Flink、Kafka梳理
flink和kafka梳理
·
flink是什么
flink是一个框架和分布式处理引擎,对于有界流和无界流进行有状态计算
flink的几种模式
独立集群模式:flink可以不依赖于hadoop集群 flink on yarn:依赖于hadoop集群 yarn-session -jm 1024 -tm 1096 (jm jobmanagermemory tm taskmanagermemory) flink run -c 先在yarn上启动一个jobmanager 所有job共享一个jobmanager flink run -m yarn-cluster per job-cluster 直接提交任务到yarn集群上,每一个job独享一个jobmanager
flink的几种提交模式
web页面提交
flink run -c
rpc远程提交(
创建flink环境
StreamExecutionEnvironment.createRemoteEnvironment("ip",PORT,"jarFile")
)
kafka
-
kafka架构
producer:消息生产者 consumer:消息消费者 broker:kafka集群的server,负责处理消息读,写请求,存储消息 topic:消息队列、分类 一个topic中的数据结构要一样 queue里面有生产者消费模型
-
kafka的消息存储和生产消费模型
一个topic分成多个partition 每个partition内部有序,都有一个offset 消息不经过内存缓冲,直接写入文件(零拷贝) 根据实践策略删除,不是消费完就删除 producer写入partition可以是轮询也可以是hash
consumer自己维护消费到哪个offset 一个消息在一个组内只被消费一次
-
kafka有哪些特点
消息系统的特点:生产者消费者模型,FIFO(先进先出,一个分区的时候才能保证顺序) 高性能:单节点支持上千个客户端,百MB/s吞吐 持久性:消息直接持久化在普通磁盘上且性能好 分布式:数据副本冗余 、流量负载均衡、可扩展 很灵活:消息长时间持久化+Client维护消费状态
-
为什么kafka快
1.顺序读写 2.零拷贝技术(spark reduce端到map端拉文件也是零拷贝技术) 3.批量读写
-
kafka搭建
修改config/server/properties 1.broker.id=0每一个节点的broker.id不一样 2.zookeeper.connect = master:2181 3.log.dirs 消息存放的位置 分布式的要分发到不同的节点 kafka-server-start.sh -daemon(后台启动) 配置文件的路径
