Redis主从模式和哨兵模式
redis主从哨兵底层原理详解
Redis主从模式和哨兵模式
1.单机的缺陷
机械故障,短时间无法修复,
容量瓶颈,16g内存,但是我需要64g内存
Qps瓶颈10万qps但是要求100万qps
2.主从复制的作用
数据副本
扩展读性能
3实现主从复制的两种方式
Slaveof命令
Slaveof 主机号 端口号
取消复制 slaveof no one 不会清除数据
配置
Slaveof ip port
Slave-read-only yes
主从三个阶段:全量,长连接传输,部分
4全量复制
查看redis的runid
Redis-cli -p 63779 info server | grep run_id
查看偏移量offset
Redis-cli -p 6379 info rplication 其中的master_repl_offset
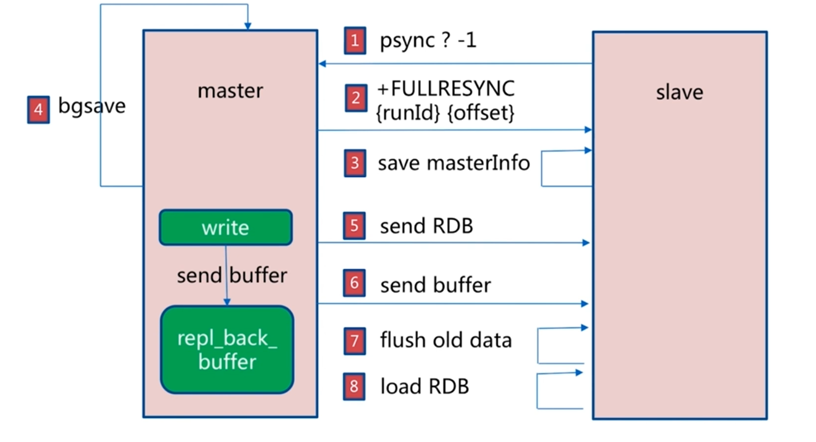
1.slave发送psync请求传输参数有runid和offset到master
2.master接受psync请求后发出+FULLRESYNC runid offset指令传输自己的runid和offset给slave节点
3.slave执行save masterinfo保存主节点的信息。
4.master执行bgsave生成rdb文件,主节点维持repl_back_buffer缓存区,将RDB文件生成后的命令维持在这个区域,用于从节点在RDB文件复制后的同步。
5.master发送rdb给slave,用于主从复制。
-
master发送buffer缓冲区的命令给slave。
7.slave删除旧数据
8.加载rdb文件进行数据同步
5.部分复制
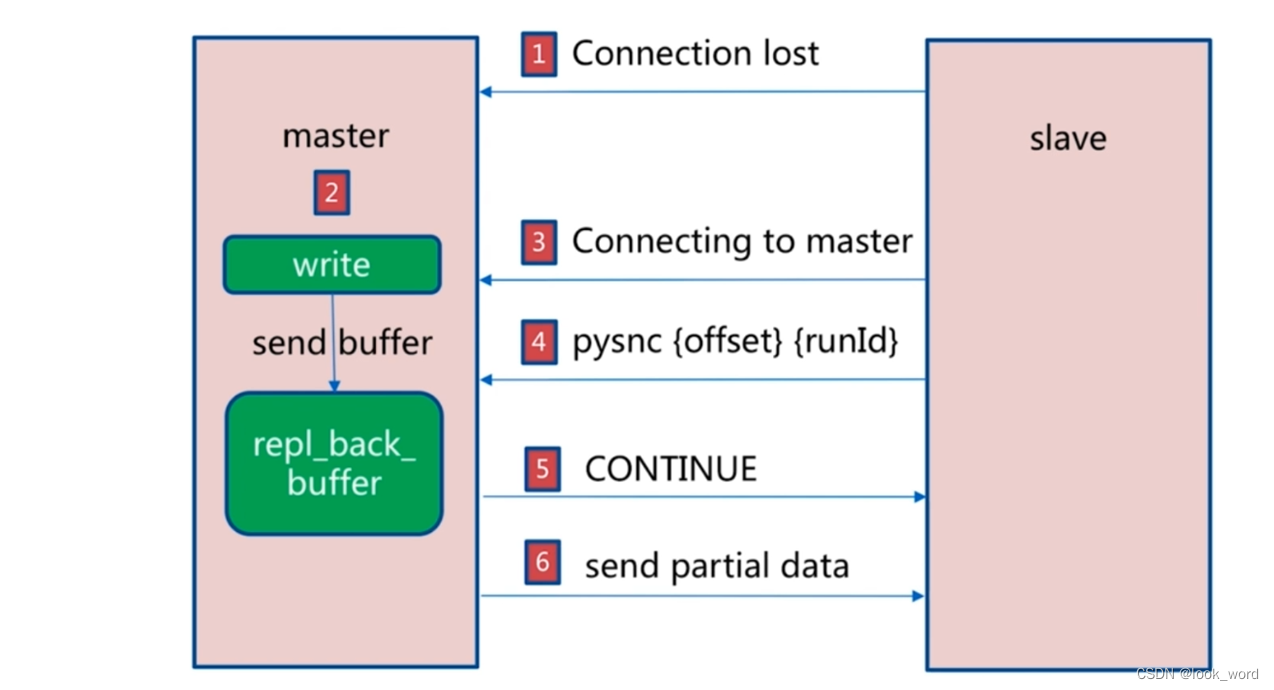
1.当主从节点之间网络出现中断时, 如果超过repl-timeout时间, 主节点会认为从节点故障并中断复制连接
2.当主从节点网络恢复后, 从节点会再次连上主节点
-
当主从连接恢复后, 由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。 因此会把它们当作psync参数发送给主节点, 要求进行部分复制操作
4.主节点接到psync命令后首先核对参数runId是否与自身一致, 如果致, 说明之前复制的是当前主节点; 之后根据参数offset在自身复制积压冲区查找, 如果偏移量之后的数据存在缓冲区中, 则对从节点发送+CONTINUE响应, 表示可以进行部分复制。
5.主节点根据偏移量把复制积压缓冲区里的数据发送给从节点, 保证主从复制进入正常状态。 发送的数据量可以在主节点的日志获取
6.避免全量复制
Bgsave时间,rdb文件网络传输,从节点清空时间,从节点加载rdb的时间
1.第一次的全量复制
无法避免
低峰,夜间
2.节点运行id不匹配
主节点重启(运行id不匹配)
故障转移,例如哨兵或集群
3.复制积压区不足
网络中断,部分复制无法满足
增大复制缓冲区配置rel_backlog_size,网络“增加”
Master节点重启引起全量复制
1.在建立完主从复制后主节点会创建master-replid变量,这个生成的策略跟runid一样,长度是41位,runid长度是40位,然后发送给从节点。
2.在主节点执行shutdown save命令时,进行了一次RDB持久化会把runid 和 offset保存到RDB文件中。可以使用命令redis-check-rdb查看该信息。
3.主节点重启后加载RDB文件,将文件中的repl-id 和repl-offset加载到内存中。纵使让所有从节点认为还是之前的主节点。
主从复制的适用场景
redis主从复制主从复制下的四种常见场景:
一主二从或者一主多从:一个主机下配置多个从机,主机不需要做任何配置,在需要当成从机的机器上运行redis执行SLAVEOF+主机IP地址+主机redis端口号 即可
薪火相传:如现在启动了A/B/C三个rides,A是B的主机,B是C的主机,这就是薪火相传。不在是B和C都挂在A上。
反客为主:当主机挂了,可以在从机中选出一台机器从新指定为主机,只要在选中的从机执行SLAVEOF no one 指令,并将从机从新与新的主机绑定即可
