MONGODB性能问题诊断与优化
mongodb目前在业界的使用一般可分为两种架构:主从复制集和分片复制集集群。因为分片复制集包含了主从复制集的功能,所以后面将以分片复制集为案例做说明。伴随数据量的增长和业务压力的增大,经常有接收到mongodb分片集群的性能告警邮件。我所维护的几套分片集群有时一天能收到200来封告警邮件,不胜其烦。告警邮件大致分为三类:1. cpu 负载过高。cpu load average 值超过30,cpu
mongodb目前在业界的使用一般可分为两种架构:主从复制集和分片复制集集群。
因为分片复制集包含了主从复制集的功能,所以后面将以分片复制集为案例做说明。
伴随数据量的增长和业务压力的增大,经常有接收到mongodb分片集群的性能告警邮件。
我所维护的几套分片集群有时一天能收到200来封告警邮件,不胜其烦。告警邮件大致分为三类:
1. cpu 负载过高。cpu load average 值超过30,cpu 使用率超过50%。
2. 空闲内存不足,系统对swap 分区使用超过50%。
3. IO 负载过高。IOwait 超过40%。
性能告警频繁,一线业务人员也不时反馈部分查询业务非常缓慢。有的平时正常情况执行很快的语句也变得非常慢。
以上种种性能问题如何处理呢。如何全面快速的判断出系统系统性能瓶颈,然后给出相应的优化方案,让业务尽快平稳恢复?
通过在实际生产中不断填坑后,总结出以下一些 mongodb性能问题诊断与优化的经验。
首先判断系统资源使用情况。
简单通过 top 命令能够迅速判断出系统目前大致的资源使用情况。
查看系统cpu负载、io负载、内存使用情况等。有时不只是单纯的cpu 或者磁盘io或者内存吃紧一方面,
也有可能cpu、io,或者io、内存同时负载都很高。因此,我们还需要借助性能监控工具做进一步深入分析。
mongodb 性能监控
通过mongostat 工具查看mongodb实例每秒读写数、执行命令、读写等待队列数、活跃读写命令、网络吞吐、连接数等性能指标。
执行命令如下:
生产服务器主库30000端口,从库是30001端口。
/apps/svr/mongodb/bin/mongostat --host 127.0.0.1:30000 -uuser_name -p'password' --authenticationDatabase=admin
具体如下所示:

通过该性能监控工具至少可以了解mongodb实例整体连接数、读写请求数及读写比例(有的业务是读请求比重高,有的业务写请求比重较高)。
需要重点关注 qr|qw 读写等待队列数量。如果该值超过3或者超过cpu 核数,则代表cpu资源比较吃紧,业务请求已经开始积压。
通过 mongotop 查看mongodb 实例中热点表读写情况。
执行命令如下:
/apps/svr/mongodb/bin/mongotop --port 30000 -uuser_name -p'password' --authenticationDatabase=admin
该监控工具将按照请求时间从大到小进行排序的前10个表的请求消耗时间打印出来。
