Kafka入门教程及安装
Kafka消息队列Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要用于大数据处理领域发布/订阅模式:消息的发布者不会直接将消息发布给特定的订阅者,而是将消息分不同的类别,订阅者只接受感兴趣的消息Kafka最新定义:Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用Kafka基础概念Top
目录
Kafka消息队列
Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要用于大数据处理领域
发布/订阅模式:消息的发布者不会直接将消息发布给特定的订阅者,而是将消息分不同的类别,订阅者只接受感兴趣的消息
Kafka最新定义:Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用
Kafka基础概念
Topic:指消息的类别(主题),每个消息都必须有;
Producer:指消息的产生者,或者消息的写端;
Consumer:指消息的消费者,或者消息的读端;
Producer Group:指产生者组,组内的生产者产生同一类消息;
Consumer Group:指消费者组,组内的消费者消费同一类消息;
Broker:指消息服务器,Producer产生的消息都是写到这里,Consumer读消息也是在这里读;
Zookeeper:是Kafka的注册中心,Broker和Consumer之间的协调器,包含状态信息、配置信息和一些Topic的信息;
Partition:指消息的水平分区,一个Topic可以有多个分区;
Replica:指消息的副本,为了提高可用性,将消息副本保存在其它Broker上;
特别说明:Broker是指单个消息服务进程,一般情况下,Kafka是集群运行的,Broker只是集群中的一个服务进程,而非代指整个Kafka服务,可以简单的将Broker理解成服务器(Server)。
Kafka大致结构图如下:
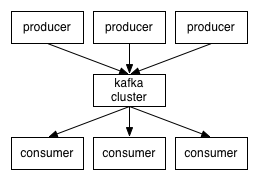
Kafka是Pull模式的消息队列,即Consumer连到消息队列服务上,主动请求新消息,如果要做到实时性,需要采用长轮询。上图中的Consumer的连接箭头方向会产生误会,特此注明
关于顺序和分区
Kafka是一个力求与保持消息顺序性的消息队列,但不是完全保证,其保证的是Partition级别的顺序性,如下图:
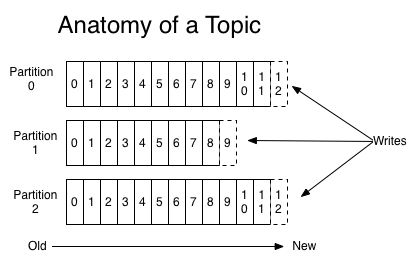
此图是Topic的分区log的示意图,可见,每个分区上的log都是一个有序的队列,所以Kafka是分区级别有序的。如果,某个Topic只有一个分区,那么这个Topic下的消息都是有序的。
