ES千亿级数据检索实战-搜索优化建议
本篇文章,提供Es搜索优化的思路,优化方向,不做过多的细节赘述。目前负责千亿级别的索引的搜索优化。以下内容,是我个人做es搜索的经验。这些内容是官网上看不到的东西。
本篇文章,提供优化的思路,优化方向,不做过多的细节赘述。
目前负责千亿级别的索引的搜索优化。以下内容,是我个人做es搜索的经验。
优化方向
- 业务上合理使用集群。百分之八十的问题都是业务上使用不当造成的。
- 好的集群规划,充分的资源,是es起飞的第一步。
- 大家的使用es的场景都不一样。有的用到聚合、有的用到精准搜索、有的用到相关性搜索。每个场景都有不同的优化思路。扣细节,是优化的主要方向。每一个小的细节都可能有几倍的提升。
- 优化架构,尽可能的去对集群做减法,如何减少数据。例如只拿es做分析和索引。不存储实际的数据,配合Hbase的思路。
- 优化的宇宙尽头是砍需求。降低集群的压力。减少百分之二十的压力,可能带来百分之三十甚至更多的提升!
整体ES优化思路
先说说优化的方向,这些内容我自己在做千亿级别的搜索优化的时候,琢磨了好久,我的观点是网上没有的。
-
分布式讲究的合力解决问题。所以应该注意短板问题。
-
es 想要快,核心思想是减小搜索的集合,以及减少搜索命中的结果集,每个子查询都是关键点。
-
非并发解决的问题,是应该重点关注的问题。es默认机制里边有一些是串行的!
-
提前结束请求。不要扫全表,和避免对全量数据做排序之类的处理。数据规模越大,效果越好。
-
清楚集群关注的点是读还是写。因为他们的参数调优是互相影响的!鱼和熊掌不可兼得。
-
清晰的角色划分很重要。
-
合理的集群资源规划。
-
尽可能的将实时计算的过程,前置到数据入库之前,减少计算来提升检索性能。
-
机器不够架构来凑!架构设计上的优化
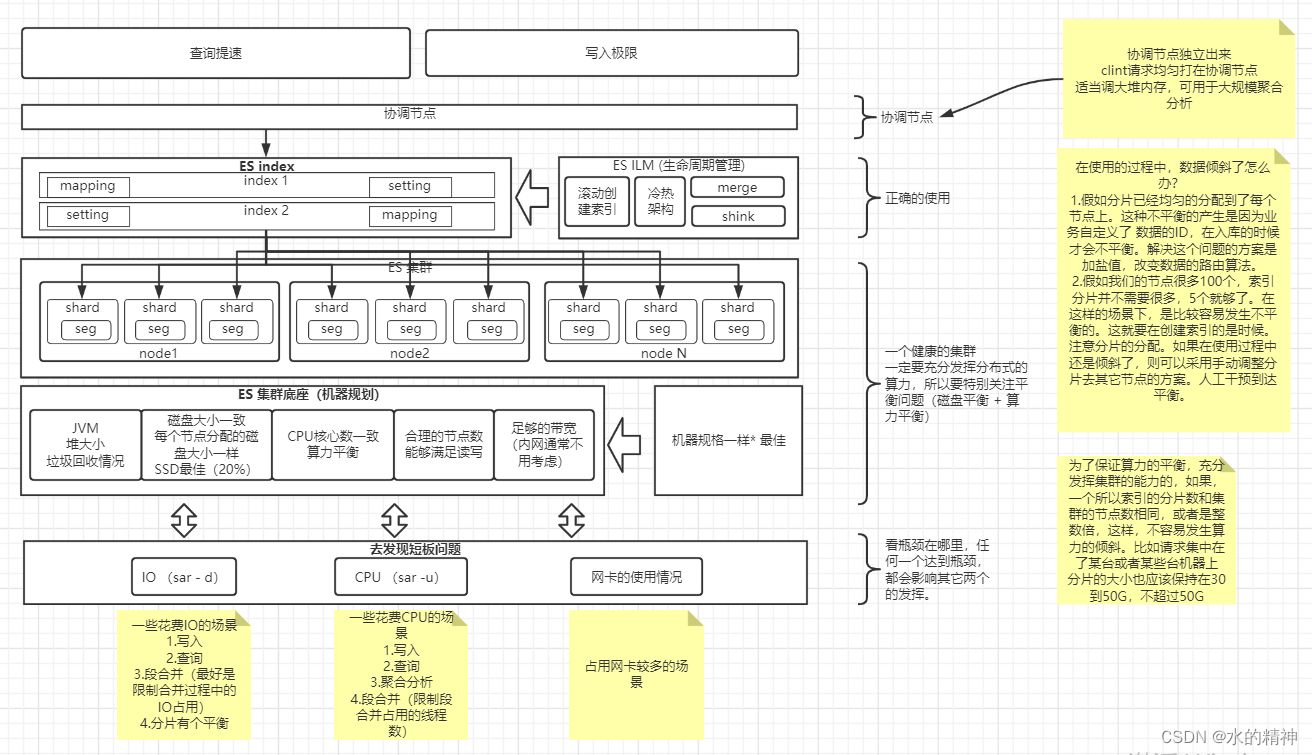
问题一:关于分布式中的短板问题
es虽然能够支持千亿级别的高效检索,但是es也是一个非常娇贵的东西。马之千里者,一食或尽粟一石。食不饱,力不足,才美不外见。es的确是一匹千里马,但是它真的要吃很多东西。它需要充足的资源(后边我会说es的资源规划,怎么才算资源吃饱),它要使用者对它的各种原理都熟悉,要熟悉ES的源码,熟悉JVM,熟悉linux。
es是一个天然的分布式搜索引擎。分布式中的短板问题,是致命的!这里我举个栗子,如果有10台机器(每台机器1个节点)。假如你的数据分布在10台机器上,假如有一台机器生病了,出现了例如IO、网络、CPU的瓶颈问题。那么你的一次搜索,一定是慢的,分布式计算中。性能的上限取决于每个节点的下限在哪里。比如说一个请求,其它节点上的分片都花费了的1s处理请求。但是某台机器的分片处理的5s,那么你的总体请求时间一定会大于5s。所以找出来一次检索中存在的短板问题,找出来分布式中的短板问题,可以有效提升es的检索性能。
那如何去分析一次请求中的短板问题呢