kafka生产消费
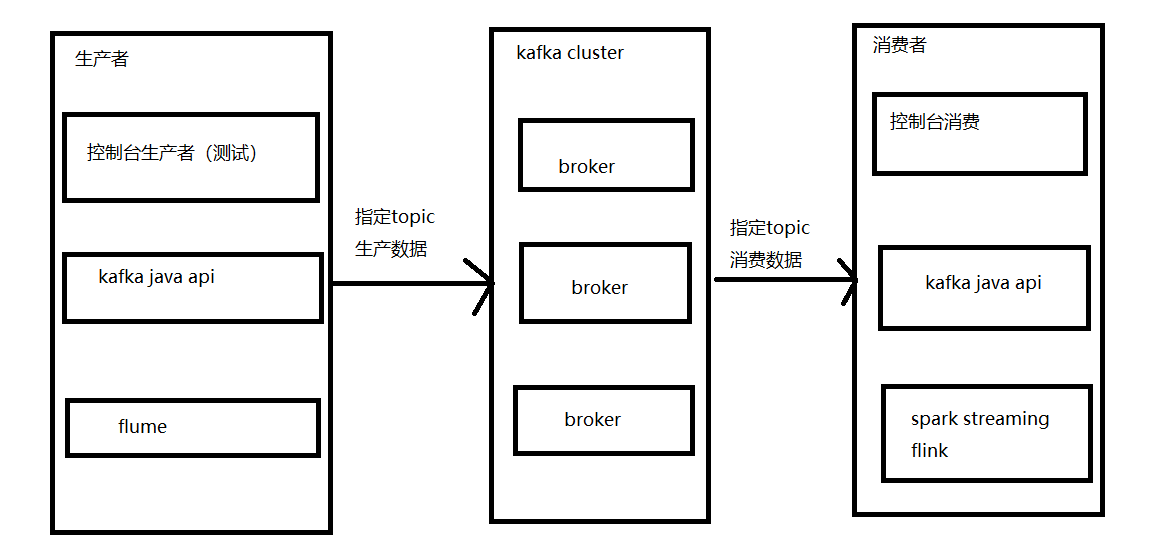
-
exactly-once
如何保证kafka结合flink的只消费一次 要实现唯一一次从三个方面来说
生产端
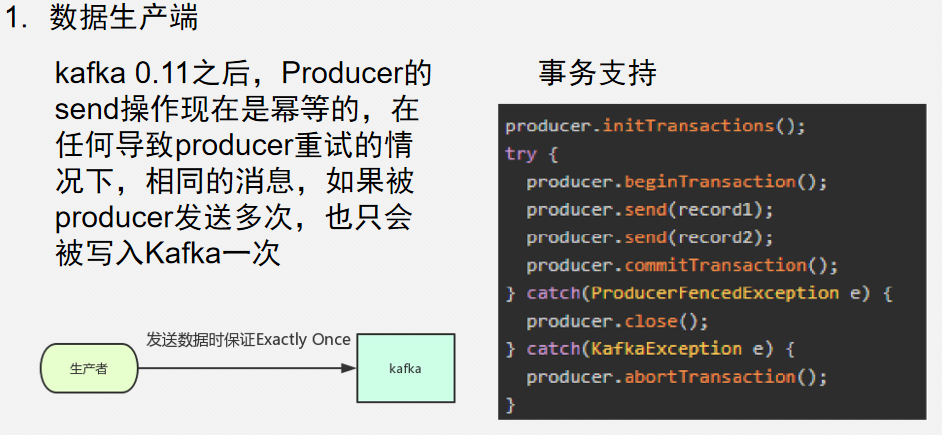
幂等性(保证数据只发送一次) 事务性(提交数据要成功都成功,要失败都失败) ack(保证数据不丢失)
消费端

当消费数据的算子做聚合计算的时候,虽然数据会发送两次,但是算子计算会返回到上个checkpoint时计算,只计算一次。
sink端
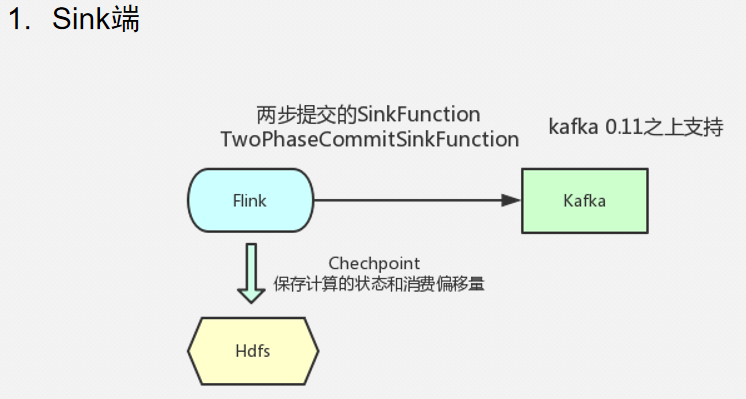
开启两次提交,将参数改为EXACTLY_ONCE 模式匹配到EXACTLY_ONCE 会开启事务,数据就不会重复发送 Semantic.EXACTLY_ONCE
flink四大基石
-
Checkpoint
1、jobmanager定时做checkpoint向sourcetask发送触发器 2、sourcetask给数据打上标记,同事将checkpoint存到hdfs中 3、下游算子对标记进行异步处理 4、当所有算子处理完同一个标记,就完成了一次checkpoint
-
State
ValueState、MapState、ListState、ReducingState 状态会保存计算的结果持久化到hdfs 结合Checkpoint
-
Time
事件时间 Event time:数据自带的时间,是数据真实发生的时间。 接收时间 Ingestion time:数据到达DataSource的时间 处理时间 Processing time:数据被处理的时间,处理这条数据的时间 水位线: 默认最新一条数据的事件时间 水位线的主要作用是为了防止乱序
-
Window
时间窗口 Time Window 事件时间窗口(事件滚动窗口,事件滑动窗口) 处理时间窗口(处理滚动窗口,处理滑动窗口) 会话窗口 Session Window(当多久没有数据,对前面的数据进行计算) 事件时间会话窗口 处理时间会话窗口 统计窗口 Count Window 滑动统计窗口 滚动统计窗口 窗口触发的条件 水位线大于窗口的结束时间,窗口内有数据
-

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)