分区是为了提升消息处理的吞吐率而产生的,将一个Topic洪的消息分成几份,分别给不同的Broker处理,如下图:
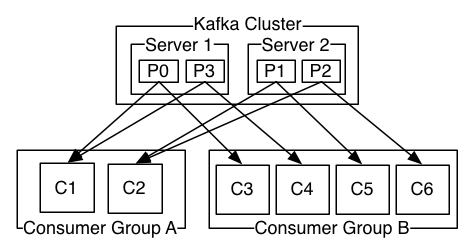
此图中又2个Broker,Server1和Server2,每个Broker上有2个分区,总共4个分区,P0~P3。有2个Consumer Group,Consumer GroupA有2个Consumer,Consumer GroupB有4个Consumer。Kafka的实现是,在稳定的情况下,维持固定的连接,每个Consumer稳定的消费其中某几个分区的消息,以上图举例,Consumer GroupA中的C1稳定消费P0、P3,Consumer GroupB稳定消费P1、P2,这样的连接分配可能会导致消息消费的不均匀分布,但好处是比较容易保证顺序性。
维持完全的顺序性在分布式系统看来几乎是无意义的,因为,如果需要维持顺序性,那么就只能有一条线程阻塞的处理顺序消息,即,Producer->MQ->Consumer必须线程上一一对应。这与分布式系统的初衷是相违背的,但是局部的有序性是可以维持的,比如,有3万条消息,每3条之间有关联,1->2->3,4->5->6,.....,但是全局范围来看,并不需要保证 1->4->7,可以 7->4->1 的顺序来执行,这样可以达到最大并行度10000,而这通常是现实中我们面对的情况。通常应用中,将有先后关系的消息发送到相同的分区上,即可解决大部分问题。