我这里放一个官网的链接,参考官网。(ps 个人不建议去看网上零碎的文章,直接看官网一手的资料是最好的!不走弯路,节省时间)
Profile API | Elasticsearch Guide [8.4] | Elastic
同样,我们也要把机器资源花费的更加充分一点。避免资源浪费,在特大规模的集群中,一点点的浪费,可能会到百万,千万每年!这里重点关注 IO、网络、CPU(关于CPU,我下边给出建议)。
再说一些es中为什么会出现短板问题。这要从es的底层原理说起,es最大级别的资源是集群,集群是由节点组成的;节点分布在一台一台的机器上;节点里边包含了N个分片;一个分片是一个lucene实例,lucene是真正处理数据的部分,不属于es,可以自行了解;分片中,是有一个一个的段组成的,前边说过es的写入是用到了日志合并树的概念,数据写入先到堆内存的index buffer中,攒一波,然后写到文件存储系统上,然后再落到磁盘上。所以检索的最小单元是段。这里要注意,对es来说,es一次检索,资源分配的最小单元是分片。因为请求会给每个分片分配一个线程。
想让你的请求处理的快,假如你的请求命中五个分片,最好能给它五个线程去每个分片上处理查询。如果分配不到,该请求就发生了排队。该问题在下边的资源规划上边再讨论。
问题二:尽可能的缩小搜索集合,以及命中的结果集
在资源有限的情况下,我们应该把我们请求,以及数据都控制在有限的范围内。这个问题就好比一辆车,它能拉100个人,以每小时 100Km的速度跑。假如你硬要上150个人,可能也能跑,但是速度肯定就要降下来了。
我们要尽可能的去减少结果集。对应es来说,我们要从数据层面去架构设计。去达到一次搜索缩小搜索范围的目的。比如,我们存了一年的订单数据,一共有1200亿,假如让你搜出来某天的数据,你要去这1200亿中去找数据。如果你把数据做一个拆分,每个月一个索引,那么你只需要在100亿数据中寻找你想要的数据。如果你按天去创建索引,那你只需要从5亿数据中去寻找你想要的数据。当然了按时间去做拆分,是一种策略。可以举一反三,做设计,去分割索引。让单个索引尽可能的数据少。
这里举一个例子:假如我们使用ILM,来管理索引。运行了几个月后,一共有10个索引。假如我们要滚动导出数据。我们可以对每个索引进行滚动导出,而不是对一个别名同是对10个索引进行导出。它们花费的资源是非常不一样的。
在大索引(分片数非常多)的情况下,要控制单个请求取回的数据。size最好不要超过1000,甚至更小。同是更应该注意from的值,尽可能也控制在1000以内。否则是一件非常危险的事情。它会非常的花费堆资源。
问题三:尽可能的让请求是并发执行的
es设计者从安全的角度出发,单个请求,在一个节点上命中的索引,最多可以有五个分片去同时执行。假如一个搜索,命中了100个分片,其中某个节点包含了20个分片,根据上边说的排队机制。在该节点上,每5个分片可以执行一次。所以要排队四次,才能全部处理完。这个时候就一定出现了短板问题,因为这一个节点上的请求没有执行完,那么最终的数据处理就不算完成。当然这个可以通过参数 max_concurrent_shard_requests 来提高并度。