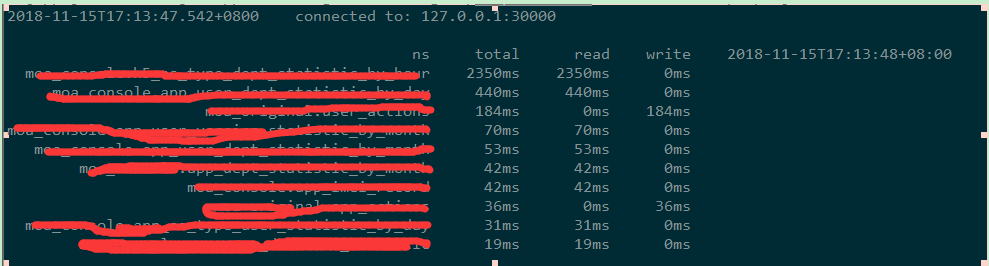
根据 二八定理,我们可以选择对于占用请求时间超过80%的热表慢查询进行针对性的性能分析和优化。
查看当前mongodb实例具体执行的慢查询请求。
例如,通过以下命令查看msg库当前大于3秒的慢查询。
db.currentOp({"active" : true,"secs_running" : { "$gt" : 3 },"ns" : /^msg/})
对于聚合分析请求较多业务库,往往不时有超过100秒的聚合分析语句正在执行。导致CPU和IO资源非常紧张。这时为了不影响正常业务的进行,只能暂时选择将很多堆积的慢查询语句先杀掉。
具体可以执行db.killOp("opid") 。opid为慢查询的唯一标识。
关于业务库慢SQL的查询与批量kill功能已经在数据库管理平台雅典娜添加了。这里不再详细说明。
以上两步我们都是实时监控mongodb实例负载详情。如果当我们开始处着手处理性能问题的时候系统负载已经恢复正常了,这该怎么办呢?这时就要借助zabbix 中记录的性能图进行分析了。
刚好最近处理了一个美信消息收发的mongodb集群的性能问题。
我完整的讲一下问题处理流程。
1. 首先,收到不少mongodb服务器cpu load 值很高的性能告警消息。业务那边也反馈美信消息收发很慢,甚至很多消息都发不出去。
着手进行mongodb问题排查时,系统负载又迅速掉下来。之前几天早上也陆续出现几次类似的问题,但是没有如此严重。
2. 查看zabbix 中 cpu 性能图。cpu load 值最高飙升到250。而且是从8:47到9:00这短短十几分钟就飙升上去了。持续不到10分钟cpu load 又开始急剧下降。
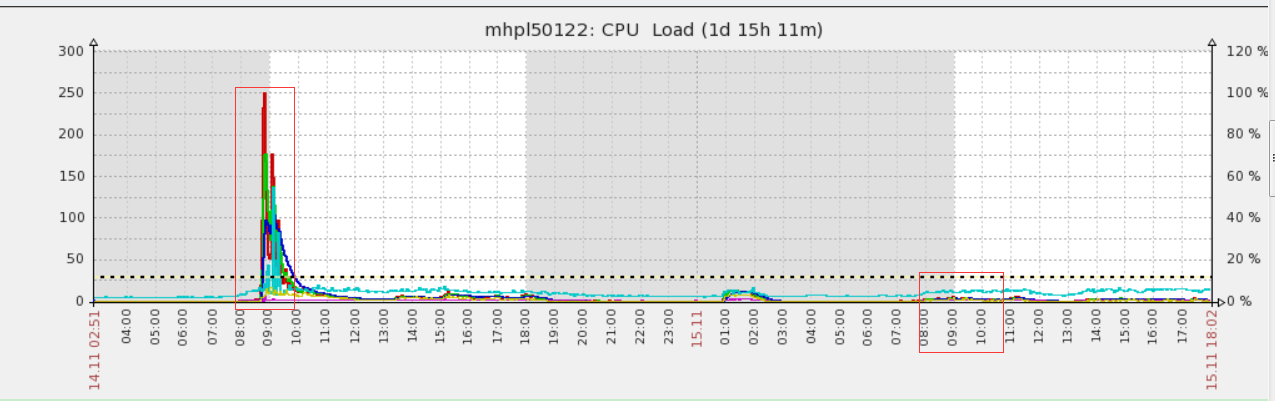
cpu load 为什么飙升这么高呢,依据经验判断。如果是长连接的慢查询。cpu 使用率和load值增长和下降应该相对平稳,没有如此急剧。
另外注意到的是,cpu资源剧增的时候,io和内存使用率比较低。因此猜测是高并发的短平快请求数导致的cpu压力骤升。
同时也注意到,该分片集群单单是这个节点cpu负载格外高,其他两个节点服务器比较正常。
为了分析告警服务器在异常期间究竟执行了什么任务,选择用mtool工具对mongodb主节点实例进行详细的慢查询分析。
mlogfilter 默认慢查询时间是1000ms,因为前面分析可能是短平快请求较多,所以这里设置慢查询时间为300ms。
mlogfilter mongod30000.log --from '2018-11-14 08:45:01' --to '2018-11-14 09:10:00' --slow 300 > /tmp/msg31.log
查看慢查询详情并按照时间消耗进行分类
mloginfo /tmp/msg31.log --queries --sort sum
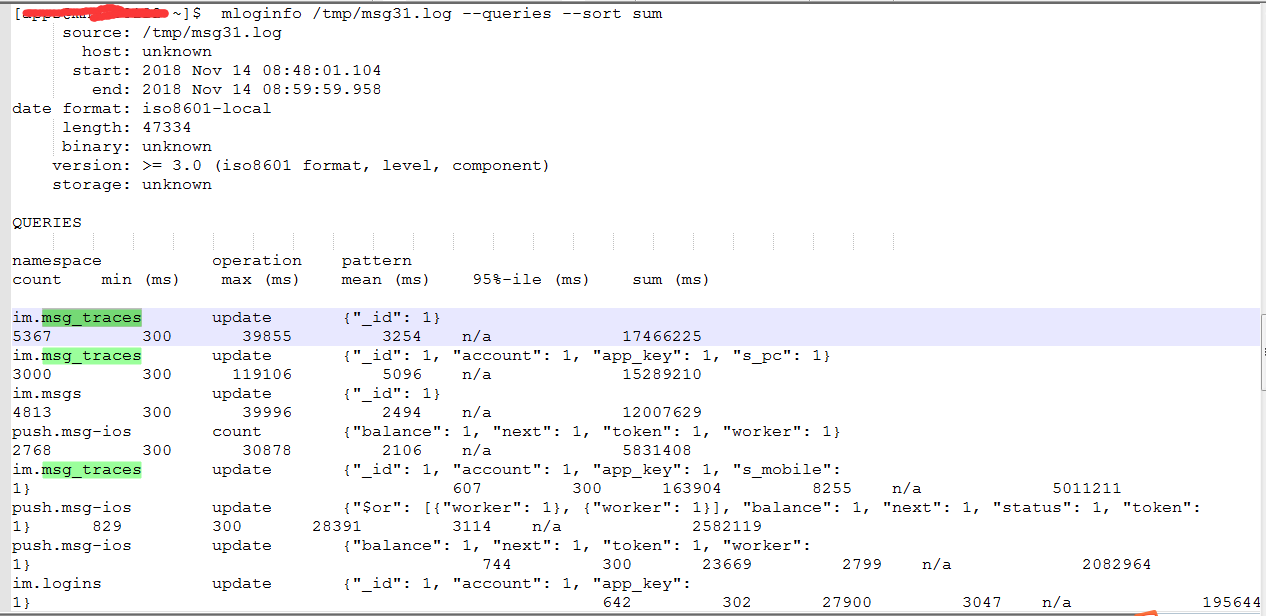