关于副本
副本是高可用Kafka集群的实现方式。假设集群中有3个Broker,那么可以指定3个副本,这3个副本是对等的,对于某个Topic的分区来说,其中一个是Leader,即主节点,另外2个副本是Follower,即从节点,每个副本在一个Broker上。当Leader收到消息的时候,会将消息写一份到副本中,通常情况,只有Leader处于工作状态。在Leader发生故障宕机的时候,Follower会取代Leader继续传送消息,而不会发生消息丢失。Kafka的副本是以分区为单位的,也就是说,即使是同一个Topic,其不同分区的Leader节点也不同,甚至,Kafka倾向于用不同的Broker来做分区的Leader,因为这样能做到更好的负载均衡。
在副本间的消息同步,实际上是复制消息的log,复制可以是同步复制,也可以是异步复制。同步复制是说,当Leader收到消息后,将消息写入从副本,只有在收到从副本写入成功的确认后才返回成功给Producer。异步复制是说,Leader将消息写入从副本,但是不等待从副本的成功确认,直接返回成功给Producer。同步复制效率低,但是消息不会丢失。异步复制效率高,但是在Broker宕机的时候,可能会出现消息丢失。
丢消息和重复收到消息
任何一个MQ都需要处理丢消息和重复收到消息的,正常情况下,Kafka可以保证:1、不丢消息;2、不重复发消息;3、消息读且只读一次。极端情况下,如Broker宕机,断电,这类情况下,Kafka将无法保证不丢失消息和不重复发送消息,但是在有副本的情况下,Kafka是可以保证消息不丢失的,其前提是设置了同步复制,这儿是Kafka的默认设置,但是可能出现重复发送消息,这个交给上层应用解决。在生产者中使用异步提交,可以保证不重复发送消息,但是有丢失消息的可能。
Zookeeper安装教程
官网下载地址:Index of /dist/zookeeper
安装步骤
1、打开官网下载对应版本,复制到服务器文件夹中
2、使用tar -zxvf 命令解压安装包 [root@VM-4-3-centos conf]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
3、使用cd 命令进入解压后的目录,进入conf文件夹,使用mv命令修改zoo-sample.cfg文件名为zoo.cfg,简化文件名称。
4、使用vim 命令进入zoo.cfg 修改Zookeeper数据存储地址,默认地址为Linux临时文件目录,在安装目录下新建zkData文件夹,地址切换为zkData地址,修改后保存并退出。