哨兵模式:反客为主的自动版,当主机挂了redis会自动帮你从从机中选出一台机器作为主机,当原先挂掉的主机回来后,它也会被分配到后面从新分配的主机下面作为从机进行使用。
7.哨兵模式
主从模式的弊端
故障转移要靠手动
没有办法对master进行动态选举,需要使用Sentinel机制完成动态选举
8.哨兵模式的介绍
Sentinel(哨兵)进程是用于监控redis集群中Master主服务器工作的状态
在Master主服务器发生故障的时候,可以实现Master和Slave服务器的切换,保证系统的高可用(HA)
其已经被集成在redis2.6+的版本中
9.哨兵模式的作用
1.监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
2.提醒(Notification):当被监控的某个Redis节点出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作。
10.哨兵的三个定时任务
1.每十秒每个sentinel对master和slave执行info
发现slave
确认主从
2.每两秒每个sentinel通过master节点的channel交换信息(pub/sub)
通过sentinel:hello频道交换
交互对节点的看法和自身信息
3.每一秒每个sentinel对其他sentinel和redis执行ping操作
心跳检测,失败判定依据
11.主观下线和客观下线
主观线下:每个sentinel节点对redis节点失败的偏见
客观下线:所有sentinel节点对redis节点失败达成共识(超过puorum,一般为sentinel个数/2+1)
12.哨兵的工作方式
1.每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
2.如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值,则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)。
3.如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态。
4.当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)。
5.在一般情况下, 每个Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
6.当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
7.若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
13.领导者选举
原因:只有一个sentinel节点完成故障转移
选举:通过sentinel is-master-down-by-addr命令都希望成为领导者
1.每个做主观下线的sentinel节点向其他sentinel节点发送命令,要求将他设为领导者
2.收到命令的sentinel节点如果没有同意通过其他sentinel节点发送命令,那么将同意该请求否则拒绝
3.如果个sentinel节点发现自己的票数超过sentinel集合半数且超过puorum那么将他设为领导者
4.如果此过程有多个节点成为领导者,那么将等待一段时间重新进行选举
14.故障转移
1.从slave节点选出一个合适的节点作为心得master节点
2.对上面的slave节点执行slaveof no one 命令将其成为master节点
3.像剩下的slave节点发送命令,让他们成为新的master节点的slave节点,复制规则和parallel-syncs参数有关
4.更新对原来master节点配置为slave,并保持着对其关注,当其回复后命令他去复制心得master节点
15.选择合适的slave节点
1.选择slave-priority(slave节点优先级)最高的slave节点,如果存在则返回,不存在则继续
2.选择复制偏移量最大的slave节点(复制最完整的),如果存在返回,不存在继续
3.选择runid最小的slave节点

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)