如上图所示,慢查询响应时间排名前八的全是update 写入操作。一些根据 _id 进行update,以及 msg-ios(8条记录)小表的update操作都非常慢,平均执行时间达到2~3秒。
正常情况下,这两种语句执行时间都在100毫秒左右。因为写操作过于频繁,cpu load 值太高,正常的请求都被阻塞住。数据库整体响应都变得很慢。
mongodb 集群数据分布详情和分片键设置
该分片集群只是分片1节点cpu 负载特别高,因此初步怀疑热点表 im.msg_traces 分片数据分布也很不均匀,热点数据集中在分片1上。查看了一下热表msg_traces 和 msg 的分片数据分布和分片键。都是以 _id 为hash 分片键,数据分布比较均匀。
这就有点困惑,三台物理机,唯独这台cpu load 格外高,数据盘 io %util 值也维持在90%左右。对比一下该节点与另外两台物理机的配置。发现型号和配置不一样。通过与虚拟机化那边同事确认。问题节点物理机IO吞吐比其他两台物理机确实要差一倍以上。
再次分析分片1节点的慢查询日志。如下图所示,发现热表 msg_traces 上不少慢查询语句。
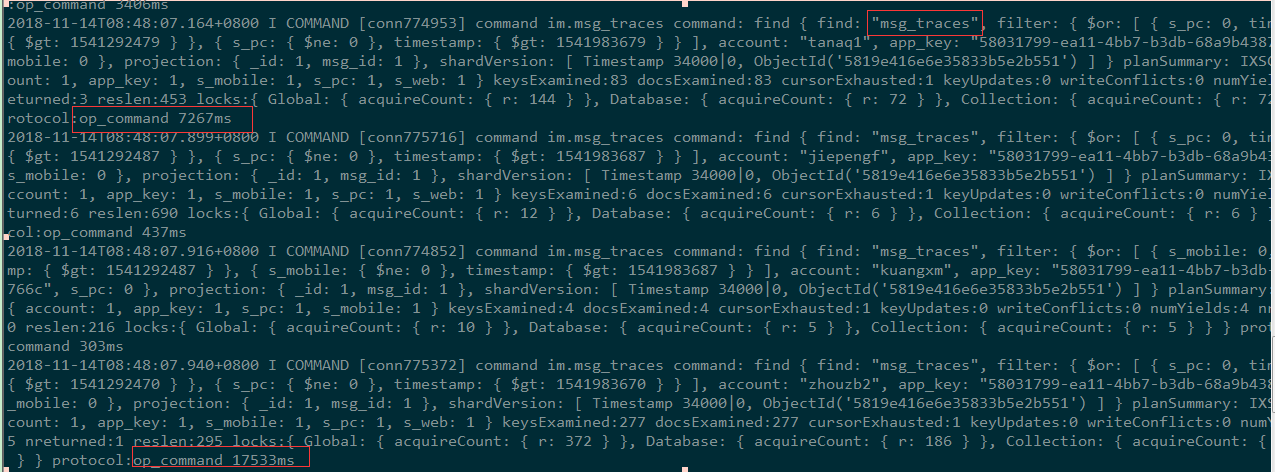
经过与开发同事沟通,热表 msg_traces、msg 上的查询和高并发update 语句都和公司美信消息推送、查看、消息状态修改等核心业务相关。业务上很难进行优化。因此,考虑主要从以下四个方面进行 cpu/io 方面的优化处理:
1.集群架构上进行读写分离。所有查询优先考虑在从库上读取,写操作在主库上执行。避免主库混合读写压力过大,也减少主库上读写记录的锁冲突。
connection string中readPreference 设置成secondarypreferred,C++ 驱动版本升级为3.1.3 mongo-cxx-driver(驱动升级,读写分离才生效) 。
2.热表msg_traces 索引优化
针对该慢查询创建联合索引 {"_id": 1, "account": 1, "app_key": 1, "s_pc": 1}。
3.mongodb 历史数据归档和删除
和开发同事沟通,根据实际业务需求,保留msgs、msg_traces 集合中一年左右的文档。在timestamp 字段上创建TTL索引。设置文档的过期时间为 3153600秒(365*24*3600)。
db.msgs.createIndex( { "timestamp ": 1 }, { expireAfterSeconds: 3153600 },{background: true} )
db.msg_traces.createIndex( { "timestamp ": 1 }, { expireAfterSeconds: 3153600 },{background: true} )
mongodb TTL索引将每隔60秒对过期数据执行一次删除操作。删除操作的持续实际取决于mongod 实例的负载。
4 .journal 日志的 commitIntervalMs 参数调整。