5、进入bin目录下使用 ./zkServer.sh start 启动服务 ,启动完成后使用 jps 命令查看Java进程是否启动成功,未安装的话使用yum install -y java-1.8.0-openjdk-devel.x86_64 命令进行安装
6、启动完服务端可使用命令 ./zkCli.sh 启动Zookeeper客户端进行访问,使用 quit 命令可退出Zookeeper客户端
7、Zookeeper conf参数详解 :
tickTime = 2000 :通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit = 10 :LF初始通信时限
syncLimit = 5 :LF同步通信时限
dataDir:保存Zookeeper中的数据
clientPort = 2181:客户端连接端口,通常不做修改
zookeeper集群配置
1、在Zookeeper数据存储地址文件夹中使用 vim myid 新建一个myid文件(切记必须为myid文件名),然后在里面输入一个数字(切记该数字在集群中必须唯一不可重复)然后保存并退出。

2、如有集群服务器便将该安装文件夹分发到其它服务器下,然后修改该文件myid(数值不可重复,切记)
3、在配置文件中末尾增加如下配置(根据自身情况)
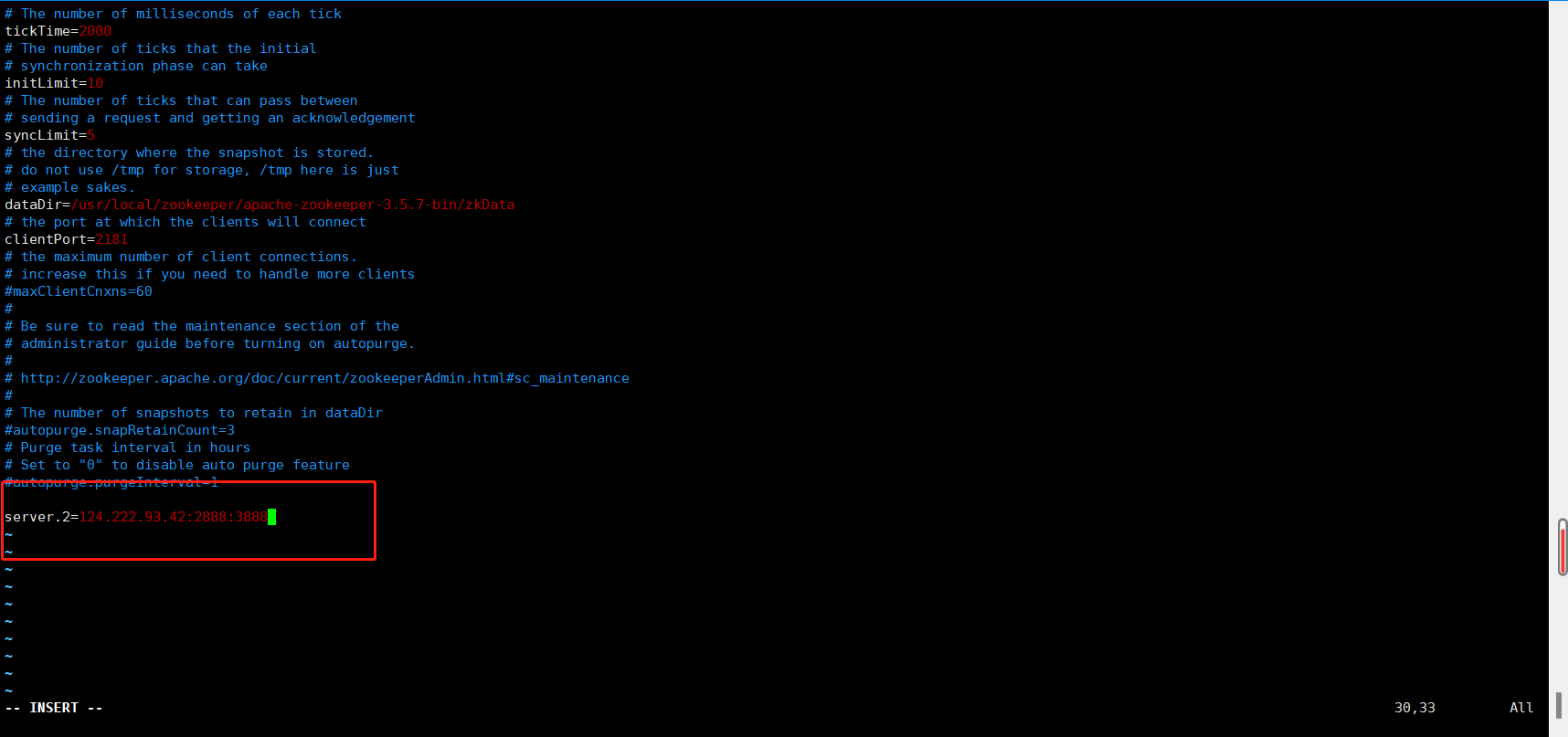
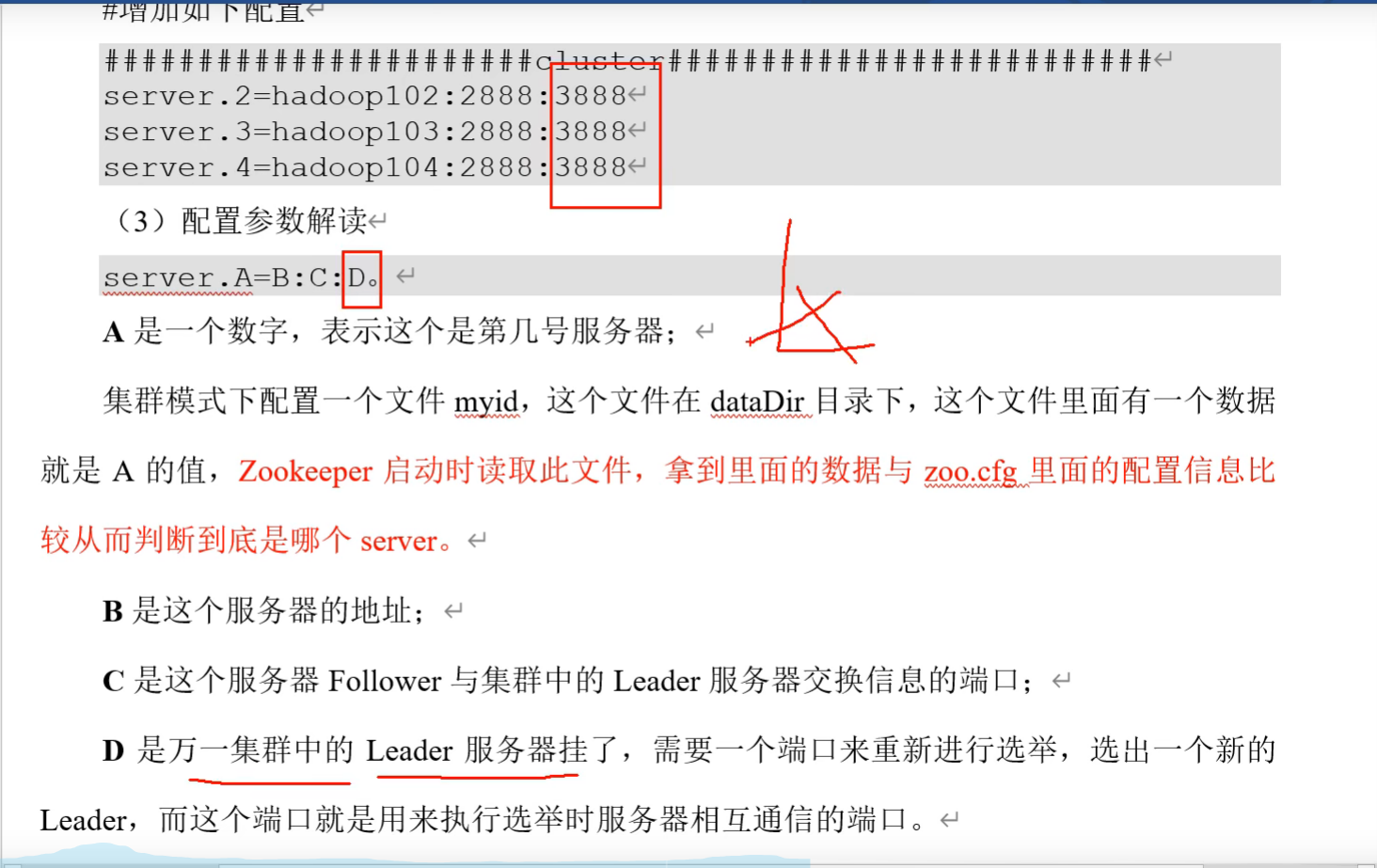
