在java代码中使用kafka(springboot整合kafka)
java代码maven项目实现kafka的连接及生产者、消费者的创建,以及消息的发布和订阅
·
首先,项目是个springboot-maven项目。(使用quickstart就可以)。
引入maven依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>如果是普通maven项目,也可以用这个依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.0</version>
</dependency>接下来,在bootstrap.yaml中添加连接kafka的配置:
spring:
kafka:
bootstrap-servers: 192.168.76.4:9092
producer: # 生产者
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
# RECORD
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
# BATCH
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
# TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
# COUNT
# TIME | COUNT 有一个条件满足时提交
# COUNT_TIME
# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
# MANUAL
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: manual_immediate也可以不在bootstrap.yaml中配置,使用配置类进行配置:
private KafkaProducetest() {
Properties props = new Properties();
//此处配置的是kafka的端口
props.put("metadata.broker.list", "192.168.76.4:9092");
//配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
//配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder");
//0表示不确认主服务器是否收到消息,马上返回,低延迟但最弱的持久性,数据可能会丢失
//1表示确认主服务器收到消息后才返回,持久性稍强,可是如果主服务器死掉,从服务器数据尚未同步,数据可能会丢失
//-1表示确认所有服务器都收到数据,完美!
props.put("request.required.acks", "-1");
//异步生产,批量存入缓存后再发到服务器去
props.put("producer.type", "async");
//填充配置,初始化生产者
producer = new Producer<String, String>(new ProducerConfig(props));
}附上一些kafka的主要配置信息及默认值,仅供参考,按需使用。
broker的配置
| name | 默认值 | 描述 |
| brokerid | none | 每一个boker都有一个唯一的id作为它们的名字。 这就允许boker切换到别的主机/端口上, consumer依然知道 |
| enable.zookeeper | TRUE | 允许注册到zookeeper |
| log.flush.interval.messages | Long.MaxValue | 在数据被写入到硬盘和消费者可用前最大累积的消息的数量 |
| log.flush.interval.ms | Long.MaxValue | 在数据被写入到硬盘前的最大时间 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 检查数据是否要写入到硬盘的时间间隔。 |
| log.retention.hours | 168 | 控制一个log保留多长个小时 |
| log.retention.bytes | -1 | 控制log文件最大尺寸 |
| log.cleaner.enable | FALSE | 是否log cleaning |
| log.cleanup.policy | delete | delete还是compat. 其它控制参数还包括log.cleaner.threads,log.cleaner.io.max.bytes.per.second,log.cleaner.dedupe.buffer.size,log.cleaner.io.buffer.size,log.cleaner.io.buffer.load.factor,log.cleaner.backoff.ms,log.cleaner.min.cleanable.ratio,log.cleaner.delete.retention.ms |
| log.dir | /tmp/kafka-logs | 指定log文件的根目录 |
| log.segment.bytes | 1024*1024 | 单一的log segment文件大小 |
| log.roll.hours | 24 * 7 | 开始一个新的log文件片段的最大时间 |
| message.max.bytes | 1000000 + MessageSet.LogOverhead | 一个socket 请求的最大字节数 |
| num.network.threads | 3 | 处理网络请求的线程数 |
| num.io.threads | 8 | 处理IO的线程数 |
| background.threads | 10 | 后台线程序 |
| num.partitions | 1 | 默认分区数 |
| socket.send.buffer.bytes | 102400 | socket SO_SNDBUFF参数 |
| socket.receive.buffer.bytes | 102400 | socket SO_RCVBUFF参数 |
| zookeeper.connect | localhost:2182/kafka | 指定zookeeper连接字符串, 格式如hostname:port/chroot。chroot是一个namespace |
consumer的配置
| name | 默认值 | 描述 |
| groupid | groupid | 一个字符串用来指示一组consumer所在的组 |
| socket.timeout.ms | 30000 | socket超时时间 |
| socket.buffersize | 64*1024 | socket receive buffer |
| fetch.size | 300 * 1024 | 控制在一个请求中获取的消息的字节数。 这个参数在0.8.x中由fetch.message.max.bytes,fetch.min.bytes取代 |
| backoff.increment.ms | 1000 | 这个参数避免在没有新数据的情况下重复频繁的拉数据。 如果拉到空数据,则多推后这个时间 |
| queued.max.message.chunks | 2 | high level consumer内部缓存拉回来的消息到一个队列中。 这个值控制这个队列的大小 |
| autocommit.enable | TRUE | 如果true,consumer定期地往zookeeper写入每个分区的offset |
| auto.commit.interval.ms | 10000 | 往zookeeper上写offset的频率 |
| auto.offset.reset | smallnest | 如果offset出了返回,则 smallest : 自动设置reset到最小的offset. largest : 自动设置offset到最大的offset. anything else : 否则抛出异常. |
| consumer.timeout.ms | -1 | 默认-1,consumer在没有新消息时无限期的block。如果设置一个正值, 一个超时异常会抛出 |
| rebalance.retries.max | 4 | rebalance时的最大尝试次数 |
producer的配置
| name | 默认值 | 描述 |
| serializer.class | kafka.serializer.DefaultEncoder | 必须实现kafka.serializer.Encoder 接口,将T类型的对象encode成kafka message |
| key.serializer.class | serializer.class | key对象的serializer类 |
| partitioner.class | kafka.producer.DefaultPartitioner | 必须实现kafka.producer.Partitioner ,根据Key提供一个分区策略 |
| producer.type | sync | 指定消息发送是同步还是异步。异步asyc成批发送用kafka.producer.AyncProducer, 同步sync用kafka.producer.SyncProducer |
| metadata.broker.list | boker list | 使用这个参数传入boker和分区的静态信息,如host1:port1,host2:port2, 这个可以是全部boker的一部分 |
| compression.codec | NoCompressionCodec | 消息压缩,默认不压缩 |
| compressed.topics | null | 在设置了压缩的情况下,可以指定特定的topic压缩,为指定则全部压缩 |
| message.send.max.retries | 3 | 消息发送最大尝试次数 |
| retry.backoff.ms | 300 | 每次尝试增加的额外的间隔时间 |
| topic.metadata.refresh.interval.ms | 600000 | 定期的获取元数据的时间。当分区丢失,leader不可用时producer也会主动获取元数据,如果为0,则每次发送完消息就获取元数据,不推荐。如果为负值,则只有在失败的情况下获取元数据。 |
| queue.buffering.max.ms | 5000 | 在producer queue的缓存的数据最大时间,仅仅for asyc |
| queue.buffering.max.message | 10000 | producer 缓存的消息的最大数量,仅仅for asyc |
| queue.enqueue.timeout.ms | -1 | 0当queue满时丢掉,负值是queue满时block,正值是queue满时block相应的时间,仅仅for asyc |
| batch.num.messages | 200 | 一批消息的数量,仅仅for asyc |
有了配置之后,就可以开始写生产者代码:
@Autowired
//引入kafka的template
private KafkaTemplate<String,String> kafkaTemplate;
//如果是配置类,就注入配置类就可以
//在controller中直接进行消息的发布(为了简便,不建议)
@GetMapping("/kafka")
public boolean kafka(@RequestParam("msg") String msg){
kafkaTemplate.send("test", msg);
return true;
}在linux命令行输入如下指令即可打开消费者控制台,查看消息:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test启动服务,调用接口发布消息:

在linux界面接收到,说明连接成功。

在服务器本地可以使用命令行参数连接并且进行发布订阅操作,但是使用spring boot连接服务器时可能会有如下错误:
Connection to node 1 (localhost/127.0.0.1:9092) could not be established. Broker may not be available
这个时候,停掉kafka,打开kafka的配置文件(server.properties),修改以下两个地方,默认第二个红框的内容是注释掉的,这样的话虚拟机之外的是访问不进来的,只需要将注释放开,改成自己的ip:端口即可。
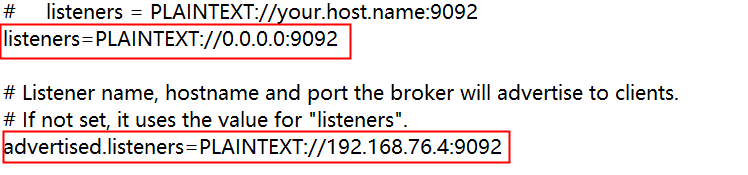
接下来,咱们完成一下消费者代码:
@Component
public class Consumer {
/**
* @param record ack
* @KafkaListener(topics = "",groupId = "")
* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),
* @TopicPartition(topic = "topic2", partitions = "0",
* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
* },concurrency = "6")
* //concurrency就是同组下的消费者个数,就是并发消费数,必须小于等于分区总数
*/
//因为在配置中已经指令了groupId,故无需再次指定,可以根据自己的需求增加属性
@KafkaListener(topics = "test")
public void consumer1(ConsumerRecord<String,String> record, Acknowledgment ack){
//简单打印一下收到的消息
System.out.println(record);
//手动提交offset,一般是提交一个banch,幂等性防止重复消息
ack.acknowledge();
}
} 
消息消费成功。
ConsumerRecord(topic = test, partition = 0, leaderEpoch = 0, offset = 17, CreateTime = 1662430642575, serialized key size = -1, serialized value size = 5, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = kafka)
至此,生产者和消费者的简单代码完成,当然了,现实可能会遇到更多复杂的生产和消费的问题,这个就需要自己去探索了~

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)