Hbase简介
Hbase基本原理,数据节点、名称节点
1.Hbase简介
Hbase是一个开源的NoSQL数据库,参考Google的Big Table建模,用Java语言实现,运行于HDFS文件系统上,为Hadoop提供类似BigTable的服务。
特性:
- 容量巨大:在限定某个列的情况下对于单表存储百亿或更多的数据都没有性能问题,并且自身能够周期性地将较小文件合并成大文件以减少对磁盘的访问。
- 列存储
- 稀疏性:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
- 扩展性:横向扩展:不断向集群添加服务器来提供存储空间和性能
- 高可靠性:基于HDFS的多副本机制
2.HDFS原理
设计目标是把超大数据集存储到集群中的多台普通商用计算机上,并对外提供高可靠性和高吞吐量的服务。
1.基本架构
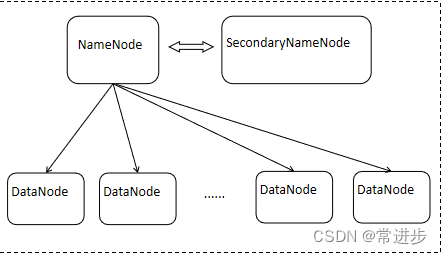
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)。
块是文件存储处理的逻辑单元
HDFS的文件被分成块进行存储
HDFS块的默认大小是64MB
分块的好处:
支持大规模的文件存储,文件大小不受单点存储容量限制。
简化了系统设计,每个节点存储多少个文件块很容易计算。
适合数据备份,每个分块冗余的备份存储到多个节点。
利于负载均衡。
块大小可自行设置,不能太大,也不宜过小
(1)NameNode(名称结点)
负责存储文件的元数据 目录,文件,权限等信息 文件分块,副本存储等信息
与客户端交互提供元数据的访问 不进行涉及文件数据读写
与datanode交互,分配全局的数据存储节点
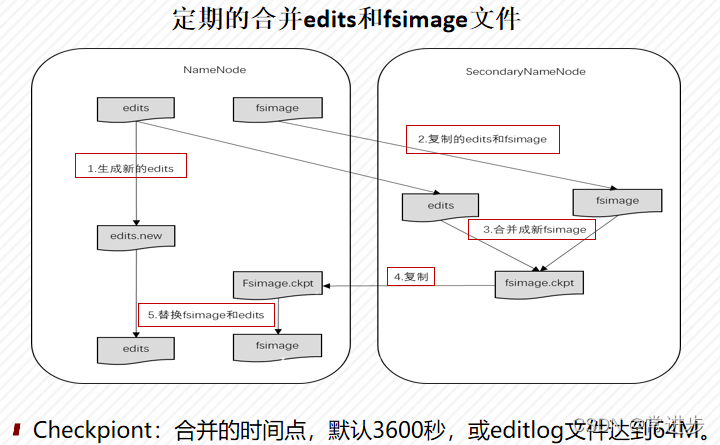
两个核心的数据结构:FsImage和EditLog
FsImage(映象文件):用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
EditLog(事务日志):记录了所有针对文件的创建、删除、重命名等操作
NameNode启动时,加载FsImage到内存,只读状态,修改元数据操作记录在EditLog当中, EditLog文件定期合并,形成新的fsimage来替代旧的fsimage文件。
(2)SecondaryNameNode
(3)DataNode(数据节点)
分布式文件系统中的每一个文件,都被切分成若干个数据块,每一个数据块都被存储在不同的服务器上,此服务器称之为数据服务器,这就是DataNode(数据节点)
- 负责存储数据块
- 负责为客户端提供数据块的读写服务
- 响应NameNode的相关指令
- 发送心跳信息
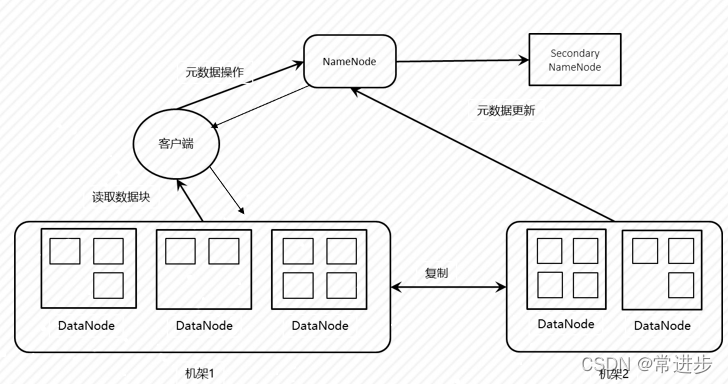