4、配置说明
5、配置完成后启动bin目录下的zkServer.sh 服务,切记,集群服务必须启动半数以上服务才能启动成功,可使用zkServier.sh status 查看当前Zookeeper状态
Kafka安装教程
官网下载地址:Apache Kafka
Kafka3.0.0版本不再支持Java8,Kafka2.8.0可替换不使用ZooKeeper:
安装步骤
1、打开官网下载所需要的版本,复制到服务器文件夹中
2、使用 tar -zxvf 解压下载的安装包 [root@VM-4-3-centos kafka]# tar -zxvf kafka_2.13-2.8.1.tgz
3、使用cd 命令进入Kafka config配置文件夹
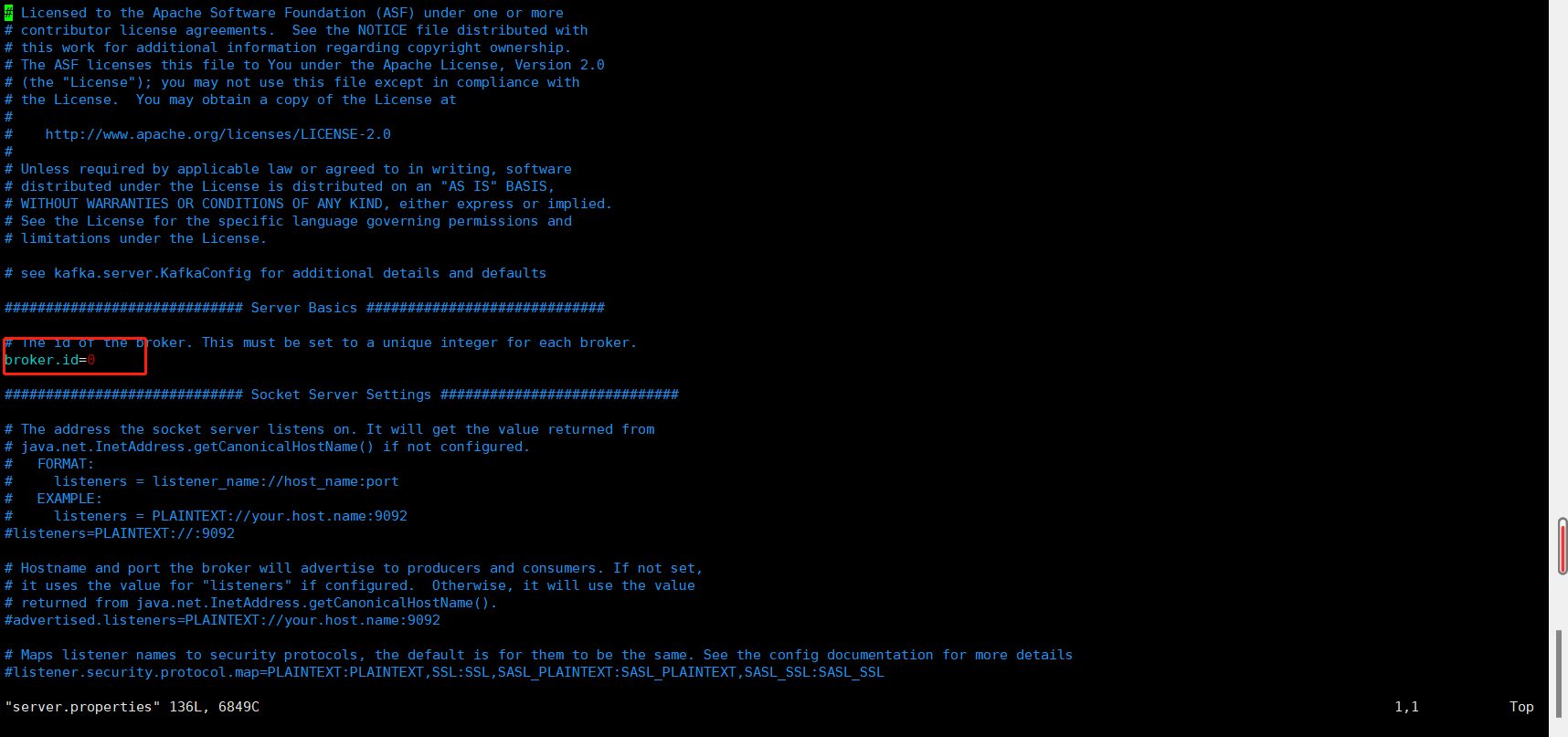
4、使用vim 命令进入server.properties文件,修改配置参数broker.id=0 ,该数值在集群服务中为唯一,不允许重复
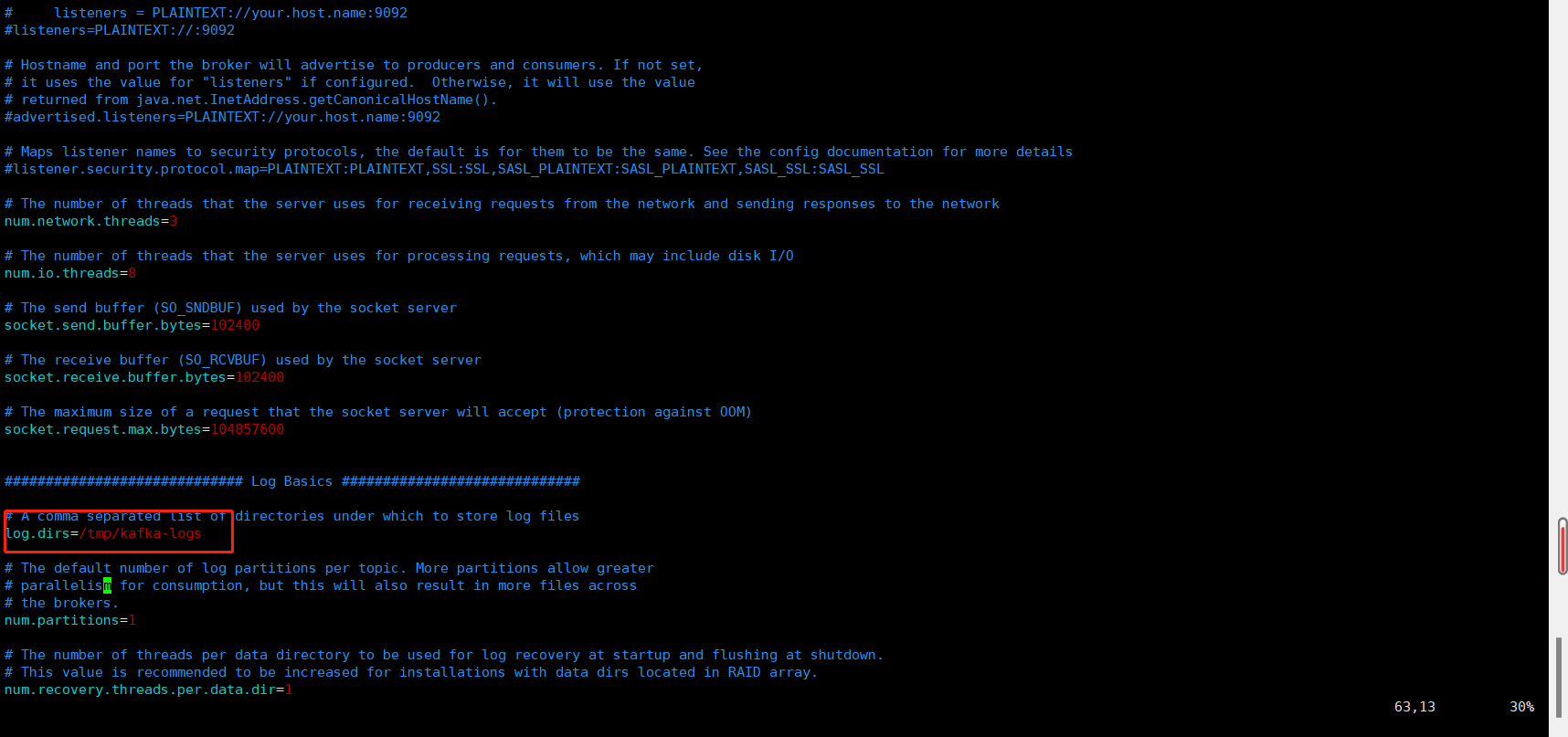
5、往下翻,找到配置参数log.dirs=/tmp/kafka-logs,改参数地址为存储Kafka数据地址,默认地址为Linux临时目录,会不定时回收,请修改地址
