Phoenix 简介及使用方式
一、Phoenix 简介Phoenix 最早是 saleforce 的一个开源项目,后来成为 Apache 的顶级项目。Phoenix 构建在 HBase 之上的开源 SQL 层。能够让我们使用标准的 JDBC API 去建表, 插入数据和查询 HBase 中的数据, 从而可以避免使用 HBase 的客户端 API。在我们的应用和 HBase 之间添加了 Phoenix, 并不会降低性能, 而且我
Phoenix 简介及使用方式
目录
一、Phoenix 简介
Phoenix 最早是 saleforce 的一个开源项目,后来成为 Apache 的顶级项目。
Phoenix 构建在 HBase 之上的开源 SQL 层。能够让我们使用标准的 JDBC API 去建表, 插入数据和查询 HBase 中的数据, 从而可以避免使用 HBase 的客户端 API。在我们的应用和 HBase 之间添加了 Phoenix, 并不会降低性能, 而且我们也少写了很多代码。
phoneix的本质就是定义了大量的协处理器,使用协处理器帮助我们完成HBase的操作!
二、Phoenix 特点
- 将 SQL 查询编译为 HBase 扫描
- 确定扫描 Rowkey 的最佳开始和结束位置
- 扫描并行执行
- 将 where 子句推送到服务器端的过滤器
- 通过协处理器进行聚合操作
- 完美支持 HBase 二级索引创建
- DML命令以及通过DDL命令创建和操作表和版本化增量更改。
- 容易集成:如Spark,Hive,Pig,Flume和Map Reduce。
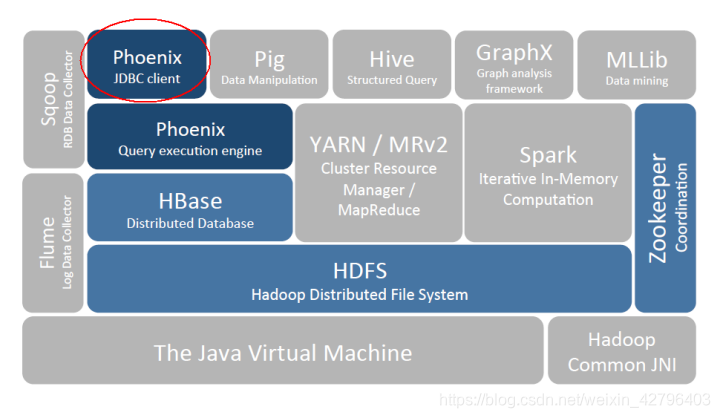
三、Phoenix 架构
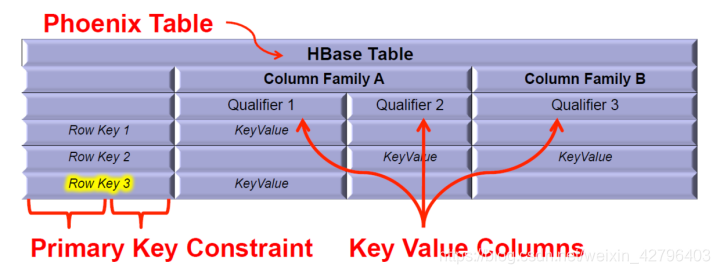
四、和Hbase中数据的关系映射
| 模型 | HBase | Phoneix(SQL) |
|---|---|---|
| 库 | namespace | database |
| 表 | table | table |
| 列族 | column Family cf:cq | 列 |
| 列名 | column Quailfier | |
| 值 | value | |
| 行键 | rowkey(唯一) dt|area|city|adsid | 主键(dt,area,city,adsid) |
Phoenix 将 HBase 的数据模型映射到关系型模型中!
五、Phoenix使用场景
5.1 场景一:新建表
通过phoneix在hbase中创建表,通过phoneix向hbase的表执行增删改查!
--使用默认的0号列族
CREATE TABLE IF NOT EXISTS "us_population" (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
--如果希望列族有意义
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
info.population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
默认所有的小写,都会转大写!在查询时的小写也会转大写!
如果必须用小写,需要加"", 在以后操作时,都需要加"",尽量不要使用小写!
5.2 场景二:映射Hbase中已有表
hbase中已经存在了一个表,在phoneix中建表,映射上,进行操作!
在phoneix中,只读操作! 创建一个View!
CREATE VIEW IF NOT EXISTS "t2" (
id VARCHAR PRIMARY KEY ,
"cf1"."name" VARCHAR ,
"cf2"."age" VARCHAR ,
"cf2"."gender" VARCHAR
);
在phoneix中,可读可写操作! 创建一个Table!
CREATE TABLE IF NOT EXISTS "t4" (
id VARCHAR PRIMARY KEY ,
"cf1"."name" VARCHAR ,
"cf2"."age" VARCHAR ,
"cf2"."gender" VARCHAR
) column_encoded_bytes=0;
五、Phoenix使用语法
进入Phoenix客户端界面
[hadoop@hadoop101 phoenix]$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
1)显示所有表
!table 或 !tables
2)创建表
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
说明:
- char类型必须添加长度限制
- varchar 可以不用长度限制
- 主键映射到 HBase 中会成为 Rowkey. 如果有多个主键(联合主键), 会把多个主键的值拼成 rowkey
- 在 Phoenix 中, 默认会把表名,字段名等自动转换成大写. 如果要使用消息, 需要把他们用双引号括起来.
3)插入数据
upsert into us_population values('NY','NewYork',8143197);
upsert into us_population values('CA','Los Angeles',3844829);
upsert into us_population values('IL','Chicago',2842518);
说明: upset可以看成是update和insert的结合体.
4)查询记录
select * from US_POPULATION;
select * from us_population where state='NY';
5)删除记录
delete from us_population where state='NY';
6)删除表
drop table us_population;
7)退出命令行
! quit
六、使用JDBC连接
添加如下依赖:
<!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-core -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
测试连接:
import java.sql.*;
public class MyPhoenix {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
//Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
Connection connection = DriverManager.getConnection("jdbc:phoenix:hadoop102:2181");
String sql = "select * from US_POPULATION";
PreparedStatement ps = connection.prepareStatement(sql);
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()){
System.out.println(resultSet.getString("STATE")+" "
+ resultSet.getString("CITY") + " "
+ resultSet.getLong("POPULATION"));
}
resultSet.close();
ps.close();
connection.close();
}
}

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)