ElasticSearch之ngram分词器
一、什么是NGram 分词器?edge_ngram和ngram是ElasticSearch自带的两个分词器,一般设置索引映射的时候都会用到,设置完步长之后,就可以直接给解析器analyzer的tokenizer赋值使用。
一、什么是NGram 分词器?
edge_ngram和ngram是ElasticSearch自带的两个分词器,一般设置索引映射的时候都会用到,设置完步长之后,就可以直接给解析器analyzer的tokenizer赋值使用。
二、怎么使用
完整的索引结构:
{
"settings": {
"index.max_ngram_diff": 10,
"number_of_shards": 128,
"number_of_replicas": 2,
"refresh_interval": "5s",
"blocks": {
"read_only_allow_delete": "false"
},
"analysis": {
"analyzer": {
"ngram_analyzer" : {
"tokenizer" : "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "1",
"type" : "ngram",
"max_gram" : "10"
}
}
}
},
"mappings" : {
"_routing" : {
"required" : true
},
"properties" : {
"id" : {
"type" : "long"
},
"username" : {
"type" : "text",
"fields" : {
"ngram" : {
"type" : "text",
"analyzer" : "ngram_analyzer"
}
}
},
"password" : {
"type" : "long"
},
"createTime" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"
}
}
}
}
大概就是在setting中引入分词器,ngram_tokenizer里设置类型type为edge_ngram或者ngram,然后mapping中需要作ngram分词的字段指定一下就可以了。需要注意的是es7以后的版本min_gram和max_gram的粒度默认是不大于1,也就是说分词是一个字符一个字符逐个分的。如果粒度需要大于1需要设置一下index.max_ngram_diff大于等于它们的差值,否则会报错。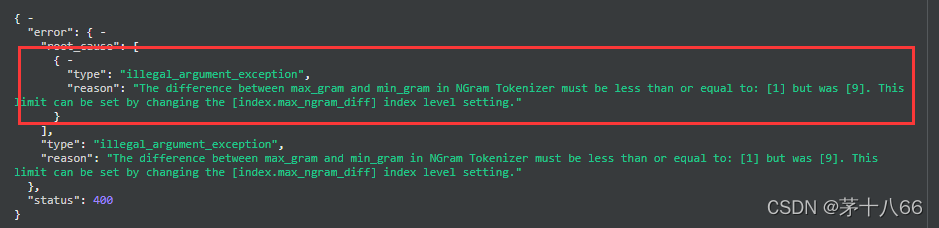
分词粒度的效果,例:搜索我是中国人
分词粒度为默认1,以ngram分词器分词,则分词效果为
我 是 中 国 人
分词粒度为默认3,以ngram分词器分词,则分词效果为
我 我是 我是中 是 是中 是中国 中 中国 中国人 国 国人 人
三、ngram和edge_ngram类型两者的区别
edge_ngram分词效果
ngram分词效果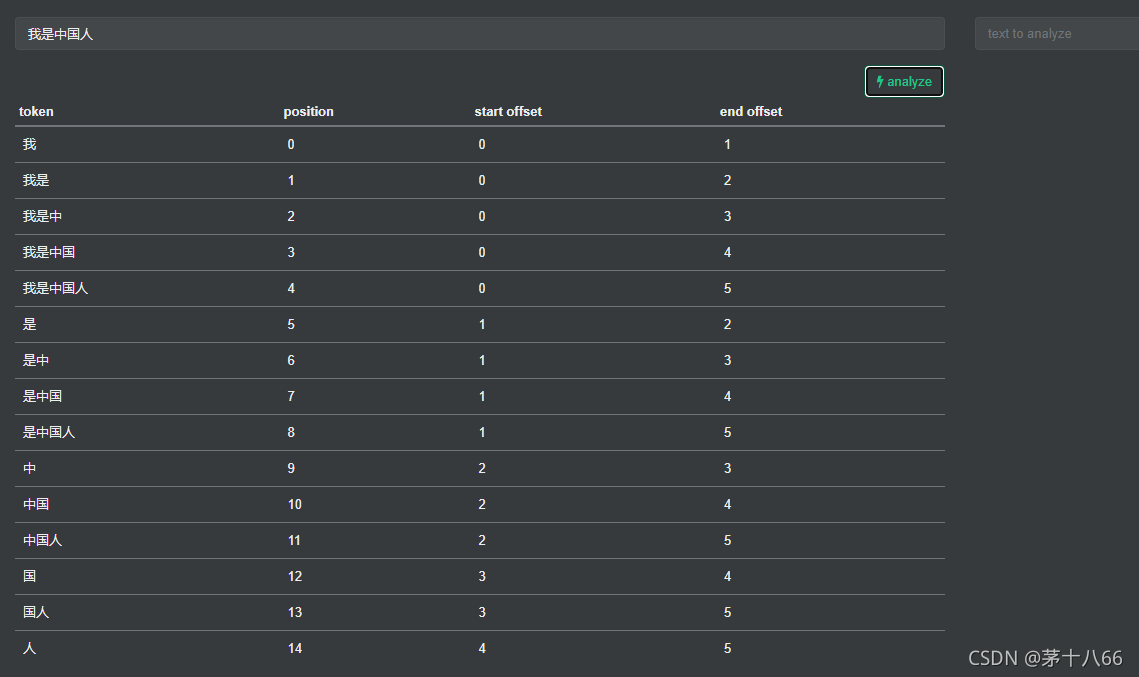
总结:
主要区别在于edge_ngram会按照首字符逐字匹配,ngram是全字符逐个匹配,比如分词粒度都是3的两个分词器,搜索我是中国人:
edge_ngram分词
我 我是 我是中 (edge_ngram分词必须以首字 ”我“ 开头逐个按步长,逐字符分词)
ngram分词
我 我是 我是中 是 是中 是中国 中 中国 中国人 国 国人 人(ngram分词逐字开始按步长,逐字符分词)

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)