Redis分片
这就好比不要把鸡蛋放在同一个篮子里,这样一旦一个篮子掉在地上,摔碎了,别的篮子里还有没摔碎的鸡蛋,不至于一个不剩。算笔账,假设系统QPS 1w,每次调用会访问10次缓存或DB的数据,则当缓存命中率仅减少1%,DB每s就增加1w * 10 * 1% = 1000次请求。不利于扩展,当需要扩展的时候,前三个数据库的数据都可能需要迁移到第四个redis数据库中,发生大规模的数据迁移。这样,当某节点故障,
目录
一:Redis为什么要分片
一般你系统核心缓存的命中率需维持在99%甚至99.9%,哪怕下降1%,系统都会遭受毁灭性打击。
算笔账,假设系统QPS 1w,每次调用会访问10次缓存或DB的数据,则当缓存命中率仅减少1%,DB每s就增加1w * 10 * 1% = 1000次请求。
一般单个MySQL节点读请求峰值QPS就1500左右,增加的这1000次请求很可能会给DB带来毁灭打击。
更不用说缓存节点故障会有多大影响了。图中单点部署的缓存节点就成了整体系统中最大隐患!
那如何解决这个问题,提升缓存可用性?
可部署多个节点,同时让这些节点互为备份。这样,当某节点故障,其备份节点可顶替它继续服务。
这就是分布式缓存的高可用方案。
就需要把数据和请求分散到多台机器,这就需要引入分布式存储。
单点缓存节点受机器内存、网卡带宽和单节点请求量限制,随着请求量和数据量的增加,不能承担更高并发,考虑将数据分片,依照分片算法将数据打散到多个不同节点,每个节点存储部分数据。
这样在某个节点故障的情况下,其他节点也可以提供服务,保证了一定的可用性。这就好比不要把鸡蛋放在同一个篮子里,这样一旦一个篮子掉在地上,摔碎了,别的篮子里还有没摔碎的鸡蛋,不至于一个不剩。
二:分布式存储的特性
- 增强可用性
如果数据库的某个节点出现故障,在其他节点的数据仍然可用 - 维护方便
如果数据库的某个节点出现故障,需要修复数据,只需修复该节点 - 均衡I/O
可以把不同的请求映射到各节点以平衡 I/O,改善整个系统性能 - 改善查询性能
对分区对象的查询可以仅搜索自己关心的节点,提高检索速度
分布式存储首先要解决把整个数据集按分区规则映射到多个节点的问题,即把数据集划分到多个节点,每个节点负责整体数据的一个子集:
分片可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。
分片使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
三:分片方案
假设:
- 有 4 个 Redis 实例 R0,R1,R2,R3
- 很多表示用户的键,像 user:1,user:2
有如下方案可映射键到指定 Redis 节点。
(1)范围分片
也叫顺序分区,最简单的分区方式。通过映射对象的范围到指定的 Redis 实例来完成分片。

优点
- 键值业务相关
- 可顺序访问
同一范围内的范围查询不需要跨节点,提升查询速度 - 支持批量操作
缺点
- 数据分散度易倾斜
- 需要一个映射范围到实例的表格。该表需要管理,不同类型的对象都需要一个表,所以范围分片在 Redis 中常常并不可取,因这要比其他分片可选方案低效得多。
(2)hash节点取余分区
例如你有三个数据库,那就余3,然后根据余数分配到不同的数据库

不利于扩展,当需要扩展的时候,前三个数据库的数据都可能需要迁移到第四个redis数据库中,发生大规模的数据迁移
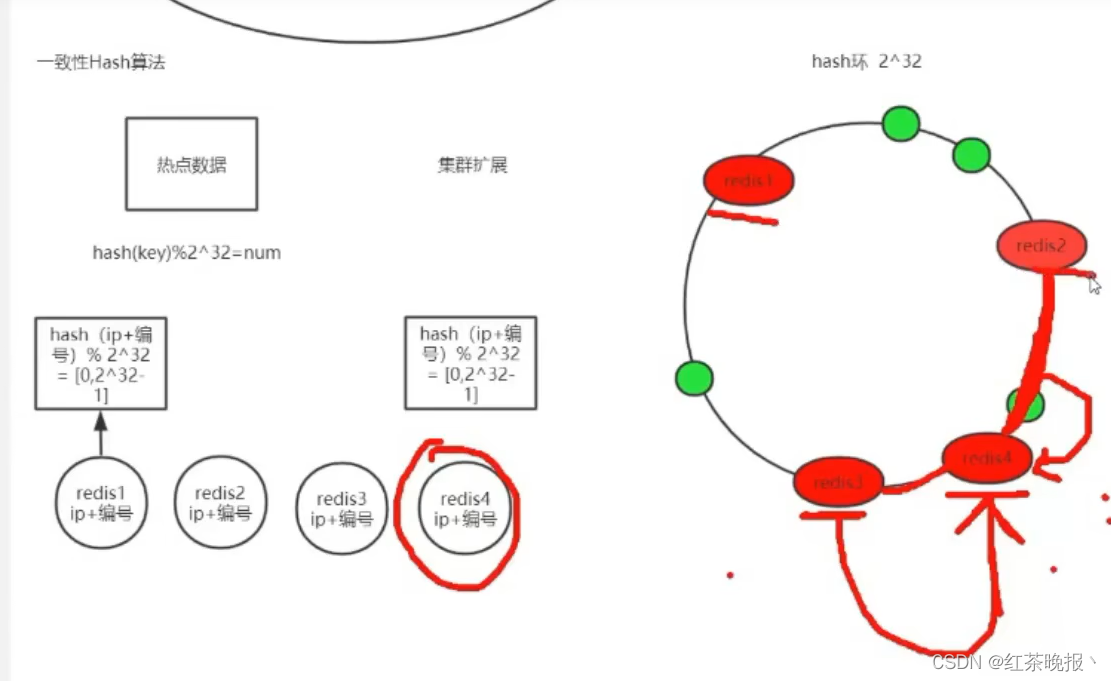
(3)一致性hash分区
原理
1.环形 hash 空间
2.按常用 hash 算法,将对应的 key hash到一个具有 2^32 个桶的空间,即(0 ~ 2^32 - 1)的数字空间中。
将这些数字头尾相连,想象成一个闭合环形:
- 把数据通过一定的 hash 算法映射到环上
- 将机器通过一定的 hash 算法映射到环上
- 节点按顺时针转动,遇到的第一个机器,就把数据放在该机器
- 把对象映射到hash空间
当新增数据库redis4的时候,不需要动redis1和redis2的数据,只需要改变redis3
但是还是会出现数据倾斜问题
可通过虚拟节点来解决这个问题

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)