可以看看我下边这篇文章的测试报告
ES在超多分片搜索场景下提升N倍 - 优化_水的精神的博客-CSDN博客
当然了,假如你的集群资源很充足,就不会有这样的问题。你有100个节点,你的一个索引有500个分片,如果能均匀的分布在100个节点上,实际上分配到每个节点上也只有5个分片,并不存在排队的问题。
问题四:特大规模中的检索中,提前终止请求。避免扫全表。
提前结束请求,是一个很好的思路。它依赖提前对数据做一份处理。比如我们有1000条数据,你按照重要性做好排序。当用户想要看10条数据的时候,你只需要取出来前十条,就结束请求。不去扫1000条数据。这样你的检索速度,不会因为数据变多,而查询越来越慢。
问题五:鱼和熊掌不可兼得。读极限和写极限,是有冲突的
我们通常会做写入优化以及查询优化。通常来说,大量的写入,会消耗较多的资源。此时不可能达到查询的极限。另外一些参数调优,两者也是有冲突的。例如,数据写入会占用10%的堆空间来暂存写入的数据,等数据写满了,才会落到文件存储系统上。为了写极限,我们是可以调大index buffer大小的,突破10%,可能会有更好的写入效果。但是在堆空间不足的情况下,多分10%给写,那么查询可利用的堆就没有那么多了。
边写边读,二者有冲突。写入可能会导致缓存失效,例如聚合分析的全局序数,你不断的写入,在聚合分析的时候需要重建全局序数,这会导致查询变慢。
问题六:好的角色划分
默认情况下,es 的每个节点都可以充当master节点,data节点,协调节点等。它们的工作截然不同,它们花费的资源也不一样。建议将它们分开,master是用来维护集群信息的,相当于是司令,但是司令通常不会直接上战场打仗。在小规模集群下,它不会花费太多的资源。data节点,之真正的执行数据读写的节点,它要花费内存,花费CPU,大量占用IO。协调节点只用来转发请求。它占用内存,少量CPU,以及较多的网络传输,因为分布式请求结果最后在这个节点上汇总,每个数据节点处理的结果都要传输到该节点上,最终将结果返回给客户端。
建议将master节点单出出来。相当于是把司令放在安全的地方。防止司令挂了,全军溃败。协调节点它要花费内存,也就是堆空间,特别是在大规模集群上,一次结果合并,也是非常花费堆空间的操作。它可能会和数据节点抢占资源。所以协调节点也要单独出来。如果集群涉及到了跨集群的查询,那么会有一个角色,叫做远程节点。可以把该节点和协调节点放一起,但是不要和数据节点放一起。
以上问题,均在大规模的场景下考虑。假如你三个节点,一共几千万数据,完全不用拆分。拆分以后有可能反而更浪费资源。
问题七:合理的集群资源规划
关于资源规划问题,比较复杂,要根据时期情况来评估。