工作原理:在HDFS中,文件是被分成块来进行存储的,一个文件可以包含许多个块,每个块存储在不同的DataNode中。 当一个客户端请求读取一个文件时,它需要先从NameNode中获取文件的元数据信息,然后从对应的数据节点上并行的读取数据块。Datanode上数据块删除更新操作会通知Namenode来更新元数据,从而使得整个系统能够正确的运行。
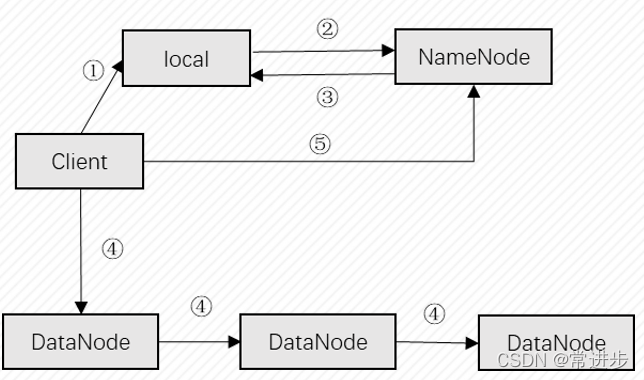
3.HDFS读写机制
3.1 读文件机制
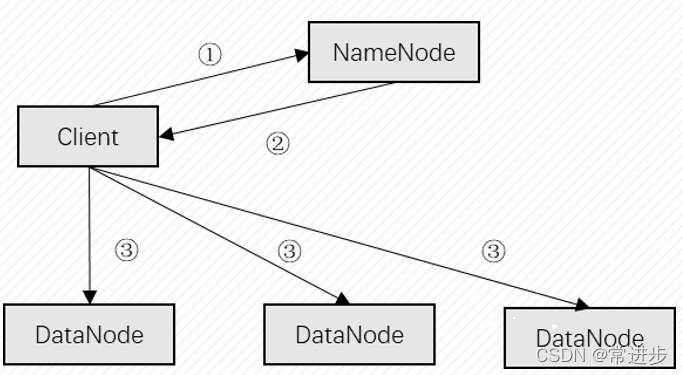
①发送读取文件请求; ②返回元数据,包括文件与数据块的映射数据块与datanode的映射;
③与datanode通信,获取数据块。
3.2 写文件机制
①写临时文件到本地; ②向NamenNode发送写文件请求;
③检查元数据信息,创建文件,返回数据块的DataNode地址列表;
④客户端直接向DataNode写入数据; ⑤发送确认信息。
3.3 副本机制
特性:
默认副本数为3
跨越多个机架
默认副本策略
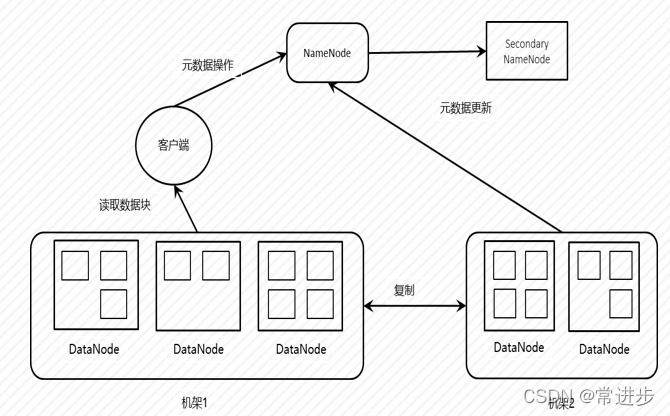
存于不同机架: 防止机架故障导致数据块不可用, 多个客户端访问可以实现负载均衡,影响写效率
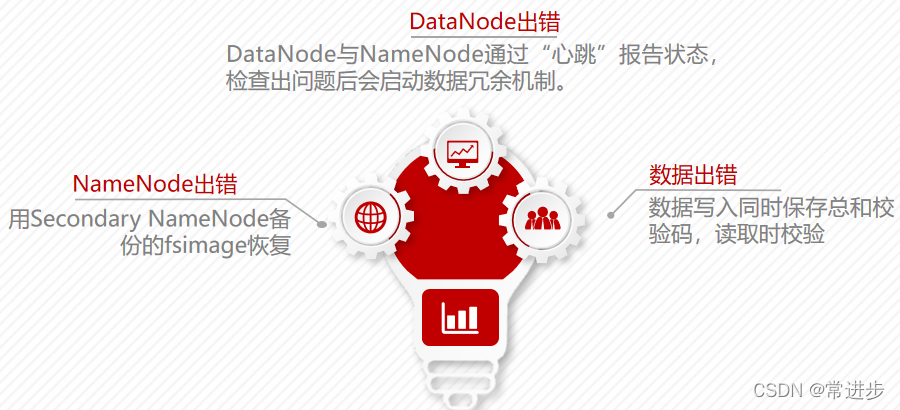
3.4容错
HDFS具有较高的容错性,可以兼容廉价的硬件,它把硬件出错看作一种常态,而不是异常,并设计了相应的机制检测数据错误和进行自动恢复。
主要包括以下几种情形: 名称节点出错、数据节点出错、数据出错
1、当NameNode出错时,可以根据SecondaryNameNode中的FsImage和Editlog数据进行恢复。
2、第二中情况是datanode出错时,当datanode发生故障,或者网络发生断网时,namenode就无法收到来自一些故障节点的心跳信息,这时,这些故障的datanode就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,且namenode也不会再给它们发送任何I/O请求。这时,有可能出现一种情形,即由于一些datanode的不可用,会导致一些数据块的副本数量小于原先定义的数量,namenode会定期检查,一旦发现这种情况,就会启动数据冗余机制,为它生成新的副本。
3. 第三种情况,数据出现错误,数据在网络中传输和磁盘操作时,都会造成数据错误,HDFS中,在文件被创建时,客户端就会对每一个文件块进行信息摘录,并保存总和校验码,当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个datanode读取该文件块,并且向namenode报告这个文件块有错误,名称节点会定期检查并且重新复制这个块。 HDFS通过各种机制,包括分块机制,副本机制和容错机制,保证了文件系统的可靠性。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)