从默认的100ms调大到500ms。
目前通过读写分离和索引优化之后,原来分片1在业务高峰期间的cpu load 值由最高值250降低到5以内,优化效果非常明显。
mongodb 分片集群优化思路总结:
分片集群中出现某个分片负载特别高的情况。(往往是某个分片负载高,如果是多个分片节点负载都高,则需要逐个进行分析)
第一步:
首先通过top、iostat、vmstat、mongostat 等工具了解系统大致并发负载和读写比例,观察系统具体瓶颈所在。
第二步:
如果负载只是集中出现在某一个节点上,则通过 mongotop 工具先分析该mongodb实例的热点表是哪些并记录下来。
第三步:
通过 mlogfilter / mloginfo 工具分析业务高峰期间出现的TOP10 慢查询。
第四步:
定位需要优化的目标表,并进行查询优化。
通常第二步和第三步会出现很多相同的表。因为热点数据表和慢查询表往往存在相同的一些表。这些表就是我们需要优化的目标。
mongodb 分片表的优化大致从以下几方面着手:
1.查看表分片键、数据分布、数据总量、数据占用空间等信息。着重看数据分片键设置是否合理、数据分布是否均匀;
2.mloginfo 工具打印出来的慢查询信息中有每个慢查询的查询条件。确认慢查询表上是否有合适的索引满足查询条件执行。需要结合explain() 分析慢查询的具体执行计划。
3.选取业务高峰阶段的mongodb实例原始日志,搜索慢查询表相关的原始查询语句。记录这些原始查询语句,方便后续与开发同事沟通,看能否从业务场景上进行相应的优化。
4.对于日志、事件、会话信息等日志类型的表,可以按照业务需求,根据事件字段,只保留一定时间内的有效数据。通常这要与开发业务
沟通清楚。确认保留时间后,可以利用mongodb TTL索引特性,在特定时间字段上创建索引,设置记录过期时限。
第五步:
架构上做读写分离优化
如果在第三步找出来的 TOP10 慢查询不少是能有效利用索引的简单查询,正常情况下,执行应该很快(200ms之内)。
则需要考虑在架构上做读写分离的优化。因为热点表高并发的读写会让cpu 忙不过来,导致原本正常的查询都出现阻塞。
总之,mongodb 优化关键之处是找出系统瓶颈和问题根源。定位出需要优化的目标表后,简单地加个索引或者做个读写分离,性能问题往往就迎刃而解。
这个和医生看病颇为相似,通过望闻问切和各种医疗检验设备所反馈的数据和报告,再依据丰富的临床经验诊断出病因所在。找出病因后,开什么方子用什么药就是水到渠成的事了。当然,医生看病比给数据库做性能诊断复杂多了,误诊几率也不小。而且,数据库性能优化没找准原因还有不少试错的机会,但是医生试错成本就比较高了。所以当个好医生貌似比做个好DBA更难!
以上插了些题外话。优化上过程中,也需要和开发同事保持有效沟通。当我们理解慢查询产生的业务场景后,有时让开发同事配合做个简单的功能优化,头痛的性能问题也能随之解决。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)