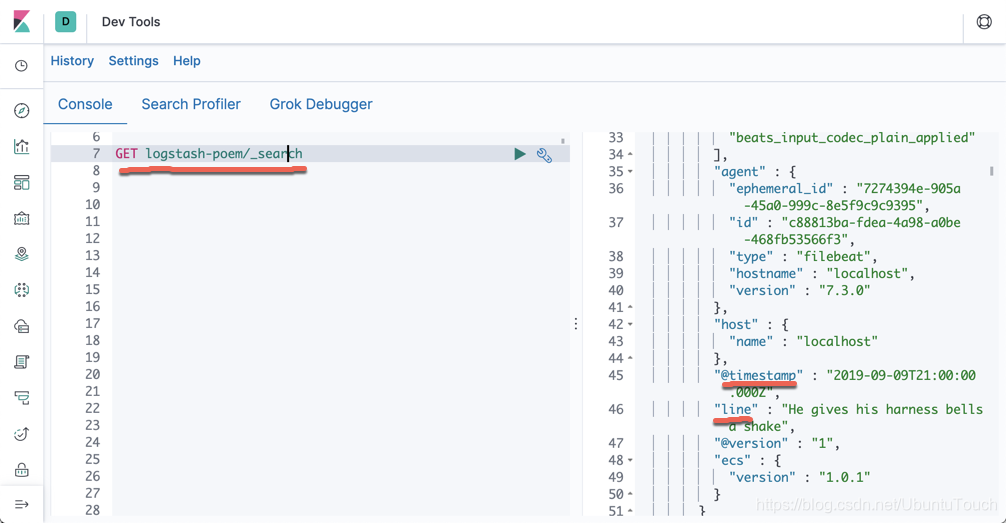
至此,我们已经完成了通过 Filebeat 的方法把一个 log 文件传输到 Elasticsearch 之中。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)