仍然从写入和读取的两个角度来评估。
假如你想要保证绝佳的检索性能。我认为最佳的配置是这样的:我这里不以数据条数来计算,我以实际的存储量大小来评估。因为条数没有任何的计算价值。大家都不一样。但是存储大小是有所说法的。根据每个分片30G-50G大小,我们按照40G来算,假如你每天写入的数据量是1000个G,那么对应的分片数应该是:1000除以40 等于25个分片。如果你的数据只检索一周,那么 25 * 7 = 175个分片,也就是说一次搜索要在175个分片上进行,es默认每次请求,单个节点只能有5个分片同时执行。 175 除以 5 = 35 个节点。这里我们想要保证es集群不拉垮,给到35个数据节点。效果是最佳的!再配上一个master节点,以及4个协调节点,也就是一共40个节点。
然后从写入的角度,以及集群长期运行稳定度上去考虑。还是按照每天写入1000G数据。每天25个分片,那么25个节点就差不多了。每个节点去分配一个分片,是俱佳的效果。因为要考虑到分片分布平衡的问题。按照上边的读极限的评估,我们需要给到35个节点。但是从写的角度来看,并不需要那么多。此时看怎么考虑。如果有钱,就买35个节点,让读取达到最佳。如果没钱,那么至少也要25个数据节点了。此时查询会存在排队行为。我们可以通过上边说的改并发限制的参数,来提升单次检索的性能。但是此时要要注意,我们的堆空间可能就有比较大的压力了!需要每秒并发的请求数降下来。
再说磁盘问题。依旧是根据写入的量来评估我们需要多少磁盘空间。假如每天写入1000G,那么就是25个分片。加上副本,则需要50个分片。那么磁盘空间就需要2000G。假如我们的数最多保留三个月,那就需要 2000G * 93day / 0.8 = 227T磁盘空间。除以0.8的意义在于,es磁盘80%是一个水位线,此后,要去做分片平衡了。另外,有钱就上SSD固态硬盘,这是不用动脑子就能买来的提升,提升在百分只而是以上。
再说CPU问题。核心数能给多就多给。单个节点最少给16个核心吧。从生产经验来说,我见过的都是给40个核心。当然了这个要根据我们实际上请求的并发情况来定。如果要求低延迟,增加核心数,可以有不错的环节效果。减少请求在队列中排队的可能性。
网络问题,通常都是内网,不会有压力,不讨论。除非是特别苛刻的环境。
一个健康的集群应该是:
问题八:将计算前置到入库之前
这句话的意思是,如果可以的话,把一些非必须的实时计算的部分,放到入库之前。例如你要根据脚本,计算一片文章的重要程度。这样的需求就可以放在入库前,先计算好重要性,然后在检索的时候,只需要根据重要性分数做排序,而不需要再计算每条数据的分数。
最好不要使用script脚本做搜索!
假如你搜搜对相关性要求不可以将请求改为filter,节省了先关性分数的计算过程,可以有很好的提升效果。
问题九:架构设计上的优化

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)