6、往下翻,找到配置参数zookeeper.connect=localhost:2181,该配置参数为zookeepe集群的地址,可以是多个,多个之间用逗号分割,一般端口都为2181;hostname1:port1,hostname2:port2,hostname3:port3。完成后使用:wq命令保存退出
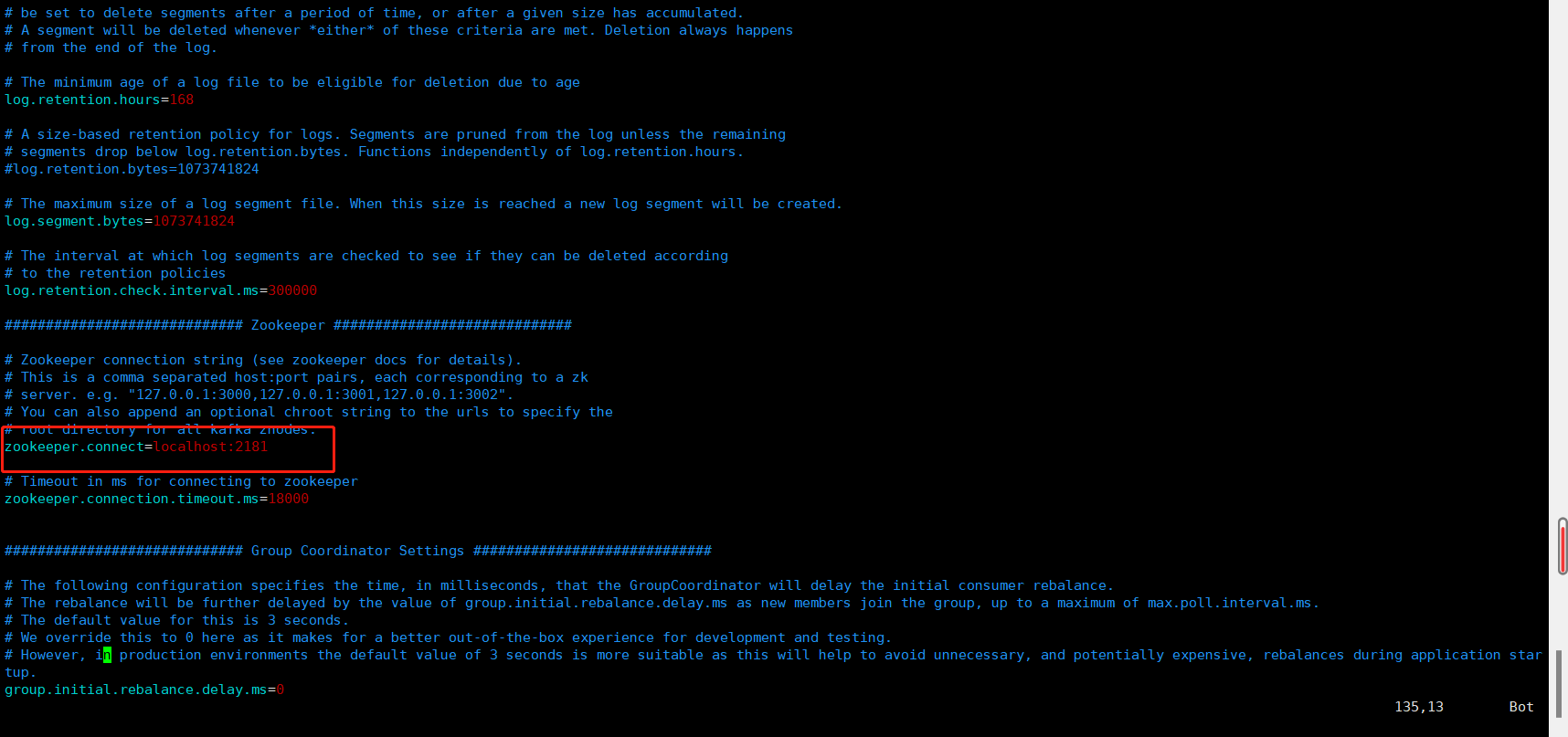
7、配置Kafka环境变量,使用cd命令进入根目录,使用vim ./etc/profile 文件配置Kafkal路径并保存退出
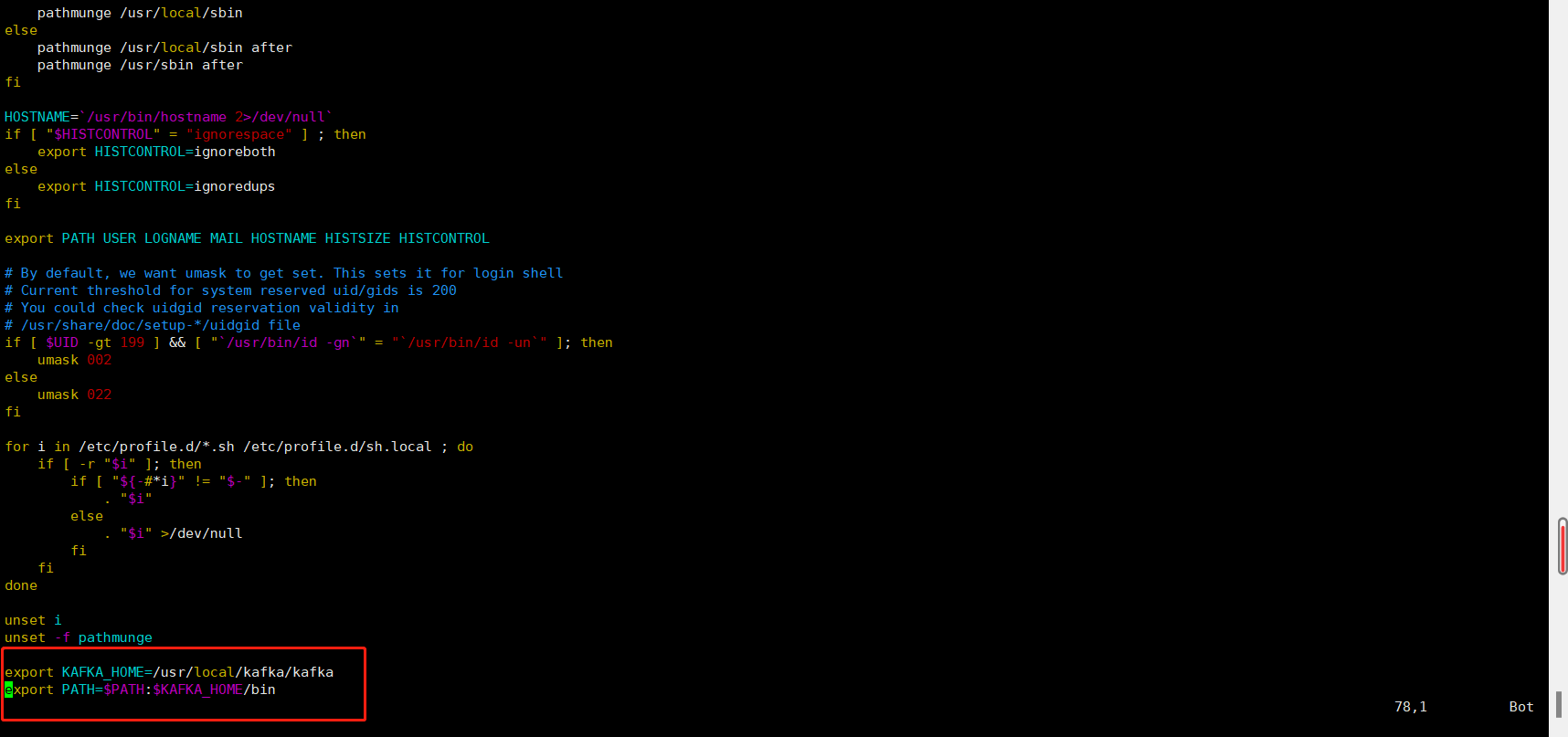
export KAFKA_HOME=/usr/local/kafka/kafka
export PATH=$PATH:$KAFKA_HOME/bin
8、使用./kafka-server-start.sh -daemon ../config/server.properties 启动Kafka服务,切记,启动Kafka服务前必须启动Zookeeper服务。然后使用jps命令查看状态是否启动
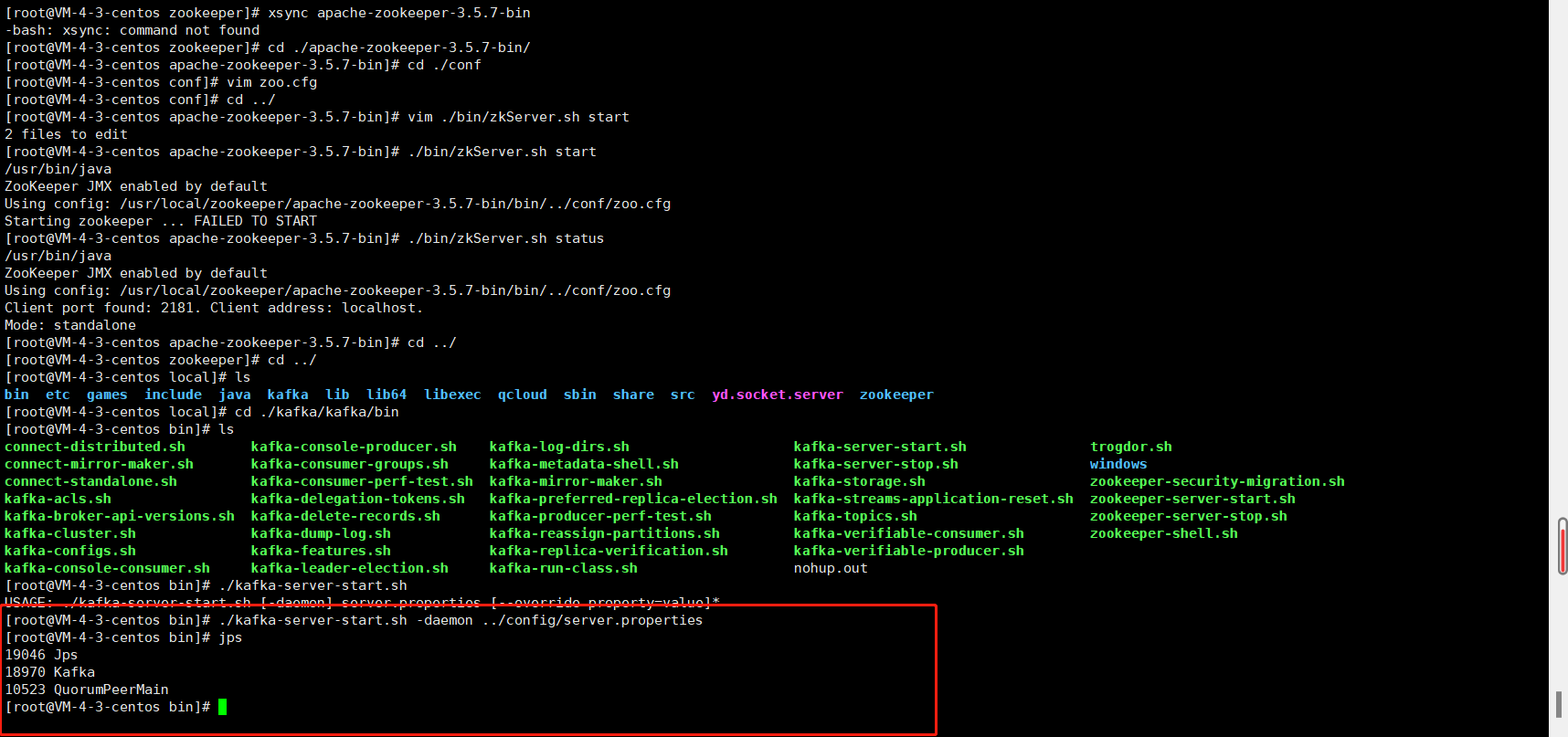
切记,Zookeeper关闭前必须先关闭Kafka,否则将无法再关闭Kafka(当然可以强制杀死)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)